
Cómo integrar anonimización en pipelines de datos
Proteger los datos personales en tus pipelines de datos no es solo una obligación legal, sino una práctica clave para evitar riesgos. Este artículo explica cómo anonimizar información sensible en procesos ETL/ELT, cumpliendo normativas como GDPR y LGPD, y preservando la utilidad de los datos para análisis y machine learning.
Puntos principales:
- Anonimización vs. Pseudonimización: La anonimización es irreversible y exime a los datos de ser considerados personales; la pseudonimización es reversible y requiere más controles.
- Técnicas comunes: Hashing, tokenización, privacidad diferencial y generalización son opciones según el caso de uso.
- Regulaciones: La GDPR exige que los datos anonimizados sean irreversibles y que se consideren cuasi-identificadores (edad, ubicación, etc.).
- Herramientas útiles: GDPR Dump, AWS Glue, y Google Cloud Sensitive Data Protection son opciones para automatizar la anonimización.
- Mejores prácticas: Implementar la anonimización en el origen, validar la utilidad de los datos y monitorear riesgos de re-identificación.
La anonimización no solo protege la privacidad de los usuarios, sino que también asegura que los datos puedan ser utilizados de forma segura y conforme a la ley.
Guía para la anonimización de datos: nueva edición, experiencias y aplicaciones prácticas
Evaluando tu pipeline de datos actual
Antes de implementar procesos de anonimización, es fundamental tener un panorama claro de los datos que atraviesan tu pipeline y los puntos donde podrían estar en riesgo. Un dato alarmante: el 87% de la población de Estados Unidos puede ser identificada con solo tres elementos: código postal, género y fecha de nacimiento. En Argentina, combinaciones como barrio, edad y género pueden ser igual de reveladoras.
Revisando tus flujos de datos
El primer paso es identificar los diferentes tipos de datos que manejás: identificadores directos como DNI, email o nombre, y cuasi-identificadores como edad exacta, ubicación específica o fecha de nacimiento. Por ejemplo, un cliente de 34 años que vive en Palermo y realizó una compra el 15 de marzo de 2026 podría parecer anónimo, pero esa información cruzada con datos públicos podría identificarlo fácilmente.
Para entender mejor tu pipeline, documentá los datos en tres estados: en reposo (bases de datos y contenedores), en tránsito y en uso (análisis o procesos de machine learning). Actualmente, existen herramientas avanzadas capaces de detectar más de 100 tipos de información sensible ("infoTypes"), rastreando patrones en datos estructurados y no estructurados. Sin embargo, no subestimes la importancia de revisar campos de texto libre, logs y descripciones, ya que suelen contener datos sensibles que los sistemas automáticos pueden pasar por alto.
"La seguridad de datos no admite procesos manuales. Los procesos manuales incrementan el riesgo de incumplimiento y retrasan proyectos críticos." - Gigantics
Con esta información en mano, podés determinar en qué puntos del pipeline es más efectivo integrar la anonimización.
Dónde agregar anonimización
Una vez que tengas tus flujos de datos bien mapeados, el siguiente paso es decidir dónde aplicar la anonimización para maximizar su efectividad y garantizar el cumplimiento de normativas. Hacerlo en el origen, es decir, en el punto de ingesta, reduce significativamente los riesgos al evitar que datos sensibles circulen sin protección. En pipelines ETL, es recomendable anonimizar durante la etapa de transformación, antes de cargar los datos. En arquitecturas ELT más modernas, donde los datos se cargan antes de transformarse, podés implementar enmascaramiento dinámico directamente en el data warehouse.
Para proyectos de machine learning, el momento ideal para anonimizar es durante el preprocesamiento, antes de dividir los datos en conjuntos de entrenamiento y prueba. Si lo hacés después de esta división, podrías dejar expuesta información sensible en alguno de los conjuntos.
En cuanto a las técnicas, podés optar por enmascaramiento estático - ideal para entornos de desarrollo o análisis, ya que transforma los datos de manera permanente - o enmascaramiento dinámico, que protege los datos en tiempo real durante las consultas. En ambos casos, es fundamental preservar la integridad referencial, es decir, asegurarte de que las relaciones entre tablas y las uniones (joins) sigan funcionando correctamente después de aplicar las transformaciones.
Técnicas de anonimización que podés usar
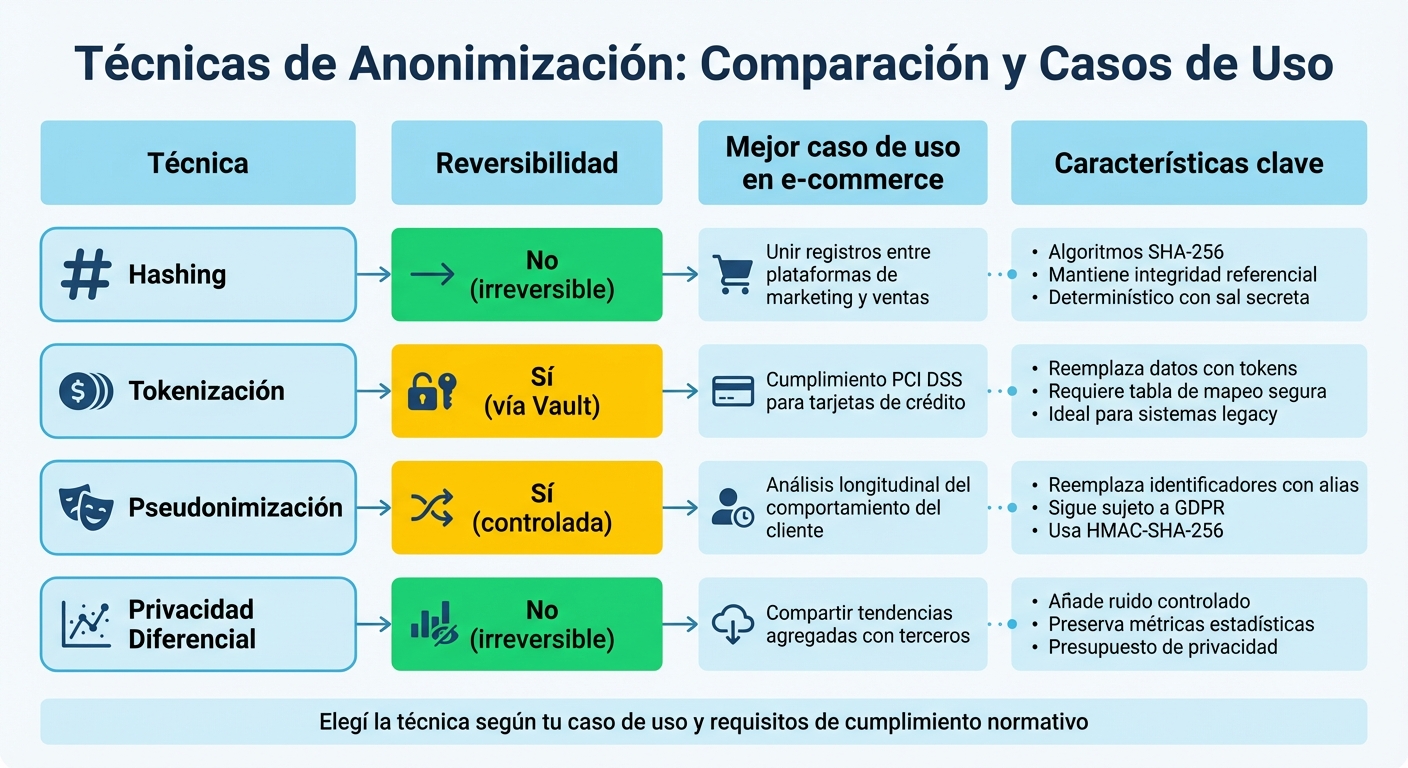
Comparación de técnicas de anonimización de datos: reversibilidad y casos de uso
Con los puntos de inserción ya definidos, es momento de elegir la técnica de anonimización que mejor se ajuste a tus necesidades. Una vez identificados los puntos críticos en tu pipeline, seleccioná la opción más adecuada.
Hashing y tokenización
El hashing es un método unidireccional que convierte datos en una cadena de longitud fija utilizando algoritmos como SHA-256. Esto permite mantener la integridad referencial entre sistemas sin revelar los datos originales. Por ejemplo, si querés unir registros de clientes entre tu plataforma de marketing y tu tienda, podés aplicar hashing determinístico con una sal secreta al email del cliente. Así, el mismo email genera siempre el mismo hash, permitiendo realizar joins entre tablas sin exponer la identidad real.
Por otro lado, la tokenización reemplaza datos sensibles con "tokens", que son equivalentes no sensibles. A diferencia del hashing, la tokenización es reversible: los sistemas autorizados pueden recuperar los datos originales mediante una tabla de mapeo segura o un vault. Esto es especialmente útil para cumplir con requisitos como PCI DSS al procesar y almacenar información de tarjetas de crédito en e-commerce.
"La seudonimización mantiene una tabla de mapeo entre conjuntos de datos originales y alterados, lo que permite a las partes autorizadas volver a identificar la información cuando sea necesario." - Syntho
Si trabajás con sistemas legacy que necesitan formatos específicos (como la estructura de 16 dígitos de una tarjeta de crédito), podés usar Format-Preserving Encryption (FPE). Si no hay restricciones de formato, la Deterministic Encryption (DE) ofrece una alternativa más segura.
Pasemos ahora a la privacidad diferencial, ideal para proteger datos agregados.
Privacidad diferencial
La privacidad diferencial funciona añadiendo ruido controlado a los datos, de modo que la inclusión o exclusión de un individuo no afecte significativamente los resultados del análisis. Esta técnica es irreversible y está diseñada para extraer valor de datos agregados.
Es especialmente útil cuando necesitás compartir tendencias o patrones con socios externos. Por ejemplo, al analizar métricas de e-commerce como el ticket promedio o la edad de los clientes, podés agregar ruido aleatorio a los valores individuales mientras preservás métricas clave como la media y la desviación estándar. Herramientas como Google Differential Privacy o ARX pueden ayudarte a implementarla, ofreciendo además la posibilidad de gestionar el "presupuesto de privacidad", que regula el equilibrio entre utilidad y riesgo.
Ahora, consideremos la pseudonimización como una alternativa para análisis más detallados.
Pseudonimización
La pseudonimización reemplaza identificadores directos con alias o identificadores sustitutos. A diferencia de la anonimización irreversible, esta técnica es reversible mediante una clave o tabla de mapeo, lo que significa que los datos siguen sujetos a regulaciones como el GDPR.
Es una excelente opción para realizar análisis longitudinales del comportamiento del cliente sin comprometer su identidad real. Por ejemplo, podés rastrear el historial de compras de un cliente a lo largo del tiempo utilizando un ID pseudónimo, sin almacenar directamente datos sensibles como el DNI o el email en la base de datos analítica. Los identificadores sensibles y sus mapeos deben almacenarse en un vault de identidad altamente protegido.
En pipelines en tiempo real, aplicá la pseudonimización desde la etapa inicial (durante la ingesta o en el edge) para limitar la exposición de los datos mientras se transmiten. Usar hashing determinístico con sal (como HMAC-SHA-256) garantiza que el mismo input siempre produzca el mismo pseudónimo, permitiendo realizar joins en bases de datos sin revelar la identidad original.
| Técnica | Reversibilidad | Mejor caso de uso en e-commerce |
|---|---|---|
| Hashing | No | Unir registros entre plataformas de marketing y ventas |
| Tokenización | Sí (vía Vault) | Cumplimiento PCI DSS para tarjetas de crédito |
| Pseudonimización | Sí (controlada) | Análisis longitudinal del comportamiento del cliente |
| Privacidad diferencial | No | Compartir tendencias agregadas con terceros |
Herramientas y plataformas para anonimización
Seleccionar la herramienta correcta puede ser clave para garantizar la seguridad de un pipeline y evitar vulnerabilidades. Es importante optar por plataformas que se integren fácilmente con tu infraestructura y cumplan con normativas como el GDPR y la Ley de Protección de Datos Personales. A continuación, te mostramos algunas opciones destacadas para diferentes etapas del pipeline.
Plataformas de integración de datos
Si gestionás un e‑commerce autónomo y necesitás exportar bases de datos para entornos de desarrollo, GDPR Dump es una alternativa interesante. Esta herramienta gratuita y de código abierto está diseñada específicamente para plataformas como Magento, Drupal y Shopware. Con GDPR Dump, podés configurar reglas de anonimización a través de archivos YAML, lo que permite definir qué tablas exportar y cómo transformar campos sensibles como correos electrónicos, nombres o números de tarjeta. Por ejemplo, podrías elegir exportar solo los pedidos de los últimos 60 días, manteniendo las bases de desarrollo más livianas y relevantes.
Servicios de procesamiento de datos en la nube
En el ámbito del e-commerce, manejar grandes volúmenes de datos es esencial para las operaciones y los análisis. Herramientas como AWS Glue y PySpark son ideales para anonimizar grandes cantidades de información en la nube mediante scripts en Python. Glue, además, se integra de manera nativa con AWS, facilitando la automatización de transformaciones, mientras que PySpark ofrece escalabilidad para procesar datos masivos. Estas herramientas son especialmente útiles para gestionar catálogos, historiales de compras e inventarios.
Otra opción es Google Cloud Sensitive Data Protection, que cuenta con más de 100 clasificadores integrados para detectar automáticamente datos sensibles como DNIs, correos electrónicos o números de tarjeta. Además, permite separar la configuración de seguridad de la implementación, lo que significa que los equipos de seguridad pueden gestionar claves y métodos de cifrado, mientras los desarrolladores se concentran en construir el pipeline.
APIs de anonimización
Las APIs de anonimización, como Nymiz, ofrecen una integración directa mediante API. Nymiz, por ejemplo, puede identificar y anonimizar datos personales en hasta 102 idiomas, lo que la convierte en una solución ideal para empresas que operan en mercados internacionales.
En entornos modernos de CI/CD, Gigantics destaca por su capacidad de versionar reglas de anonimización a través de archivos YAML. Esto resulta especialmente valioso para mantener un enfoque ágil en DevOps.
"La ausencia de estas capacidades industrializadas convierte el aprovisionamiento de datos en un proceso manual basado en tickets, difícil de auditar y vulnerable a cambios de esquema" - Sara Codarlupo, Gigantics
| Herramienta | Automatización | Mejor caso de uso en e‑commerce | Costo |
|---|---|---|---|
| GDPR Dump | CLI + YAML | Dumps de Magento/Shopware para desarrollo | Gratis (código abierto) |
| AWS Glue | Jobs programados | Procesamiento masivo de catálogos e inventarios | Por uso (AWS) |
| Google Cloud SDP | Integración nativa GCP | Identificación automática de PII a gran escala | Por uso (GCP) |
| Nymiz | API/SaaS | Anonimización multiidioma para mercados globales | Suscripción o volumen |
| Gigantics | API-first (CI/CD) | DevOps ágil con versionado de reglas | Por instancias/volumen |
Cómo implementar anonimización paso a paso
Una vez que hayas seleccionado las herramientas adecuadas, el siguiente paso es integrar la anonimización en tu pipeline a través de tres etapas principales: instalación y configuración, definición de reglas y validación continua. Aquí te explicamos cómo hacerlo.
Instalación y configuración de herramientas
El primer paso es analizar el esquema de tu base de datos para identificar elementos clave como claves primarias, foráneas y restricciones. Esto se puede hacer mediante comandos como SHOW CREATE TABLE o consultando el information_schema. Luego, seleccioná el método de transformación más adecuado según el tipo de datos: por ejemplo, transformaciones específicas para datos estructurados como nombres, correos electrónicos o DNI, y otras para texto libre o logs con información sensible.
Para integrar las herramientas en tu pipeline de CI/CD, considerá usar arquitecturas API-first o configuraciones YAML que puedan versionarse fácilmente. Es importante evitar errores comunes, como almacenar claves criptográficas en texto plano. Si optás por pseudonimización reversible, asegurate de gestionar estas claves mediante servicios seguros como Cloud KMS.
Una vez que las herramientas estén configuradas, el siguiente paso es establecer reglas claras para la anonimización.
Definición de reglas de anonimización
Es fundamental diferenciar entre dos tipos de identificadores: directos (como nombres, DNI o correos electrónicos) e indirectos o cuasi-identificadores (como edad, código postal o hábitos de compra). Para mantener la integridad referencial en bases de datos relacionales, podés usar técnicas como el hashing determinista o tablas de mapeo. Estas técnicas aseguran que un mismo valor de entrada siempre genere el mismo token, permitiendo preservar las relaciones entre tablas, incluso en entornos de prueba.
Automatizá estas reglas utilizando archivos YAML. Esto no solo simplifica las auditorías, sino que también facilita la reversión si es necesario.
"La anonimización es la transformación irreversible de datos personales que elimina o transforma atributos identificadores hasta que la re-identificación sea inviable." - Gigantics
Pruebas y monitoreo de resultados
Para garantizar que la integración no afecte el funcionamiento del pipeline, es necesario validar dos aspectos clave: utilidad (que los datos sigan siendo funcionales para análisis o aplicaciones) y exposición (que no queden identificadores residuales). Por ejemplo, en proyectos de machine learning, podés comparar métricas como precisión y recall entre modelos entrenados con datos originales y anonimizados, evaluando así el impacto de la anonimización en los resultados.
Configurá un pipeline secundario automatizado que escanee las salidas en busca de información sensible. Herramientas como Google Cloud Sensitive Data Protection ofrecen más de 100 detectores de infoTypes para garantizar que no quede información identificable. Además, mantené un registro detallado de los cambios realizados: qué campos se modificaron, qué algoritmos se aplicaron y la versión del esquema utilizada. Esto es esencial para cumplir con normativas como el GDPR o la Ley de Protección de Datos Personales.
| Técnica | Reversibilidad | Caso de uso | Impacto en utilidad |
|---|---|---|---|
| Masking | Parcial/No | Testing/UI | Alto (preserva formato) |
| Hashing | No (salvo mapeo) | Integridad/Joins | Medio |
| Generalización | No | Análisis estadístico | Bajo (reduce precisión) |
| Datos sintéticos | No | Entrenamiento ML | Alto (preserva patrones) |
| Tokenización | Sí (con clave) | Operacional/Transaccional | Alto |
Mantener y monitorear la anonimización
Una vez que la anonimización forma parte de tu flujo de trabajo, el desafío es garantizar que siga siendo efectiva y cumpla con las normativas vigentes. Esto requiere un enfoque estructurado que combine monitoreo constante, trazabilidad y gobernanza activa.
Seguimiento del linaje y calidad de datos
Para mantener la seguridad y el cumplimiento, es clave implementar un proceso automatizado de validación que revise continuamente que los datos procesados no contengan información identificable. Esto asegura que las reglas definidas durante la implementación se respeten a lo largo del tiempo.
También es esencial evaluar cómo la anonimización afecta la utilidad de los datos. Por ejemplo, podés analizar métricas como precisión y recall en modelos de machine learning, comparando el rendimiento entre datasets originales y anonimizados. Si detectás una caída considerable en el desempeño, tal vez sea necesario ajustar las técnicas empleadas o adoptar métodos más avanzados, como la privacidad diferencial.
Para facilitar la gestión, utilizá configuraciones Dataset-as-Code en archivos YAML. Esto permite versionar las políticas de anonimización y mantener una trazabilidad completa dentro de flujos GitOps. Además, registrá cada transformación aplicada, incluyendo el momento y la razón detrás de cada cambio, asegurando un control exhaustivo del linaje de los datos.
Configuración de alertas para riesgos de privacidad
Una vez que el linaje y la calidad están bajo control, es fundamental adelantarse a posibles riesgos. Configurá alertas que identifiquen anomalías o amenazas de re-identificación en tiempo real. Por ejemplo, si se agrega un campo con información sensible a tu base de datos, el sistema debería detectarlo automáticamente y aplicar las reglas de anonimización necesarias. Herramientas basadas en IA, como Google Sensitive Data Protection, son útiles para identificar y clasificar PII (información personal identificable), ofreciendo más de 100 detectores de infoTypes.
Un punto clave es la rotación de claves de cifrado, ya que puede afectar los mapeos existentes. Planificá este proceso con anticipación configurando alertas que te avisen antes de que las claves expiren. Esto te permitirá realizar la rotación de manera controlada y sin comprometer la integridad de los datos.
Buenas prácticas para el éxito a largo plazo
Aunque la automatización es fundamental, las revisiones manuales siguen siendo necesarias para garantizar que todo funcione correctamente. Mantené registros de auditoría detallados, documentando cada ejecución de anonimización, quién accedió a los datos y cuándo. Esto es crucial para cumplir con normativas como GDPR, HIPAA o la Ley de Protección de Datos Personales en Argentina. Además, realizá inspecciones humanas periódicas, especialmente después de cambios en los esquemas de datos o actualizaciones de herramientas.
Para minimizar riesgos, es recomendable anonimizar los datos cerca de su origen. Esto reduce la exposición a posibles vulnerabilidades y simplifica los procesos en etapas posteriores. Por último, adoptá un enfoque de mejora continua: revisá regularmente las técnicas de anonimización, ajustándolas según los cambios en regulaciones o amenazas emergentes, para mantener la protección de los datos siempre actualizada.
Conclusión
La anonimización de datos no es un esfuerzo único; es un proceso constante que requiere planificación, herramientas adecuadas y monitoreo continuo. Para empezar, es clave identificar los identificadores directos (como nombres o DNI) y los cuasi-identificadores (como combinaciones de edad, ubicación y fechas) que podrían facilitar la re-identificación. Una vez definidos, elegí las técnicas más adecuadas según el uso final de los datos: opciones como el hashing, la tokenización, la privacidad diferencial o la generalización pueden ser útiles dependiendo del contexto.
La automatización juega un papel crucial. Integrá herramientas API-first en los flujos de CI/CD para garantizar que cada movimiento de datos esté protegido desde su origen. Como explica Sara Codarlupo, especialista de marketing en Gigantics:
"La anonimización de datos es el recurso técnico clave para desacoplar la utilidad de la información de su carga de privacidad".
Esto implica que es posible aprovechar los datos para análisis y desarrollo sin comprometer la privacidad de los usuarios.
Además, es importante validar que los datos anonimizados sigan siendo útiles para el análisis y no contengan información identificable. Compará el rendimiento de modelos y utilizá herramientas de validación automatizadas para asegurarte de que cumplen con los estándares deseados. Este enfoque asegura que tus datos sean seguros y confiables a lo largo del tiempo.
El cumplimiento normativo también es un pilar esencial. Leyes como el GDPR, la HIPAA, el CCPA o la Ley de Protección de Datos Personales en Argentina exigen trazabilidad completa. Por ello, mantené registros detallados de cada proceso de anonimización y configurá alertas que detecten riesgos de privacidad en tiempo real. La efectividad de estas medidas se mide a través del riesgo residual, que debe ser gestionado de forma constante.
Por último, adoptá un enfoque dinámico y de mejora continua. Las regulaciones evolucionan, las amenazas cambian y los volúmenes de datos crecen. Revisá periódicamente tus técnicas, ajustá las reglas cuando sea necesario y aplicá la anonimización lo más cerca posible del origen de los datos para minimizar riesgos. Con estas prácticas, no solo protegés la privacidad de tus usuarios, sino que también sentás las bases para el crecimiento sostenible de tu organización.
FAQs
¿Cómo sé si debo pseudonimizar o anonimizar?
La anonimización convierte los datos de manera que no puedan asociarse a una persona específica bajo ningún contexto, haciéndolo irreversible. Esto es ideal para garantizar la privacidad total, reducir al mínimo los riesgos de reidentificación y cumplir con normativas estrictas.
Por otro lado, la seudonimización reemplaza los identificadores personales por seudónimos, manteniendo la posibilidad de reidentificar los datos bajo condiciones controladas. Esta técnica es útil cuando se necesita preservar cierta funcionalidad de los datos mientras se minimizan los riesgos de exposición.
En resumen: utiliza anonimización si tu prioridad es la privacidad absoluta. Opta por seudonimización si necesitas un equilibrio entre privacidad y utilidad de los datos.
¿Dónde es mejor aplicar la anonimización: ingesta, ETL/ELT o warehouse?
Es recomendable realizar la anonimización durante la etapa de ingesta o en el preprocesamiento de datos (ETL/ELT). Esto asegura que la privacidad se proteja desde el principio del proceso. Sin embargo, en ciertos casos, también es posible aplicar la anonimización directamente en el warehouse. La decisión dependerá de encontrar un equilibrio adecuado entre proteger la privacidad y mantener la utilidad de los datos.
¿Cómo valido que no haya riesgo de reidentificación sin perder utilidad?
Para proteger los datos y mantener su utilidad, podés aplicar técnicas como pseudonimización, enmascaramiento y generalización. Un buen punto de partida es realizar un análisis inicial de los datos para detectar posibles riesgos de reidentificación.
Además, considerá usar métodos más avanzados, como perturbación o pseudonimización mejorada, según lo requiera el nivel de sensibilidad de los datos. Una vez implementadas estas técnicas, es fundamental validar su efectividad mediante pruebas específicas de reidentificación.
Si los resultados no son los esperados, ajustá las estrategias hasta encontrar un equilibrio adecuado entre la protección de la privacidad y la funcionalidad de los datos. Este enfoque iterativo asegura que los datos sean seguros sin perder su valor práctico.
