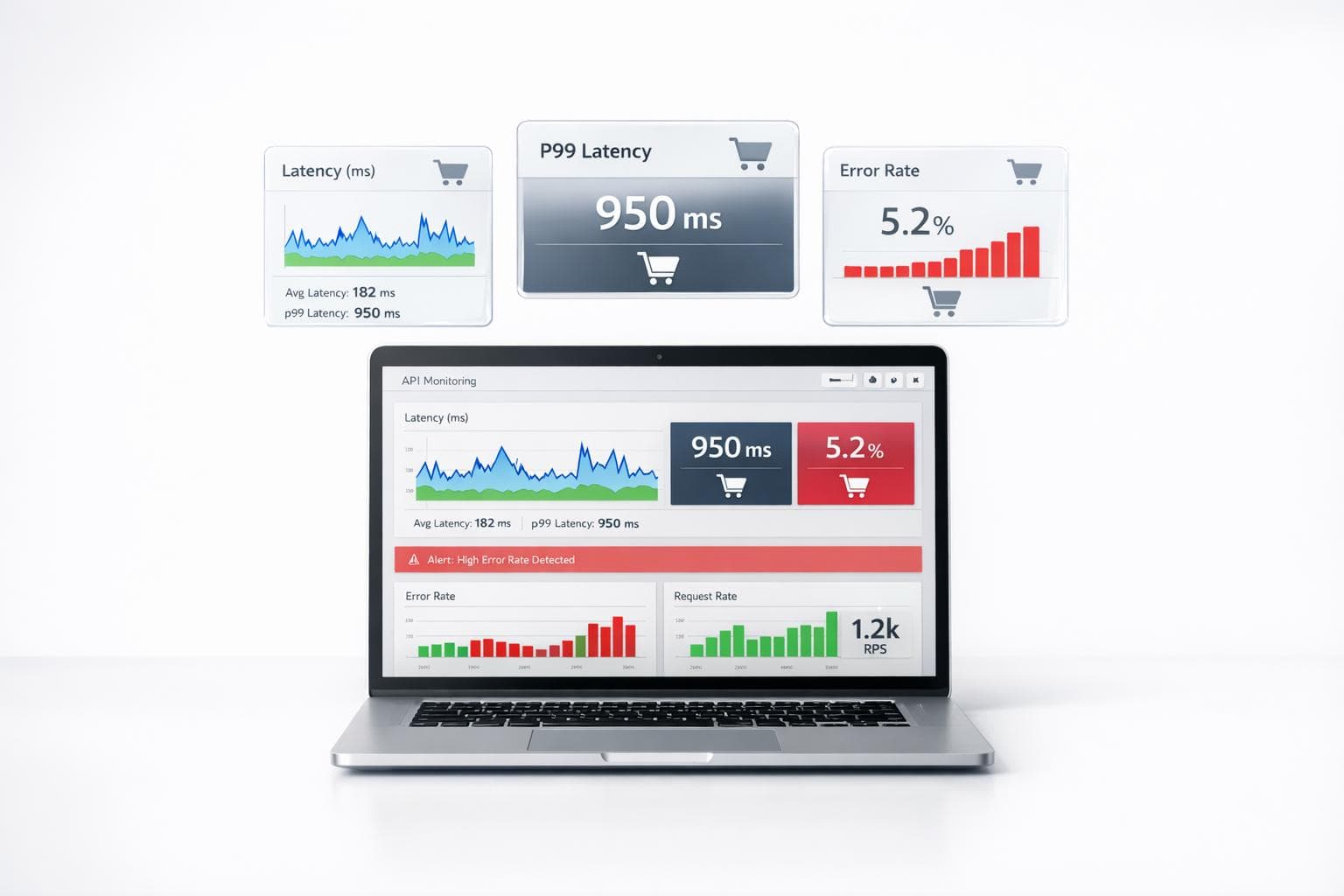
¿Tus APIs están listas para manejar problemas antes de que afecten a tus clientes?
El monitoreo en tiempo real de APIs es clave para evitar pérdidas de ingresos, clientes frustrados y problemas operativos. Esto implica supervisar constantemente métricas como latencia, errores y disponibilidad para detectar fallas antes de que sean un problema mayor. Sin esta práctica, tu negocio opera a ciegas, confiando en quejas de clientes como primera señal de alerta.
Conclusión rápida: Implementar monitoreo en tiempo real protege tus APIs, mejora la experiencia del usuario y asegura que tu negocio funcione sin interrupciones. Actuá ahora para evitar problemas futuros.
El monitoreo de APIs en tiempo real se basa en recopilar y analizar datos clave como latencia, errores y rendimiento, alertando sobre cualquier problema que pueda surgir en la producción. Este enfoque no solo verifica si una API está activa o caída, como lo haría un método tradicional, sino que profundiza en métricas específicas como los percentiles de latencia y la distribución de códigos de error HTTP (por ejemplo, 4xx frente a 5xx).
A diferencia del enfoque tradicional, que reacciona únicamente ante fallos críticos o reportes, el monitoreo en tiempo real es preventivo. Esto significa que permite identificar problemas antes de que impacten al usuario final. En sectores como el comercio electrónico, donde las APIs son esenciales para conectar sistemas como pedidos, inventarios y logística, este monitoreo asegura que los datos se sincronicen al instante, garantizando una experiencia de usuario sin interrupciones.
Adoptar un monitoreo en tiempo real puede reducir significativamente el tiempo promedio de resolución de problemas (MTTR). Las alertas inmediatas y los registros detallados facilitan identificar y resolver errores rápidamente. Esto se traduce en menos interrupciones, una menor tasa de abandono de carritos y una integración más eficiente entre los sistemas.
Un ejemplo claro es el caso de AkzoNobel, que logró reducir su tiempo de respuesta al cliente de seis horas a solo 70 minutos. Por su parte, SurfStitch, un retailer australiano, experimentó una reducción del 89% en pedidos sobrevendidos, un aumento del 43% en envíos el mismo día y una disminución del 37% en costos de inventario tras integrar su tienda Shopify Plus con un sistema de inventario basado en APIs en 2024.
Además, este monitoreo tiene un impacto directo en el SEO y la experiencia del usuario. Los motores de búsqueda penalizan los sitios lentos, y cuando la latencia de una API crítica, como la del proceso de checkout, supera los 200 ms, las tasas de conversión pueden caer drásticamente. También, el 90% de los clientes espera respuestas inmediatas a sus consultas de servicio.
En resumen, mientras los beneficios son evidentes, no monitorear las APIs puede generar riesgos significativos.
Detectar problemas de manera tardía puede tener consecuencias graves: pérdida de ingresos por inactividad, clientes insatisfechos que abandonan sus carritos y complicaciones operativas difíciles de manejar sin una detección temprana. Según estadísticas, el 35% de las empresas ha enfrentado al menos un incidente de seguridad relacionado con APIs en el último año, y el 66% ha tenido que retrasar el lanzamiento de nuevas aplicaciones debido a preocupaciones de seguridad en sus APIs.
Un sistema de monitoreo eficaz se basa en tres pilares principales que trabajan juntos para asegurar que tus APIs funcionen correctamente. Conocer el papel de cada uno de estos componentes te ayudará a decidir qué características priorizar al diseñar tu estrategia de monitoreo.
La disponibilidad mide qué porcentaje del tiempo una API está operativa y accesible para responder solicitudes. Por ejemplo, muchos Acuerdos de Nivel de Servicio (SLA) requieren un uptime del 99,9%, lo que equivale a aproximadamente 43 minutos de inactividad al mes.
Pero monitorear uptime no es solo verificar que la API responda con un código 200 OK. Es igual de importante confirmar que los datos devueltos sean correctos y que la lógica de negocio se cumpla. Como destaca Zuplo: "Un código de estado 200 con JSON corrupto sigue representando una falla".
En sectores como el comercio electrónico, es crucial monitorear endpoints clave, como el checkout y el procesamiento de pagos, desde diferentes ubicaciones. Esto permite identificar problemas de latencia que podrían variar según la región.
La latencia mide el tiempo que tarda una solicitud en comenzar a procesarse, mientras que el tiempo de respuesta abarca todo el proceso, desde recibir la solicitud hasta entregar la respuesta completa. Si solo se observan promedios, es fácil pasar por alto problemas que afectan a ciertos usuarios.
Por eso, analizar percentiles como p95 y p99 resulta esencial. Si la latencia p99 supera los 500 ms, el 1% de los usuarios experimenta retrasos significativos, lo que puede perjudicar las tasas de conversión. Este grupo suele incluir clientes de alto valor, lo que hace que cualquier impacto en su experiencia sea aún más crítico.
El throughput, o cantidad de solicitudes procesadas por segundo o minuto, también es una métrica clave. Ayuda a identificar picos de tráfico o posibles ataques. Además, monitorear el Time to First Byte (TTFB) es útil: cuando supera los 200 ms, puede ser señal de cuellos de botella en el backend. Tener estas métricas bajo control y configurar alertas precisas es vital para una supervisión efectiva.
Un buen sistema de monitoreo rastrea las solicitudes fallidas, diferenciando entre errores 4xx (problemas del cliente, como solicitudes mal formadas) y 5xx (fallas del servidor o sobrecarga en la infraestructura). Un aumento repentino en los errores 5xx es una alerta crítica que puede indicar problemas graves, como fallos en la infraestructura o bugs que necesitan atención inmediata.
Las alertas automatizadas son fundamentales para actuar rápidamente. Estas pueden enviarse a través de herramientas como Slack, PagerDuty o SMS cuando se superan ciertos umbrales predefinidos. Configurar umbrales adecuados es clave: un tiempo de respuesta de 300 ms podría ser aceptable en horarios de baja actividad, pero un problema grave durante picos de tráfico.
Un sistema de alertas bien diseñado permite abordar problemas antes de que los clientes los noten, evitando que las quejas se conviertan en tu única fuente de monitoreo. Esto no solo mejora la experiencia del usuario, sino que también protege la reputación de tu servicio.
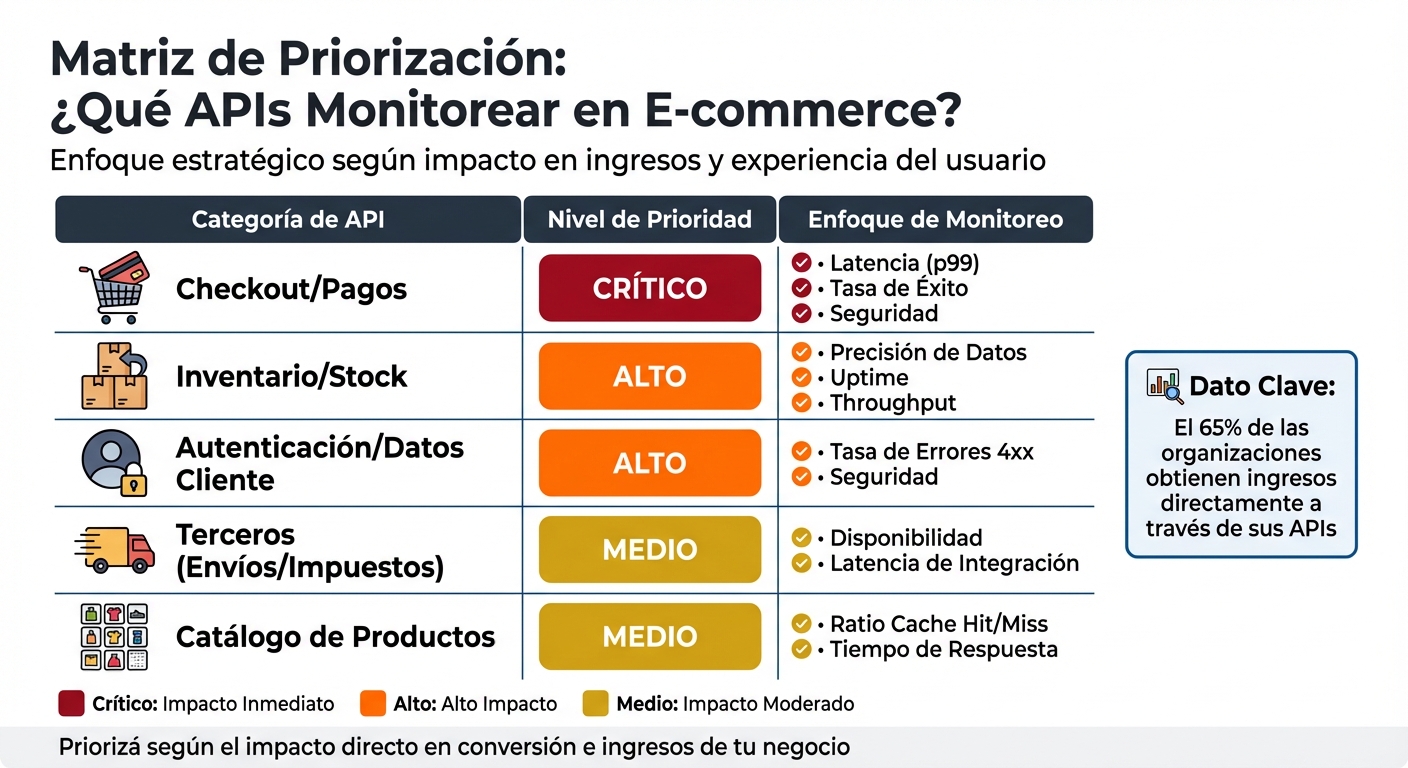
Priorización de APIs para Monitoreo en E-commerce: Niveles Críticos y Métricas Clave
Implementar un monitoreo enfocado en endpoints clave puede marcar una gran diferencia en la experiencia del usuario y en los ingresos del negocio.
Es importante mapear los flujos críticos de tu sistema, incluyendo tanto APIs internas como dependencias externas (por ejemplo, servicios de pago o de envíos). Esto te permitirá priorizar aquellas que generan mayor tráfico o presentan más errores. Según datos de la industria, el 65% de las organizaciones obtienen ingresos directamente a través de sus APIs. Esto subraya la necesidad de enfocarse en aquellas que impactan directamente en los resultados del negocio.
Comenzá revisando las dependencias externas, como pasarelas de pago, herramientas de cálculo de envíos y sistemas de inventario. Monitorear estas integraciones te ahorrará tiempo al identificar rápidamente si un problema proviene de un servicio externo en lugar de tu código interno.
| Categoría de API | Nivel de Prioridad | Enfoque de Monitoreo |
|---|---|---|
| Checkout/Pagos | Crítico | Latencia (p99), Tasa de Éxito, Seguridad |
| Inventario/Stock | Alto | Precisión de Datos, Uptime, Throughput |
| Autenticación/Datos Cliente | Alto | Tasa de Errores 4xx, Seguridad |
| Terceros (Envíos/Impuestos) | Medio | Disponibilidad, Latencia de Integración |
| Catálogo de Productos | Medio | Ratio Cache Hit/Miss, Tiempo de Respuesta |
Para establecer un monitoreo efectivo, necesitás definir SLIs (indicadores clave de servicio) y SLOs (objetivos de nivel de servicio) basados en datos históricos. Los SLIs son métricas específicas, como el tiempo de respuesta, mientras que los SLOs son los valores meta que querés alcanzar, como un uptime del 99,9%.
"Las métricas clave de rendimiento sirven como nuestras 'herramientas de navegación' para comprender la salud y el valor de nuestras APIs." - API7.ai
Por ejemplo, podés establecer un umbral para errores 4xx y 5xx, y definir que la latencia p99 en endpoints críticos no supere los 500 ms. Un uptime del 99,9% es un estándar común en la industria, lo que equivale a unos 43 minutos de inactividad permitida al mes.
Con las metas claras, el siguiente paso es configurar las herramientas necesarias para cumplir con esos estándares. Estas herramientas deben ser capaces de detectar fallos antes de que afecten a los usuarios. La estrategia más efectiva incluye un sistema en capas que combine pruebas pre-producción (usando herramientas como k6), plataformas de observabilidad (como Prometheus o Grafana) y gateways de APIs.
Los gateways de APIs, como Apache APISIX, Kong o Amazon API Gateway, son útiles para recolectar datos de rendimiento de todos los servicios sin necesidad de instrumentarlos de forma individual.
Además, es esencial configurar alertas basadas en los SLAs. Por ejemplo, si la latencia p99 de tu API de checkout supera los 500 ms, tu equipo de soporte debe recibir una alerta automática. También es recomendable extender el monitoreo para incluir bases de datos y recursos del servidor, como CPU y memoria, ya que estos pueden ser señales tempranas de posibles cuellos de botella.
Estos ajustes no solo te ayudarán a mantener la estabilidad de tus APIs, sino que también sentarán las bases para optimizar su rendimiento de manera continua.
Una vez que todo está configurado, el siguiente paso clave es elegir las herramientas adecuadas para monitorear el rendimiento de tus APIs. Esta decisión dependerá del tamaño de tu operación, la complejidad de tu stack tecnológico y cuánta visibilidad necesitás sobre tus APIs.
Si trabajás con plataformas como Shopify, Tiendanube o VTEX, donde no es posible instrumentar el código interno directamente, los gateways de APIs como Apache APISIX o Kong son una excelente opción. Estos gateways centralizan el tráfico y recopilan métricas clave, como latencia y errores, de todos los servicios upstream, sin necesidad de instrumentar cada microservicio de forma individual.
Las plataformas de observabilidad como Datadog, New Relic o Prometheus junto con Grafana son ideales para operaciones más complejas y de gran escala. Estas herramientas ofrecen visibilidad completa del stack tecnológico, incluyendo infraestructura en la nube, bases de datos y trazabilidad distribuida. Además, permiten configurar alertas automáticas. Por ejemplo, podés recibir notificaciones si la latencia p99 de la API de checkout supera los 500 ms.
Para validar funcionalidades y realizar pruebas desde distintas ubicaciones geográficas, Postman Monitors es una opción confiable. Esta herramienta permite programar pruebas y ejecutarlas a nivel global, asegurando que las APIs respondan consistentemente para usuarios en diferentes regiones. También se integra con sistemas de monitoreo en tiempo real, proporcionando una visión completa del rendimiento en entornos de e-commerce.
Si tu principal preocupación son los picos de tráfico, como los que ocurren durante eventos como Black Friday o Cyber Monday, herramientas como LoadFocus o k6 son esenciales. Estas plataformas te permiten realizar pruebas de carga y simular flujos de usuario complejos para asegurarte de que tus APIs puedan manejar el volumen esperado.
Finalmente, combiná herramientas de testing sintético, que simulan solicitudes a intervalos regulares, con Real-User Monitoring (RUM), que captura interacciones reales de los usuarios. Esta combinación te ayudará a identificar problemas que podrían pasar desapercibidos en pruebas automatizadas. Este enfoque en capas asegura una visión integral del rendimiento de tus APIs en producción.
Con las herramientas ya configuradas, es hora de aplicar técnicas que potencien el monitoreo y aseguren que tus APIs funcionen al máximo nivel. Estas prácticas complementan las configuraciones previas y ayudan a mantener un rendimiento confiable.
No te limites a probar endpoints aislados. En su lugar, simulá flujos completos como Login → Agregar al carrito → Aplicar descuento → Procesar pago. Este enfoque permite identificar problemas de integración que podrían pasar desapercibidos en pruebas individuales.
Definí indicadores claros de éxito para cada flujo, alineados con los SLIs establecidos, y asigná prioridades según su impacto comercial. Por ejemplo, un API de checkout requiere mayor atención que un endpoint de documentación. Además, este método te ayudará a detectar variaciones de rendimiento entre distintas regiones.
El rendimiento de tu API puede variar drásticamente según la ubicación. Podría funcionar perfectamente en Buenos Aires, pero presentar alta latencia en São Paulo o Madrid.
"Your API might be blazing fast in Virginia, but it may be crawling in Singapore. Multi-region monitoring reveals these geographic performance gaps before your international customers churn."
Configurá pruebas sintéticas desde diferentes regiones y activá alertas específicas para cada ubicación. Esto te permitirá identificar y resolver problemas localizados de manera rápida. Al analizar estos datos, podrás optimizar aún más la experiencia global de tus usuarios.
Analizá tendencias históricas y ajustá los umbrales de rendimiento según las demandas específicas, como variaciones horarias o picos de tráfico. Con más del 75% de las empresas gestionando un promedio de 26 APIs por aplicación desplegada, un análisis sistemático es clave.
Si detectás latencia elevada en horarios de alta demanda, evaluá opciones como el autoescalado o el uso de caché. Además, almacená las configuraciones de monitoreo en sistemas de control de versiones para garantizar consistencia entre los distintos entornos.
El monitoreo en tiempo real de APIs se ha convertido en un pilar esencial para cualquier e-commerce que busque mantenerse competitivo. Con las aplicaciones modernas utilizando entre 26 y 50 APIs y una de cada cinco empresas enfrentando caídas graves en los últimos tres años, la clave está en identificar problemas antes de que afecten a los usuarios.
Las APIs lentas no solo frustran a los usuarios, también generan carritos abandonados e importantes pérdidas de ingresos. Aplicar estrategias como definir SLIs y SLOs claros, además de monitorear desde múltiples ubicaciones, te permite pasar de reaccionar ante incidentes a prevenirlos. De esta manera, podés detectar degradaciones de rendimiento antes de que impacten la experiencia de tus clientes.
Tené en cuenta que un estándar de disponibilidad del 99,9% equivale a 43 minutos de inactividad al mes. Cada minuto cuenta, especialmente cuando procesos críticos como autenticación, checkout o pagos están en juego. Un monitoreo efectivo no solo reduce el tiempo medio de resolución (MTTR) con alertas inmediatas y registros detallados, sino que también asegura que los problemas se resuelvan rápidamente.
Para empezar, enfocá tus esfuerzos en los endpoints que generan ingresos directos, configurá alertas automáticas para detectar violaciones de SLO y analizá datos históricos para mejorar el rendimiento durante picos de tráfico. Invertir en monitoreo no solo protege tu operación actual, sino que también te da la confianza y visibilidad necesarias para crecer sin riesgos. Estos datos resaltan la urgencia de actuar ahora.
Implementá estas estrategias hoy mismo: tus clientes esperan una experiencia impecable, sin importar dónde se encuentren.
Para garantizar que una API funcione de manera eficiente en tiempo real, es clave prestar atención a ciertas métricas que reflejan su desempeño:
Mantener un monitoreo constante de estas métricas permite identificar problemas rápidamente, solucionarlos antes de que afecten gravemente a los usuarios y garantizar una experiencia sin interrupciones.
El monitoreo en tiempo real de APIs es fundamental para garantizar que los servicios de e-commerce operen de manera eficiente y sin interrupciones. Detectar y solucionar problemas como errores o demoras en los tiempos de respuesta al instante evita que estos afecten a los clientes. Esto no solo mejora la experiencia del usuario, sino que también refuerza su satisfacción.
Incorporar métricas como disponibilidad, rendimiento y tiempos de respuesta es clave para mantener un servicio consistente y cumplir con los objetivos de nivel de servicio (SLOs). Las herramientas especializadas con alertas automáticas permiten identificar anomalías rápidamente, lo que facilita resolver incidentes de manera anticipada y asegura una experiencia más fluida y confiable para los usuarios.
El monitoreo en tiempo real no solo optimiza el rendimiento de las APIs, sino que también fortalece la confianza de los clientes y mejora la percepción del servicio, convirtiéndose en un elemento esencial para el éxito de cualquier negocio de e-commerce.
Para supervisar APIs en tiempo real de manera eficiente, es clave contar con herramientas que permitan observar métricas esenciales como la latencia, las tasas de error y la disponibilidad. Entre las opciones más utilizadas destacan Prometheus y Grafana, que ofrecen capacidades para recolectar y visualizar métricas en tiempo real. Estas herramientas son especialmente útiles para identificar problemas rápidamente y mejorar el rendimiento.
También son muy prácticas herramientas como Postman, que permite monitorear automáticamente el estado de las APIs y enviar alertas en caso de fallas. Además, plataformas de observabilidad como Datadog o New Relic consolidan métricas, logs y trazas en un solo lugar, lo que facilita un análisis más detallado. La elección de la herramienta adecuada dependerá de los requerimientos específicos del proyecto, aunque combinar varias de estas opciones puede ofrecer un monitoreo más completo y eficiente.