
Ingeniería de características temporales: guía básica
Las características temporales permiten transformar datos con marcas de tiempo en variables útiles para entender patrones de comportamiento, como la hora, el día o la frecuencia de eventos. Este enfoque es clave para detectar fraudes en transacciones, ya que identifica actividades inusuales comparando el comportamiento actual con el histórico. Por ejemplo, transacciones en ráfagas cortas o a horarios atípicos pueden ser señales de alerta.
Puntos clave:
- Tipos de características: Recencia, frecuencia, sesión, tiempo de permanencia y datos basados en calendario.
- Preparación de datos: Usar UTC, ajustar a zonas horarias locales (como ART en Argentina) y evitar fugas de información.
- Casos locales: Eventos como Hot Sale y CyberMonday generan patrones específicos que deben analizarse para evitar falsos positivos.
- Ejemplo real: En 2024, un estudio en México mejoró la detección de fraudes integrando datos temporales y estructurales en un modelo de grafos.
Las características temporales no solo ayudan a identificar fraudes, sino que también permiten ajustar los modelos a variaciones locales y estacionales, como las políticas económicas en Argentina o el comportamiento en fechas comerciales clave.
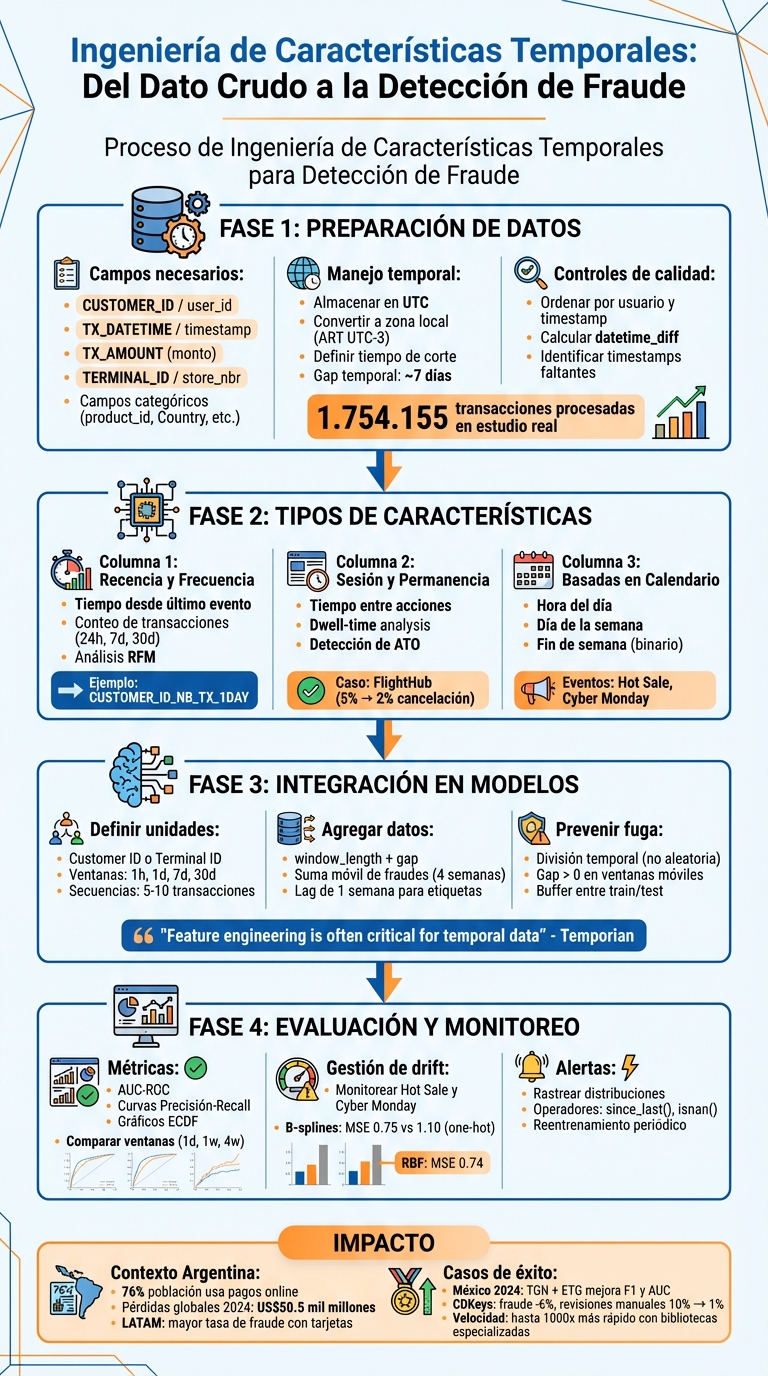
Proceso completo de ingeniería de características temporales para detección de fraude
Preparación de datos para ingeniería de características temporales
Antes de desarrollar características temporales, es fundamental organizar y limpiar los datos transaccionales. Este proceso es clave para garantizar que las características sean precisas y útiles. La calidad de esta preparación afecta directamente la capacidad del modelo para detectar fraudes de manera efectiva. Aquí te explicamos los pasos esenciales para trabajar con este tipo de datos y asegurar que estén listos para la tarea.
Campos transaccionales necesarios
Para construir características temporales en un dataset de e-commerce, se requieren ciertos campos básicos que permiten analizar patrones y comportamientos:
- Variables de referencia (
CUSTOMER_ID,user_id): estas identifican cada transacción y la conectan con el historial del usuario. - Marca temporal (
TX_DATETIME,timestamp): indica el momento exacto de cada transacción, lo que facilita el cálculo de recencia y frecuencia. - Monto (
TX_AMOUNT): esencial para calcular promedios móviles y detectar anomalías en los gastos. - Identificadores del punto de venta (
TERMINAL_ID,store_nbr): útiles para identificar fraudes en terminales o comercios específicos. - Campos categóricos (
product_id,Merchant Category,Country,transaction_type): permiten segmentar y refinar las características según el contexto.
Por ejemplo, un estudio basado en 1.754.155 transacciones demostró que métricas como la "suma móvil de fraudes por cliente" y "suma móvil de fraudes por terminal" en ventanas de 4 semanas son muy efectivas para identificar actividades sospechosas. Este tipo de preparación impacta directamente en la capacidad del modelo para diferenciar entre patrones legítimos y fraudulentos, reduciendo errores en la detección.
Manejo de marcas de tiempo y zonas horarias
Para garantizar coherencia al consolidar datos de diferentes regiones, almacena todas las transacciones en UTC. Sin embargo, para extraer características basadas en el calendario, como "hora del día" o "fin de semana", es importante convertir las marcas de tiempo a la zona horaria local. En Argentina, esto significa usar ART (UTC-3), ya que los patrones de comportamiento suelen depender del horario local.
Convierte los timestamps en objetos datetime (por ejemplo, con pd.to_datetime) para facilitar cálculos temporales. Además, define un tiempo de corte (cutoff time) que excluya datos posteriores al momento de predicción, evitando así la fuga de información durante el entrenamiento. Si tu modelo incluye una variable objetivo como is_fraud, considera implementar un gap temporal (por ejemplo, 7 días) que refleje el tiempo real necesario para confirmar una transacción como fraudulenta.
Controles de calidad para datos temporales
Ordena los datos por usuario y cronológicamente por la marca de tiempo para calcular adecuadamente ventanas móviles y características basadas en retrasos (lag features). Calcula la diferencia temporal entre transacciones consecutivas de un mismo usuario (datetime_diff = timestamp_actual - timestamp_anterior) para detectar inconsistencias o fechas incorrectas.
Además, identifica marcas de tiempo faltantes, ya que pueden interrumpir el cálculo de ventanas móviles y retrasos. Herramientas como infer_temporal_frequencies de Woodwork pueden ayudarte a detectar intervalos regulares en los datos, lo que facilita definir ventanas y gaps con mayor precisión.
Con estos pasos, estarás en una mejor posición para construir características temporales sólidas que mejoren el rendimiento de tu modelo.
Tipos principales de características temporales para detección de fraude
Una vez que los datos están limpios y organizados, el siguiente paso es identificar y extraer características temporales que sean clave para detectar actividades inusuales. Estas características se agrupan en tres categorías principales: recencia y frecuencia, sesión y tiempo de permanencia, y características basadas en calendario. Este enfoque permite a los modelos identificar patrones incluso en momentos de alta actividad.
Características de recencia y frecuencia
Las características de recencia se enfocan en medir el tiempo transcurrido desde eventos específicos, como la última transacción, el último inicio de sesión o el último cambio de contraseña. Por ejemplo, si un usuario realiza una compra desde una ubicación nueva minutos después de una transacción previa, esto podría ser una señal de alerta.
Por otro lado, las características de frecuencia contabilizan cuántas veces ocurre un evento dentro de un período definido, como transacciones en las últimas 24 horas, 7 días o 30 días. Estas métricas son útiles para identificar "ráfagas" de actividad que no coinciden con el comportamiento habitual del usuario. Un caso típico sería el de un estafador que intenta vaciar una cuenta mediante múltiples retiros en un corto período de tiempo.
Un enfoque efectivo es combinar recencia y frecuencia con valores monetarios, como en el análisis RFM (Recencia, Frecuencia y Valor Monetario). Esto ayuda a distinguir entre clientes legítimos y estafadores que buscan agotar rápidamente una cuenta. Ejemplos de estas características incluyen CUSTOMER_ID_NB_TX_1DAY (número de transacciones de un cliente en las últimas 24 horas) o AVG_T_Interval (intervalo promedio entre las últimas nueve transacciones), que pueden resaltar patrones sospechosos.
Características de sesión y tiempo de permanencia
Este grupo de características mide el tiempo que pasa entre acciones específicas del usuario, como el intervalo entre el primer contacto con un sitio y la compra final. Estas métricas son útiles para diferenciar entre usuarios legítimos que navegan con calma y bots o estafadores que operan a velocidades inusuales.
El análisis del tiempo de permanencia (dwell-time) es especialmente útil para detectar intentos de Account Takeover (ATO), ya que permite identificar comportamientos que se desvían del patrón histórico del usuario. Por ejemplo, si un cliente suele tomarse 5 minutos para completar una compra, pero de repente realiza una transacción en solo 30 segundos, esto podría ser motivo de sospecha.
Casos reales muestran la eficacia de estas métricas. Por ejemplo, FlightHub Group, que atiende a más de 5 millones de clientes al año, redujo su tasa de cancelación del 5% a menos del 2% al implementar un sistema automatizado de detección de fraude. De manera similar, CDKeys logró disminuir las transacciones fraudulentas en un 6% y redujo la necesidad de revisiones manuales del 10% a menos del 1%.
Además de analizar la interacción directa de los usuarios, es fundamental observar cómo estas actividades varían según el calendario.
Características basadas en calendario
Las características relacionadas con el calendario incluyen factores como la hora del día, el día de la semana y etiquetas binarias que identifican si una transacción ocurrió durante la noche o el fin de semana. Las actividades fraudulentas suelen concentrarse en momentos específicos, y extraer estas variables ayuda a los modelos a diferenciar entre horarios normales y períodos de mayor riesgo.
En América Latina, donde se registra la tasa más alta de fraude con tarjetas de crédito a nivel mundial, los patrones de compra tienen características propias. En Argentina, por ejemplo, los hábitos de consumo varían significativamente según horarios locales (ART, UTC-3) y fechas especiales como el Día de la Madre, el Hot Sale o el Cyber Monday. Incorporar estas variables permite distinguir entre comportamientos estacionales legítimos y actividades sospechosas.
Un estudio realizado en diciembre de 2024 demostró la eficacia de estas técnicas. Investigadores aplicaron un algoritmo de Red de Grafos Temporales (TGN) a datos de Moneypool, una plataforma de pagos en línea muy utilizada en México. Al integrar múltiples eventos de interacción (como registros de tarjetas, dispositivos y cuentas bancarias) en un Grafo Temporal Basado en Eventos (ETG), lograron mejorar significativamente las métricas F1 y AUC en la detección de fraude, destacando la utilidad de este enfoque en mercados latinoamericanos.
Para manejar patrones estacionales y festivos, es útil usar características "conscientes del contexto", que comparen transacciones actuales con valores históricos agregados, como promedios móviles o sumas. Además, incluir un retraso (lag) de aproximadamente una semana en las características basadas en etiquetas de fraude históricas evita la fuga de datos, ya que muchas confirmaciones de fraude solo están disponibles después de ese período. Por ejemplo, calcular el número de transacciones fraudulentas en un terminal durante las últimas 4 semanas, pero con un retraso de 7 días, ofrece una representación más realista de la operativa.
Integrar características temporales en modelos de detección de fraude
Una vez que se identifican las características temporales clave, el desafío siguiente es integrarlas correctamente en los modelos de detección. Esto implica tomar decisiones técnicas precisas sobre cómo estructurar los datos, calcular las agregaciones y asegurarse de que el modelo no aprenda información que no estaría disponible en un escenario real. Estas decisiones están estrechamente ligadas a la preparación de datos y la extracción de características mencionadas anteriormente.
Definir unidades de observación y ventanas temporales
El primer paso es definir la variable de referencia, como Customer ID o Terminal ID, para organizar los datos cronológicamente. En el caso de detección de fraude, el uso de Customer ID ayuda a identificar comportamientos que se desvían del historial de un cliente en particular. Por otro lado, el Terminal ID es útil para detectar patrones como el skimming en cajeros automáticos.
Para capturar tanto eventos repentinos como cambios más graduales, utiliza ventanas deslizantes de diferentes duraciones, como 1, 7 y 30 días, y experimenta con escalas que van desde 1 hora hasta 30 días. Si estás trabajando con modelos secuenciales, como LSTMs o CNNs, se recomienda usar secuencias de 5 a 10 transacciones para reflejar las dinámicas recientes.
Agregar datos temporales
El siguiente paso es calcular agregados basados en las ventanas temporales definidas. Esto requiere establecer parámetros como window_length (qué tan atrás se observa) y gap (el retraso entre el momento actual y el inicio de la ventana). Estas agregaciones pueden ser manuales, como calcular el promedio de montos en los últimos 7 días, o automáticas, utilizando modelos como CNNs o LSTMs que analizan patrones directamente en las secuencias de datos.
En 2023, utilizando las bibliotecas Temporian y TensorFlow Decision Forests, se procesó un conjunto de datos bancarios sintético con 1.754.155 transacciones registradas entre abril y septiembre de 2018. Entre las características generadas estaban la "suma móvil de fraudes por cliente" y "por terminal", basadas en una ventana de 4 semanas con un retraso de 1 semana para reflejar el tiempo real necesario para reportar un fraude.
"Feature engineering is often critical for temporal data, and... complex feature engineering can be performed with ease using Temporian." - Temporian Documentation
Es fundamental que las ventanas de observación se configuren de manera que excluyan cualquier dato futuro, para evitar que el modelo acceda a información que no estaría disponible al momento de hacer una predicción.
Prevenir la fuga de datos
Una vez calculadas las agregaciones, es crucial evitar que el modelo acceda a información futura, ya que esto podría generar resultados poco realistas. La fuga de datos ocurre cuando el modelo utiliza información que, en un escenario real, no estaría disponible en el momento de la predicción. Por ejemplo, la etiqueta de una transacción (fraudulenta o legítima) solo se conoce después de que un cliente presenta una queja o se completa una investigación, lo cual puede tardar días o semanas.
Para mitigar este riesgo, aplica un lag (por ejemplo, de 1 semana) a las características basadas en etiquetas históricas, dado que la mayoría de los reportes de fraude se generan dentro de este período. Además, al calcular características con ventanas móviles, configura un gap mayor a 0 para asegurarte de que la transacción actual no se incluya en sus propios cálculos.
"A gap of 0 would include the instance itself, which we must be careful to avoid in time series problems, as this exposes our target." - Featuretools Documentation
Por último, divide los datos de manera cronológica en lugar de hacerlo aleatoriamente. El conjunto de entrenamiento debe contener datos históricos, seguidos de un período de retraso (buffer), y finalmente, el conjunto de prueba.
Evaluar y monitorear características temporales
Después de integrar características temporales en el modelo, el siguiente paso esencial es analizar su desempeño en escenarios reales. Esto implica medir su impacto y actualizar el sistema a medida que los patrones de fraude evolucionan.
Medir el rendimiento de las características
Para evaluar correctamente, es clave utilizar una división temporal en lugar de una aleatoria. Esto significa entrenar el modelo con datos históricos de varios meses y probarlo en el mes siguiente, simulando condiciones reales de producción. Entre las métricas más útiles para este tipo de análisis se encuentran el Área Bajo la Curva ROC (AUC) y las curvas de Precisión-Recall, especialmente efectivas en conjuntos de datos desbalanceados, como ocurre frecuentemente en casos de fraude.
Para determinar qué tan bien las características diferencian entre transacciones fraudulentas y legítimas, los gráficos ECDF son herramientas visuales muy valiosas. Por ejemplo, permiten verificar si métricas como la "suma móvil de fraudes por terminal" logran separar claramente ambos grupos. También es importante experimentar con diferentes anchos de ventana (1 día, 1 semana, 4 semanas) y analizar cómo cada característica afecta el modelo al incluirla o excluirla.
Gestionar el drift y la estacionalidad
El fraude no es estático, y las características predictivas de hoy podrían dejar de ser efectivas mañana. Esto es especialmente relevante en períodos de alta actividad comercial en Argentina, como el Hot Sale en mayo o el Cyber Monday en noviembre, cuando métricas como "transacciones en la última hora" tienden a cambiar drásticamente. Si detectás variaciones significativas en estas métricas, es probable que el modelo necesite ser reentrenado o recalibrado.
Para capturar patrones estacionales más complejos, métodos como la codificación con B-splines son una alternativa superior al one-hot encoding. Por ejemplo, la codificación con splines logró un error cuadrático medio (MSE) de 0,75 frente a 1,10 del one-hot encoding tradicional. Incluso las funciones de base radial (RBF) lograron un rendimiento ligeramente mejor, con un MSE de 0,74. Estas técnicas pueden marcar una gran diferencia en la precisión del modelo.
Monitoreo y alertas
Es fundamental implementar sistemas que rastreen la distribución de las características temporales a lo largo del tiempo. Variables como la "suma móvil de fraudes por cliente" o "por terminal" deben monitorearse constantemente, ya que cambios significativos podrían indicar nuevos patrones de fraude, como esquemas de skimming en cajeros automáticos. Herramientas especializadas pueden ayudar a mantener la coherencia entre el desarrollo y el monitoreo.
"Feature engineering is often critical for temporal data, and this notebook demonstrates how complex feature engineering can be performed with ease using Temporian." - Temporian Documentation
Además, operadores como since_last() e isnan() son útiles para separar los datos de entrenamiento y prueba, permitiendo un monitoreo más preciso de la efectividad de las características a lo largo del tiempo.
Conclusión
Como vimos antes, la ingeniería de características temporales no es solo una herramienta más en la detección de fraude; es el pilar que permite construir modelos que entienden el contexto. Al vincular cada transacción con el historial de comportamiento del cliente, estas características transforman los datos en patrones capaces de revelar actividades fraudulentas.
En el comercio electrónico argentino, donde el 76% de la población elige métodos de pago online y las pérdidas globales por fraude alcanzaron los US$50,5 mil millones en 2024, ajustar estas características a las dinámicas locales es esencial. Eventos como el Hot Sale, el Cyber Monday o incluso la distribución de ayudas gubernamentales generan picos de actividad legítima que, sin el contexto temporal adecuado, podrían activar falsas alarmas.
"La ventaja de utilizar Machine Learning en la detección de fraude es que esta técnica permite adaptarse y mejorar constantemente a medida que se recopilan más datos y se descubren nuevos métodos de fraude." - Juliana Muñoz, Alice Biometrics
Para lograr un monitoreo efectivo, implementá ventanas deslizantes que analicen tanto comportamientos a corto plazo (1 día) como a largo plazo (30 días), teniendo en cuenta los tiempos de confirmación del mundo real. Además, el uso de bibliotecas especializadas para manejar datos temporales puede ser hasta 1.000 veces más rápido que las herramientas genéricas, lo que facilita procesar grandes volúmenes de información sin perder precisión. Este enfoque asegura que el sistema pueda adaptarse rápidamente a los cambios en los patrones de fraude.
La clave para un sistema de detección de fraude efectivo es que las características temporales se alineen con la operativa de tu negocio y las particularidades del mercado argentino. Monitorear constantemente, ajustar las ventanas según la estacionalidad y reentrenar los modelos de manera periódica son prácticas indispensables para mantener tu sistema un paso adelante frente a los defraudadores.
FAQs
¿Qué rol juegan las características temporales en la detección de fraudes?
Las características temporales permiten analizar cada transacción como parte de una secuencia de eventos, en lugar de verla como un hecho aislado. Al considerar datos como la hora del día, el día de la semana, el tiempo transcurrido desde la última compra o la frecuencia de transacciones en un período corto, se pueden identificar patrones que llaman la atención. Por ejemplo, un aumento repentino de compras nocturnas o pagos realizados en intervalos extremadamente breves suelen ser señales de posibles actividades fraudulentas.
Incluir estas variables temporales en el análisis ayuda a que los algoritmos comprendan mejor las relaciones y dependencias en el comportamiento de los clientes. Esto no solo mejora la precisión al detectar anomalías, sino que también reduce la cantidad de falsos positivos. Por ejemplo, métricas como el “tiempo desde la última transacción” o la “cantidad de transacciones realizadas en la última hora” permiten identificar comportamientos que se desvían de lo habitual en tiempo real. Esto optimiza tanto la detección como la capacidad de respuesta frente a intentos de fraude.
¿Qué pasos son clave para preparar datos temporales en análisis de fraude?
Trabajar con datos temporales exige prestar especial atención al orden cronológico, ya que cualquier descuido puede afectar negativamente a los modelos predictivos. Aquí hay algunos puntos clave que no se pueden pasar por alto:
- Unificar la frecuencia temporal: Asegurate de que los datos tengan una frecuencia consistente, ya sea diaria, horaria u otra. Si hay intervalos faltantes, podés rellenarlos utilizando métodos como forward-fill o interpolación para mantener la coherencia.
- Manejo de valores ausentes y atípicos: Los datos incompletos o extremos pueden sesgar cálculos importantes, como las medias móviles o las variables de retraso (lag). Es crucial identificarlos y tratarlos adecuadamente.
-
Creación de nuevas variables temporales: Incorporar variables que capturen patrones temporales puede marcar la diferencia. Por ejemplo:
- Retardos (lag) para analizar eventos pasados.
- Promedios móviles para suavizar fluctuaciones.
- Tendencias y características cíclicas (como el día de la semana o la hora del día), que pueden codificarse usando funciones de seno y coseno para representar ciclos de manera continua.
División de datos: respetar la cronología
Cuando dividas los datos en conjuntos de entrenamiento y validación, es esencial mantener el orden temporal. Por ejemplo, podés usar datos hasta el 31/12/2024 para entrenar el modelo y reservar los registros posteriores para validación. Este enfoque asegura que el modelo no "vea" información futura durante el entrenamiento, evitando sesgos.
Otros detalles importantes
No olvides sincronizar las zonas horarias para evitar inconsistencias en los datos. Además, incluir marcas de tiempo relevantes, como intentos de inicio de sesión o cambios de IP, puede ser especialmente útil en aplicaciones como la detección de fraude. Estas marcas temporales pueden aportar contexto valioso y mejorar la precisión de los modelos.
¿Cómo se pueden usar las características temporales para mejorar la detección de fraude?
Las características temporales son esenciales para identificar patrones de comportamiento a lo largo del tiempo, lo que resulta clave en la detección de fraude. Por ejemplo, a partir de las marcas de tiempo de las transacciones, se pueden calcular variables como:
- El monto total transaccionado.
- La cantidad de operaciones realizadas.
- El tiempo promedio entre transacciones dentro de intervalos específicos (como los últimos 5 minutos, 1 hora o 24 horas).
Además, se pueden incorporar atributos cíclicos, como el día de la semana o la hora del día. Estos se codifican utilizando funciones seno y coseno para reflejar tendencias periódicas de manera más precisa.
Estas variables temporales se combinan con datos estáticos, como el monto de la transacción o la ubicación, y se procesan mediante algoritmos avanzados como bosques de decisiones o redes neuronales. Este enfoque permite capturar las dependencias temporales de manera más efectiva, mejorando la precisión del modelo y reduciendo los falsos positivos. Es una estrategia clave para detectar comportamientos anómalos en transacciones de e-commerce o banca.
