
El clustering es clave para segmentar clientes en e-commerce. Con algoritmos como K-Means, DBSCAN, y SOM, podés dividir a tus usuarios según su comportamiento, optimizando campañas y aumentando conversiones. Por ejemplo, una tienda puede identificar "compradores frecuentes" o "cazadores de descuentos", personalizando promociones en pesos argentinos ($1.250,50). Acá te cuento cómo elegir el mejor método para tu negocio.
| Algoritmo | Escalabilidad | Manejo de Outliers | Formas de Clusters | Número de Clusters |
|---|---|---|---|---|
| K-Means | Alta | Sensible | Esféricos | Requiere definir K |
| Jerárquico | Baja en grandes datasets | Moderado | Variadas | Automático |
| DBSCAN | Media | Excelente | Arbitrarias | Automático |
| GMM | Media | Moderado | Elípticos | Requiere definir K |
| SOM | Media | Moderado | Complejas | Automático |
Elegí según tus datos, objetivos y recursos técnicos. Si buscás resultados rápidos, empezá con K-Means. Si necesitás análisis más detallados, DBSCAN o GMM pueden ser mejores opciones.
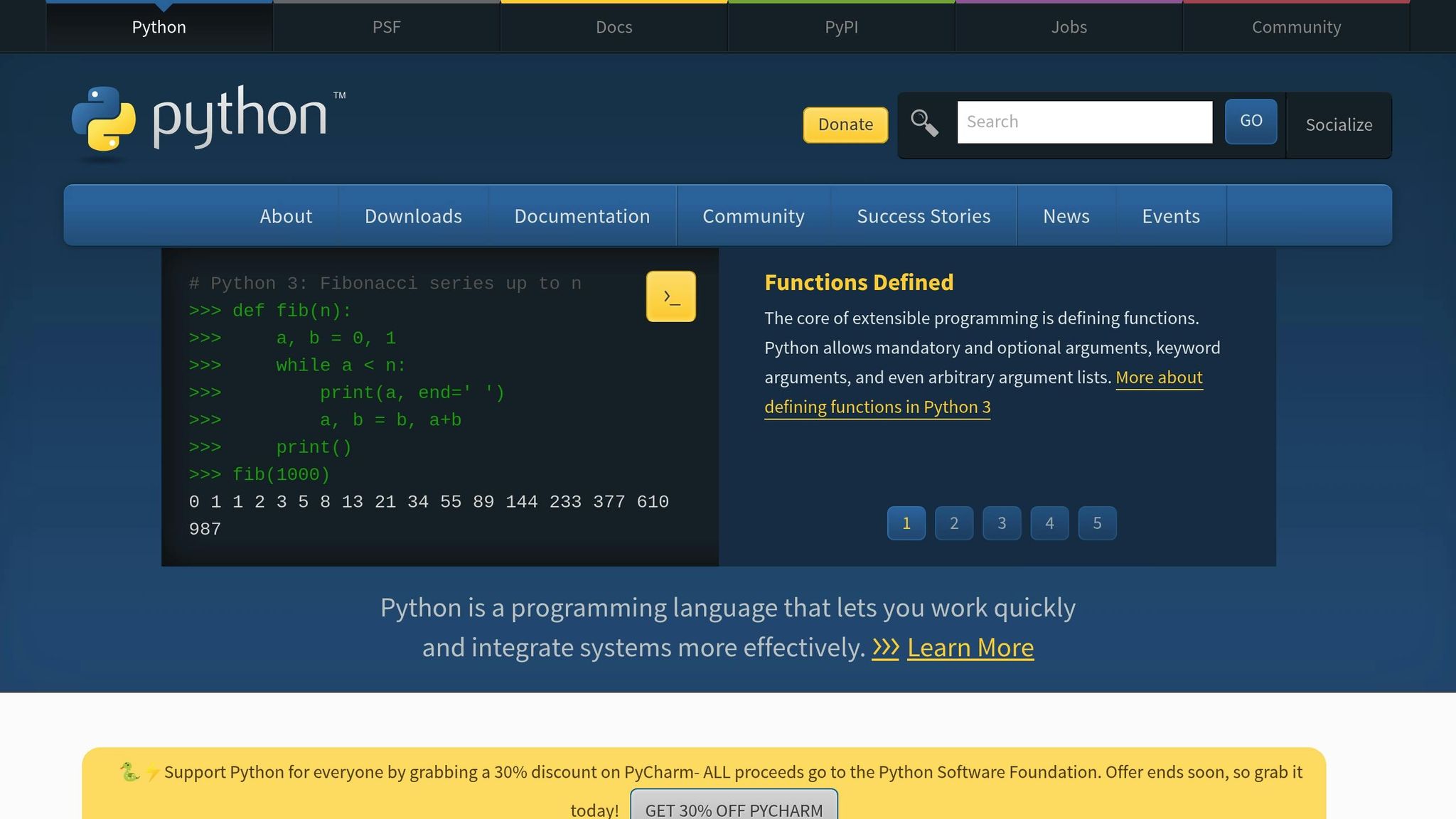
K-Means es uno de los algoritmos de agrupamiento más conocidos y utilizados en el ámbito del e-commerce para segmentar clientes. Este método divide automáticamente a los clientes en K grupos, basándose en su cercanía a ciertos centroides predefinidos. Por ejemplo, una tienda en Argentina podría identificar segmentos como "compradores de alto valor" (aquellos que gastan más de $50.000 ARS al mes) al analizar patrones específicos de comportamiento.
El algoritmo toma en cuenta datos como el gasto total (en pesos argentinos), la frecuencia de compra, las categorías de productos preferidas y la interacción en canales de comunicación. Gracias a esto, K-Means permite descubrir patrones útiles para diseñar campañas de marketing personalizadas. A continuación, se detalla cómo este algoritmo puede manejar grandes volúmenes de datos y abordar desafíos comunes en el análisis de clientes.
Una de las grandes ventajas de K-Means es su capacidad para procesar cantidades masivas de datos de manera eficiente. Su complejidad computacional es lineal, lo que significa que puede analizar millones de registros en cuestión de minutos. Por ejemplo, un retailer argentino con millones de transacciones podría dividir a sus clientes en 25 clusters específicos para campañas enfocadas. Esto resulta especialmente práctico en eventos como el Hot Sale o el Cyber Monday, donde el volumen de transacciones se dispara.
Además, la velocidad del algoritmo permite actualizar los segmentos de manera frecuente, facilitando la integración con plataformas que trabajan con datos en tiempo real. Esto asegura que las estrategias de marketing estén siempre alineadas con los comportamientos más recientes de los clientes.
Un desafío importante de K-Means es su sensibilidad a los valores atípicos. Dado que el algoritmo calcula los centroides utilizando la media, clientes con comportamientos extremos pueden distorsionar los resultados. Por ejemplo, si unos pocos clientes realizan compras significativamente mayores que el promedio, esto puede sesgar los clusters. Para mitigar este problema, es esencial limpiar los datos eliminando valores atípicos y normalizando variables como el gasto total antes de aplicar el algoritmo.
K-Means funciona mejor cuando los clusters tienen formas esféricas y tamaños similares. Sin embargo, en el contexto del e-commerce, los segmentos de clientes suelen ser más irregulares, lo que puede requerir ajustes o el uso de técnicas complementarias. A pesar de esta limitación, su facilidad de implementación lo convierte en una herramienta ideal para sistemas modernos de comercio electrónico, como los que utiliza Burbuxa.
Otra ventaja clave de K-Means es su compatibilidad con herramientas analíticas como Python (a través de bibliotecas como scikit-learn) o Tableau, lo que permite conectarlo directamente con sistemas de e-commerce. Por ejemplo, Burbuxa puede usar esta integración para segmentar automáticamente a sus clientes y personalizar las interacciones en canales como WhatsApp e Instagram. Esto incluye el envío de promociones específicas o recordatorios adaptados al perfil de cada grupo.
Una vez configurado, el sistema puede actualizar los clusters de forma automática y aplicar estrategias personalizadas sin necesidad de intervención manual, optimizando así la experiencia del cliente y los resultados del negocio.
El clustering jerárquico ofrece una manera distinta de abordar la segmentación de clientes. A diferencia de métodos como el K-Means, este enfoque construye una jerarquía de grupos sin necesidad de predefinir cuántos segmentos se desean. El resultado es un dendrograma, un diagrama en forma de árbol que muestra cómo se relacionan los grupos a diferentes niveles de detalle.
Este método sigue un enfoque aglomerativo, comenzando con cada cliente como un grupo individual y fusionándolos gradualmente con los más similares hasta formar una jerarquía completa. Por ejemplo, una tienda de electrónicos podría descubrir que sus clientes se agrupan en categorías como "gamers", "usuarios de productividad" o "entusiastas de smart home", y también identificar cómo estos segmentos se conectan en niveles más amplios.
Una de las grandes ventajas del clustering jerárquico es su capacidad para identificar grupos con formas irregulares, algo clave en el comercio electrónico, donde los comportamientos de los clientes pueden ser muy variados. El dendrograma no solo ayuda a visualizar estas relaciones, sino que también facilita la elección de una segmentación adecuada, ya sea con pocos grupos generales o con varios segmentos más específicos, dependiendo de la estrategia.
Sin embargo, este método tiene sus limitaciones. Su complejidad es alta, con un costo de O(n³) en tiempo y O(n²) en memoria, lo que puede hacerlo inviable para bases de datos muy grandes. En estos casos, una solución práctica sería usar un algoritmo más rápido, como K-Means, para una segmentación inicial, y luego aplicar clustering jerárquico en subconjuntos específicos que requieran un análisis más detallado.
Además, este algoritmo es muy sensible a los valores atípicos. Un solo cliente con comportamientos extremos puede alterar significativamente la estructura de la jerarquía. Sin embargo, esta sensibilidad también puede ser una ventaja, ya que permite identificar segmentos poco comunes pero estratégicamente importantes, como clientes VIP o nichos específicos.
El clustering jerárquico puede implementarse fácilmente con herramientas como scikit-learn en Python o software como Tableau. En plataformas como Burbuxa, que gestionan interacciones en WhatsApp e Instagram, los resultados del clustering pueden integrarse directamente en los sistemas de segmentación. Esto permite personalizar automáticamente las conversaciones según los grupos identificados. Además, el dendrograma es una herramienta visual valiosa para compartir hallazgos con equipos no técnicos, facilitando la toma de decisiones en estrategias de marketing y complementando otros métodos de segmentación de clientes.
DBSCAN propone un enfoque distinto al clustering tradicional. Este algoritmo no necesita que definas previamente cuántos grupos querés crear; en su lugar, identifica automáticamente las agrupaciones basándose en la densidad de los datos. En el mundo del e-commerce, esto significa que puede descubrir segmentos de clientes de forma natural, sin necesidad de estimar cuántos tipos de compradores existen.
El método se basa en localizar áreas con alta densidad de datos y separarlas de las regiones más dispersas. Por ejemplo, podría identificar un grupo de compradores frecuentes durante los fines de semana o usuarios que abandonan el carrito después de explorar varios productos, sin que tengas que definir esos segmentos de antemano. Esta capacidad única permite reconocer patrones complejos y grupos con formas diversas, como veremos a continuación.
Una ventaja destacada de DBSCAN es su habilidad para identificar clusters con formas irregulares, algo que otros algoritmos suelen pasar por alto, ya que tienden a buscar estructuras circulares o simétricas. En e-commerce, donde los comportamientos de los usuarios pueden ser muy variados, esta flexibilidad permite una segmentación más precisa, adaptándose a patrones complejos de compra o navegación.
DBSCAN también sobresale al gestionar valores atípicos, clasificando automáticamente como "ruido" aquellos puntos que no pertenecen a ningún cluster denso. Esto es crucial para evitar que outliers distorsionen los resultados. Al separar estos casos, los clusters obtenidos reflejan grupos genuinos de clientes con comportamientos similares. Esto no solo ayuda a detectar oportunidades, como clientes VIP con patrones inusuales, sino también a identificar posibles problemas en la experiencia de usuario.
Aunque DBSCAN puede trabajar con grandes conjuntos de datos, su rendimiento depende de cómo se implemente y de la correcta configuración de sus parámetros. En tiendas online con millones de clientes, puede ser necesario optimizar el algoritmo o usar procesamiento en paralelo para garantizar un rendimiento adecuado. Sin embargo, para volúmenes de datos moderados, sigue siendo una herramienta eficiente. Además, técnicas como la reducción de dimensionalidad (por ejemplo, utilizando PCA) pueden mejorar su desempeño sin comprometer la calidad de la segmentación.
DBSCAN se puede implementar fácilmente utilizando bibliotecas de Python como scikit-learn y se integra sin problemas con plataformas como Shopify, Tiendanube o VTEX a través de APIs. En sistemas como Burbuxa, que sincronizan datos en tiempo real sobre productos, pedidos y clientes, los resultados del clustering pueden alimentar directamente campañas de marketing o automatizar el soporte al cliente. Esto complementa las capacidades de otros algoritmos y refuerza la importancia de la segmentación para estrategias de marketing más efectivas.
Para optimizar el uso de DBSCAN, es fundamental ajustar correctamente dos parámetros clave:
Estos ajustes son esenciales para identificar segmentos relevantes y excluir valores atípicos que puedan interferir con los resultados.
Los Modelos de Mezcla Gaussiana (GMM) aplican un enfoque probabilístico para segmentar clientes en el ámbito del e-commerce. A diferencia de otros algoritmos que asignan a cada cliente un único segmento, GMM permite que un cliente pertenezca a varios grupos simultáneamente, asignando probabilidades a cada uno. Esto es particularmente útil en escenarios donde los patrones de compra tienden a superponerse, y los clientes exhiben comportamientos que encajan en múltiples segmentos.
El algoritmo modela los datos como una combinación de distribuciones gaussianas, donde cada una representa un posible cluster. Por ejemplo, un cliente podría tener un 70% de probabilidad de pertenecer al grupo de "compradores frecuentes" y un 30% al de "cazadores de ofertas". Este enfoque permite desarrollar estrategias de marketing más detalladas y personalizadas, adaptándose mejor a las características de cada cliente.
Una de las grandes ventajas de GMM es su capacidad para identificar clusters con formas más complejas, como elípticas, y tamaños variados. Esto lo diferencia de algoritmos como K-Means, que trabaja bajo la suposición de grupos esféricos y uniformes. En el contexto del e-commerce, donde los segmentos de clientes rara vez siguen patrones geométricos simples, esta flexibilidad es clave.
Por ejemplo, en una tienda de moda online, GMM podría identificar un grupo de "compradores estacionales de alta gama" que realizan compras esporádicas pero con montos elevados (superiores a $50.000 ARS por transacción). Al mismo tiempo, podría detectar otro segmento de "compradores regulares de precio medio" con un comportamiento más constante pero con montos menores. La capacidad de GMM para ajustar las matrices de covarianza le permite capturar estas diferencias de manera más precisa.
Aunque GMM puede manejar conjuntos de datos de tamaño moderado, su escalabilidad presenta limitaciones en comparación con algoritmos como K-Means. El proceso de Expectation-Maximization (EM), que es central en GMM, puede tornarse costoso en términos computacionales al trabajar con millones de clientes o múltiples variables. En estos casos, se recomienda reducir la dimensionalidad de los datos o emplear frameworks distribuidos para optimizar el rendimiento.
GMM muestra una robustez moderada frente a valores atípicos, superando a K-Means pero quedando por detrás de algoritmos como DBSCAN. Su enfoque probabilístico permite que ciertos puntos tengan bajas probabilidades de pertenecer a cualquier cluster, identificándolos como casos especiales sin afectar significativamente los resultados generales. Sin embargo, outliers extremos pueden distorsionar las estimaciones del modelo, por lo que es aconsejable realizar un preprocesamiento adecuado, como eliminar valores atípicos o usar métodos de estimación robusta de covarianza.
La implementación de GMM es sencilla gracias a bibliotecas como scikit-learn en Python, y sus resultados se integran fácilmente en plataformas de e-commerce como Shopify, Tiendanube o VTEX. Estas integraciones permiten personalizar estrategias de marketing utilizando APIs o middleware que sincronizan los clusters generados con los perfiles de clientes.
Por ejemplo, en sistemas como Burbuxa, que gestionan datos en tiempo real sobre productos, pedidos y clientes, las segmentaciones basadas en GMM pueden alimentar agentes de IA para personalizar mensajes de ventas, respuestas de soporte y campañas de marketing en canales como WhatsApp e Instagram. Clientes con alta probabilidad de "abandono de carrito" podrían recibir mensajes automáticos para incentivarlos a completar su compra, mientras que los "clientes leales" podrían recibir ofertas exclusivas, optimizando tanto las conversiones como la eficiencia del soporte.
Para aprovechar al máximo GMM en el e-commerce argentino, es crucial adaptar las características del modelo al contexto local. Esto incluye normalizar valores monetarios en pesos argentinos (ARS), usar formatos de fecha locales y actualizar regularmente el modelo para reflejar cambios en los hábitos de compra, las preferencias de pago y la estacionalidad del mercado. De esta forma, GMM se posiciona como una herramienta poderosa para complementar otras técnicas de segmentación y maximizar los resultados en un entorno competitivo.
Los Mapas Auto-Organizados (SOM) son un algoritmo de clustering basado en redes neuronales artificiales que permite visualizar datos complejos en un mapa bidimensional. A diferencia de otros métodos tradicionales, los SOM no necesitan que se defina de antemano el número de clusters, lo que los convierte en una herramienta útil para el análisis exploratorio de datos, como los comportamientos de clientes en e-commerce.
El proceso de los SOM utiliza un aprendizaje no supervisado para organizar patrones complejos en una grilla estructurada. Por ejemplo, una tienda de electrónicos podría emplear un SOM para identificar segmentos como "usuarios interesados en tecnología avanzada con alto presupuesto" o "cazadores de descuentos en productos básicos". Este enfoque puede descubrir relaciones complejas que otros algoritmos podrían pasar por alto. A continuación, se detallan aspectos clave como su escalabilidad y su desempeño frente a grandes volúmenes de datos.
Los SOM tienen una escalabilidad moderada cuando se trata de manejar grandes conjuntos de datos en e-commerce. Funciona bien con datasets de tamaño medio, pero su costo computacional crece a medida que aumenta la complejidad de la grilla y el volumen de datos. En tiendas online con millones de transacciones, es recomendable aplicar técnicas como la reducción de dimensionalidad o utilizar herramientas de computación distribuida para optimizar su desempeño.
Aunque en términos de eficiencia K-Means puede ser más rápido para datasets enormes, los SOM destacan por ofrecer una visualización bidimensional que facilita la interpretación. Esto permite a los equipos de marketing identificar patrones y tendencias de manera más intuitiva, lo que contribuye a decisiones más estratégicas.
Los SOM presentan una tolerancia moderada frente a valores atípicos gracias a su proceso de entrenamiento que suaviza las influencias extremas. Sin embargo, si los outliers son muy extremos, podrían generar nodos aislados o distorsionar los límites de los clusters. Por ello, es fundamental realizar un preprocesamiento adecuado para minimizar el impacto de estos valores en los resultados.
Una de las grandes ventajas de los SOM es su capacidad para identificar clusters con formas complejas o irregulares. A diferencia de K-Means, que asume grupos esféricos y uniformes, los SOM pueden adaptarse a patrones no convencionales, superpuestos o con geometrías inusuales. Esto resulta especialmente útil en el e-commerce, donde los comportamientos de los clientes rara vez siguen esquemas simples. Por ejemplo, un SOM podría descubrir un segmento de "compradores estacionales de productos premium" que solo se activa en fechas específicas, permitiendo detectar dinámicas de compra no evidentes con otros métodos.
La integración de SOM con plataformas como Shopify, Tiendanube o VTEX es posible, aunque requiere un nivel técnico más avanzado en comparación con algoritmos más sencillos. Estas plataformas permiten implementar SOM en estrategias automatizadas de marketing.
Los insights generados a través de SOM pueden incorporarse en estas herramientas para optimizar campañas dirigidas, recomendaciones personalizadas y estrategias de retención. En sistemas como Burbuxa, que habilitan la sincronización de datos en tiempo real y la automatización basada en IA, la integración de SOM se facilita aún más. Esto permite que las segmentaciones complejas alimenten agentes de IA para personalizar mensajes en canales como WhatsApp e Instagram, adaptándose a las particularidades del mercado argentino.
Por ejemplo, un flujo automatizado podría enviar descuentos personalizados a clientes del cluster "abandono de carrito frecuente", mientras que a los "compradores leales de alta frecuencia" se les ofrecen promociones exclusivas y soporte prioritario. Este enfoque no solo mejora las tasas de conversión, sino que también aumenta la satisfacción del cliente, maximizando los resultados para el e-commerce.
A continuación, se presenta una comparación detallada de cinco algoritmos clave, diseñada para ayudarte a elegir el más adecuado para tu e-commerce. Esta tabla resume las características principales de cada método, ofreciéndote una herramienta práctica para evaluar cuál se ajusta mejor a tus necesidades de segmentación de clientes.
| Algoritmo | Escalabilidad | Manejo de Outliers | Formas de Clusters | Número de Clusters | Interpretabilidad | Casos de Uso Ideales |
|---|---|---|---|---|---|---|
| K-Means | Muy eficiente con grandes datasets | Altamente sensible | Solo esféricos | Requiere definir K previamente | Alta – centroides claros | Segmentación RFM, campañas masivas |
| Clustering Jerárquico | Menos eficiente en grandes volúmenes | Moderado | Formas variadas | No requiere definir K | Muy alta – dendrogramas claros | Análisis exploratorio, tiendas pequeñas |
| DBSCAN | Adecuado para datasets medianos | Excelente – detecta ruido | Formas arbitrarias | Automático | Moderada | Detección de fraude, análisis de patrones anómalos |
| Gaussian Mixture Models | Moderado | Sensible | Elípticos | Requiere definir K previamente | Moderada – asigna probabilidades | Segmentación avanzada, análisis de preferencias |
| Self-Organizing Maps | Moderado | Moderado | Formas complejas | Automático | Baja – requiere experiencia | Visualización de patrones, análisis multidimensional |
Esta tabla es un punto de partida para entender las fortalezas y limitaciones de cada algoritmo. A continuación, se desarrollan algunos aspectos clave para ayudarte a tomar una decisión informada.
La velocidad de procesamiento varía significativamente entre algoritmos. Por ejemplo, K-Means es capaz de manejar millones de registros en cuestión de minutos, lo que lo convierte en una opción ideal para campañas masivas y estrategias de marketing de gran escala. Su eficiencia ayuda a reducir la complejidad operativa, especialmente en entornos donde el tiempo es crítico.
Si tu negocio maneja grandes volúmenes de datos, K-Means ofrece una combinación ideal de rapidez y resultados claros. Su facilidad de implementación lo hace perfecto para equipos de marketing que buscan resultados rápidos y comprensibles.
Por otro lado, si estás en una etapa de análisis exploratorio y no tenés una idea definida del número de segmentos necesarios, tanto DBSCAN como el Clustering Jerárquico son opciones destacadas. DBSCAN, en particular, sobresale en la detección de patrones de comportamiento inusuales o actividades fraudulentas, ya que clasifica automáticamente los datos atípicos como ruido.
Para estrategias más sofisticadas que requieran asignaciones probabilísticas, los Gaussian Mixture Models son ideales. Este enfoque permite no solo identificar a qué segmento pertenece un cliente, sino también con qué nivel de probabilidad, lo que resulta útil para personalizaciones avanzadas y recomendaciones más precisas.
La facilidad de integración depende del stack tecnológico que utilices. Tanto K-Means como DBSCAN tienen un amplio soporte en bibliotecas estándar y ofrecen integración vía APIs.
En plataformas avanzadas como Burbuxa, que sincronizan datos en tiempo real y automatizan la segmentación, podés optimizar el uso de algoritmos según el contexto. Por ejemplo, K-Means puede emplearse para segmentación general de clientes, mientras que DBSCAN es útil para identificar comportamientos atípicos que requieran atención específica.
Si tu equipo tiene poca experiencia técnica, empezá con K-Means, ya que es fácil de implementar y entender. Si contás con un equipo más experimentado, combinar diferentes métodos puede darte una visión más completa. Por ejemplo, podés usar Clustering Jerárquico para obtener una visión general de la estructura de tus clientes y luego aplicar DBSCAN para identificar nichos específicos o comportamientos inusuales que demanden estrategias personalizadas.
Estos enfoques te permitirán alinear tu estrategia de segmentación con los objetivos específicos de tu e-commerce, maximizando el impacto de tus campañas de marketing.
Seleccionar el algoritmo de clustering adecuado para tu e-commerce no es una tarea trivial. Depende de varios factores clave: tus objetivos comerciales, el tipo y la cantidad de datos que manejás, y los recursos técnicos con los que cuenta tu equipo. Vamos a desglosar cada uno de estos puntos para ayudarte a tomar la mejor decisión.
Antes de explorar opciones, es fundamental tener claro qué querés lograr. Si buscás personalizar campañas masivas, K‑Means es una excelente opción gracias a su rapidez y capacidad para manejar grandes volúmenes de datos. Si tus datos tienen muchos valores atípicos, DBSCAN es más efectivo para manejar ruido y detectar patrones irregulares. Por otro lado, si necesitás estrategias más avanzadas que incluyan asignaciones probabilísticas y niveles de afinidad, los Gaussian Mixture Models pueden ser la herramienta que estás buscando.
El éxito del clustering depende en gran medida de la calidad y estructura de tus datos. Si trabajás con datos numéricos bien organizados y clusters claramente definidos, K‑Means será una solución eficiente. Sin embargo, si tus datos contienen muchos valores atípicos o estructuras más complejas, DBSCAN puede ofrecer mejores resultados al manejar este tipo de desafíos. Además, el volumen de datos es un factor importante: mientras que K‑Means puede procesar millones de registros rápidamente, algoritmos como el clustering jerárquico pueden volverse demasiado lentos y costosos en términos computacionales para grandes bases de datos.
El nivel de experiencia técnica de tu equipo también influye en la elección del algoritmo. Si tu equipo tiene menos experiencia, empezar con K‑Means puede ser una buena idea, ya que es fácil de implementar y sus resultados son fáciles de interpretar y aplicar. Para equipos más avanzados, combinar métodos puede ser una estrategia poderosa: por ejemplo, usar clustering jerárquico para obtener una visión general de la estructura de clientes y luego aplicar DBSCAN para identificar segmentos más específicos.
Implementar algoritmos de clustering manualmente puede ser complicado y llevar mucho tiempo. Herramientas como Burbuxa simplifican este proceso al integrar análisis de clustering directamente en flujos automatizados de ventas y marketing en plataformas como WhatsApp e Instagram. Estas herramientas permiten segmentar a los clientes según variables como frecuencia de compra, historial de pedidos y nivel de interacción, facilitando la ejecución de campañas personalizadas de forma automática.
Una vez que hayas implementado el algoritmo, es crucial validar su desempeño. Utilizá métricas estadísticas como el coeficiente de silueta y KPIs de negocio como la tasa de conversión, el valor promedio de los pedidos y la retención de clientes. Por ejemplo, un retailer de moda en Argentina que utilizó Burbuxa logró segmentar a sus clientes según su historial de compras y nivel de engagement. Al automatizar campañas en WhatsApp para cada segmento, experimentó un aumento del 20% en la recuperación de carritos abandonados y un 15% en compras repetidas en solo tres meses.
Pero el trabajo no termina ahí. Los comportamientos de los clientes cambian constantemente, sobre todo en el dinámico mundo del e-commerce. Por eso, es esencial monitorear y ajustar los algoritmos periódicamente para mantener la relevancia de los segmentos y la efectividad de las campañas. Integrá estas decisiones con las estrategias automatizadas que mencionamos en secciones anteriores para potenciar tus resultados al máximo.
Seleccionar el algoritmo de clustering adecuado para tu tienda online implica considerar varios aspectos: el tamaño de tu base de datos, los objetivos específicos de segmentación y las particularidades de tus clientes. Aquí es donde Burbuxa se convierte en un aliado clave, ya que utiliza un sistema de inteligencia artificial avanzado diseñado especialmente para marcas de comercio electrónico.
Gracias a Burbuxa, no solo podrás segmentar a tus clientes con mayor precisión, sino también mejorar la interacción y las tasas de conversión en plataformas como WhatsApp e Instagram. Su enfoque automatizado y en tiempo real te permite obtener resultados rápidos y efectivos, impulsando así el rendimiento de tus ventas.
DBSCAN es un algoritmo de clustering que resulta especialmente útil cuando se trabaja con datos complejos, como los que se encuentran en el e-commerce. Una de sus principales ventajas es que no exige definir de antemano la cantidad de clusters, lo que lo hace perfecto para analizar patrones de compra que pueden ser desconocidos o cambiar con el tiempo. Además, tiene la capacidad de identificar clusters de cualquier forma, incluso cuando los datos contienen ruido o valores atípicos, algo habitual en el comportamiento de los clientes.
Gracias a estas características, DBSCAN se convierte en una herramienta valiosa para segmentar clientes y descubrir grupos con características comunes, como hábitos de compra o preferencias. Esto permite personalizar estrategias de marketing y mejorar significativamente la experiencia del cliente.
Los resultados del clustering te ayudan a dividir a tus clientes en grupos específicos basados en su comportamiento o preferencias. Con Burbuxa, podés usar estos segmentos para enviar mensajes personalizados en momentos clave, como promociones especiales o eventos destacados. Esto no solo mejora la experiencia del cliente, sino que también puede aumentar las tasas de conversión.
Además, al incorporar los datos de clustering en la plataforma, tenés la posibilidad de automatizar campañas dirigidas que se adapten a las características de cada grupo. Esto permite que la comunicación sea mucho más precisa y relevante para cada segmento.