Las métricas de rendimiento de APIs son claves para evaluar la velocidad, confiabilidad y escalabilidad de sistemas que sostienen plataformas como Shopify, Tiendanube o VTEX. Una API lenta o inestable puede afectar la experiencia del usuario, provocar carritos abandonados y generar pérdidas económicas. Algunos puntos fundamentales:
Para optimizar el rendimiento, se recomienda usar caché, compresión de datos y monitoreo en tiempo real con herramientas como Datadog o Prometheus. Además, implementar pruebas de carga y alertas específicas por endpoint permite anticipar problemas y mejorar la experiencia del usuario.
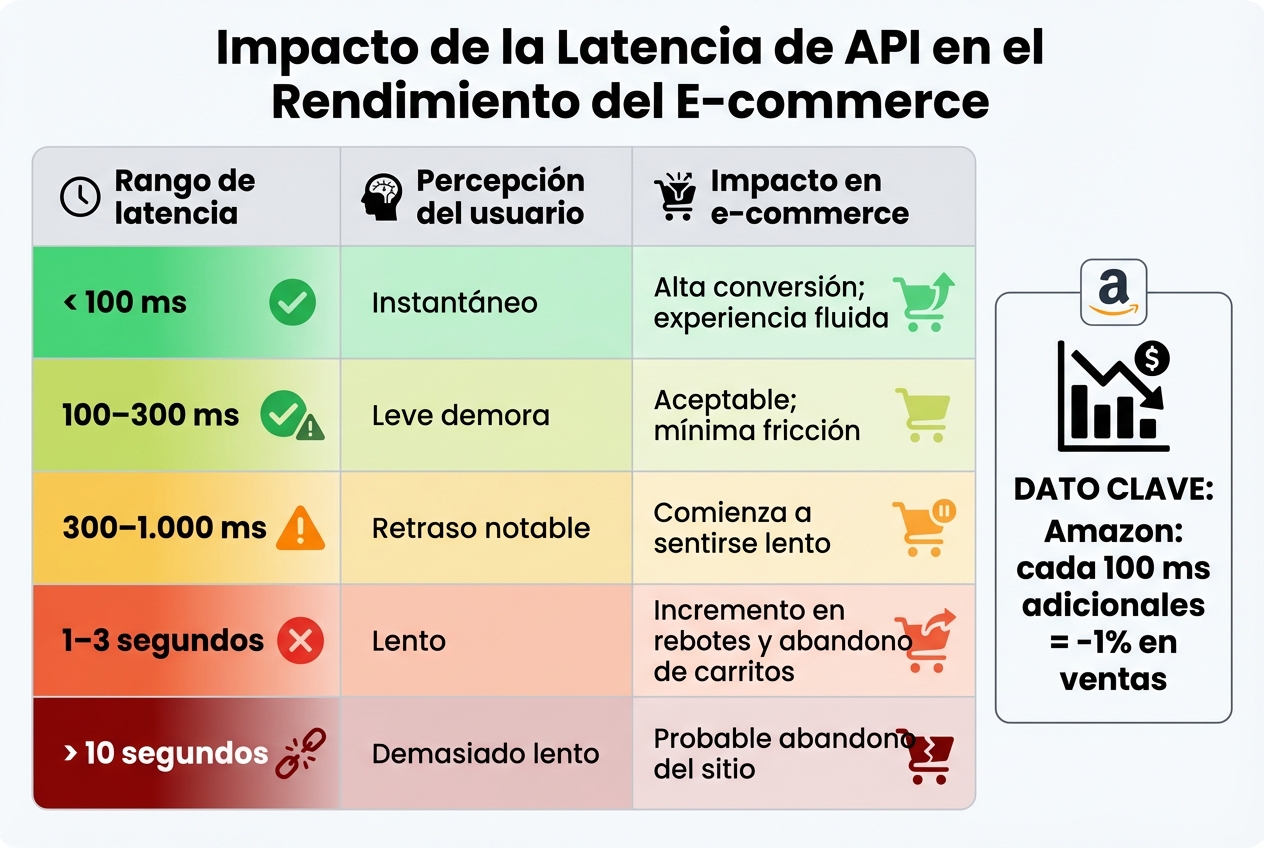
Tabla de latencia de APIs y su impacto en conversiones de e-commerce
Las métricas básicas son esenciales para evaluar la salud y eficiencia de las integraciones en e-commerce. Funcionan como una brújula para medir en tiempo real el impacto y valor de las APIs.
El tiempo de respuesta, también conocido como latencia, mide cuánto tarda una API en procesar una solicitud y devolver una respuesta completa. Este indicador es clave: una latencia alta puede perjudicar la experiencia del usuario y reducir las tasas de conversión. Un ejemplo claro es el caso de , que descubrió que cada 100 ms adicionales en la latencia resultan en una caída del 1% en las ventas.
Los usuarios perciben la latencia de diferentes maneras. Respuestas menores a 100 ms suelen sentirse "instantáneas", mientras que demoras superiores a 1 segundo generan frustración. Sin embargo, los promedios no siempre cuentan toda la historia; por eso, es importante monitorear percentiles como el P95 y P99, que reflejan el rendimiento para los usuarios con las peores experiencias.
| Rango de latencia | Percepción del usuario | Impacto en e-commerce |
|---|---|---|
| < 100 ms | Instantáneo | Alta conversión; experiencia fluida |
| 100–300 ms | Leve demora | Aceptable; mínima fricción |
| 300–1.000 ms | Retraso notable | Comienza a sentirse lento |
| 1–3 segundos | Lento | Incremento en rebotes y abandono de carritos |
| > 10 segundos | Demasiado lento | Probable abandono del sitio |
Para mejorar el tiempo de respuesta, se pueden aplicar varias estrategias. La implementación de caché en múltiples niveles, como CDNs para activos estáticos y Redis para datos consultados frecuentemente, es un buen punto de partida. También es útil procesar tareas no críticas de manera asíncrona, como el envío de correos de confirmación, para liberar recursos y reducir tiempos de espera. Además, la compresión de respuestas mediante herramientas como Gzip ayuda a disminuir los tiempos de transferencia al reducir el tamaño de los datos enviados.
El Time to First Byte (TTFB) mide el tiempo que transcurre desde que el cliente envía una solicitud hasta que recibe el primer byte de respuesta del servidor. Este indicador es especialmente relevante para aplicaciones en tiempo real, ya que refleja la latencia inicial de la red.
Un TTFB elevado puede hacer que las interfaces se sientan lentas, afectando negativamente la experiencia del usuario y aumentando el riesgo de abandono de carritos. En escenarios donde la sincronización en tiempo real es crucial, como la actualización de inventarios, una latencia alta puede generar discrepancias en los datos. Para reducir el TTFB, es recomendable usar CDNs para almacenar en caché activos estáticos cerca del cliente y emplear caché en memoria como Redis o Memcached para evitar consultas lentas a la base de datos. Además, monitorear valores atípicos puede ayudar a identificar problemas que afecten a ciertos usuarios.
La tasa de errores mide el porcentaje de solicitudes fallidas en relación con el total de solicitudes realizadas. Mantener este indicador por debajo del 1% es crucial para garantizar la estabilidad de procesos críticos como la sincronización de inventarios y el checkout.
Los errores suelen clasificarse en dos categorías principales:
"Si el número de llamadas está disminuyendo y el número de errores está creciendo, pueden ser las primeras señales de un posible abandono." – Blobr
Es fundamental monitorear por separado los errores 4xx y 5xx para identificar si los problemas son producto de fallos en la integración del cliente o de la infraestructura del servidor. Además, proporcionar mensajes de error claros en las respuestas de la API facilita la resolución rápida de incidentes.
Dado que las APIs de e-commerce suelen depender de servicios externos, como pasarelas de pago o proveedores de logística, fallos en estos sistemas pueden provocar errores en cascada. Para mitigar este riesgo, se pueden implementar patrones como circuit breakers, que detectan fallos en servicios de terceros y evitan llamadas repetidas a sistemas inestables.
Estas métricas son fundamentales para construir estrategias de optimización que aseguren un rendimiento sólido y una experiencia de usuario satisfactoria.
Cuando ya se tienen controladas las métricas básicas, llega el momento de analizar cómo una API se comporta bajo condiciones extremas. Las métricas avanzadas ayudan a determinar si un sistema puede manejar el crecimiento del negocio y responder a picos de tráfico sin colapsar.
El throughput, medido en Requests Per Second (RPS), refleja la cantidad de solicitudes que una API puede procesar por segundo. Este dato define el límite de rendimiento del sistema: el punto en el que, al aumentar la carga, el rendimiento comienza a degradarse.
"RPS es una de las métricas de rendimiento esenciales... Simplemente nos dice cuántas solicitudes por segundo puede manejar el sistema bajo prueba." – Luděk Nový
En el ámbito del e-commerce, el throughput es clave durante eventos de alta demanda, como promociones especiales. Por ejemplo, un sistema que trabaja a 100 RPS con una latencia de 8 ms podría escalar linealmente hasta 500 RPS. Sin embargo, al alcanzar 750 usuarios concurrentes, el rendimiento se estanca en 530 RPS y la latencia aumenta. Esto indica que el sistema ha alcanzado su límite.
Para evitar estos cuellos de botella, es útil implementar políticas de auto-escalado, como las que ofrece Kubernetes Horizontal Pod Autoscaler, que activa nuevas instancias al llegar al 75–80% de capacidad. También, el procesamiento asíncrono de tareas no críticas - como el envío de notificaciones - puede liberar recursos y permitir que la API maneje más solicitudes sin bloqueos. Ahora, pasemos a analizar la concurrencia, otra métrica esencial en escenarios de alta demanda.
La concurrencia mide cuántos usuarios utilizan la API al mismo tiempo, reflejando la presión real sobre los servidores en momentos pico. Para calcular la concurrencia necesaria en una prueba, se puede usar esta fórmula: (Sesiones promedio por hora × Duración promedio de sesión) / 3.600.
Las pruebas de carga son útiles para simular escenarios reales de alta demanda y detectar problemas como bloqueos en la base de datos o limitaciones en la gestión de sesiones. Por ejemplo, Workday realiza unas 1.200 pruebas de API en cada despliegue de su pipeline de CI/CD, lo que les permite identificar problemas críticos antes de que lleguen a producción.
"La consistencia en el tiempo de respuesta es tan crucial como la velocidad para las APIs. No se trata solo de qué tan rápido responde la API, sino de qué tan consistentemente mantiene esa velocidad, particularmente durante cargas pico." – Equipo de Abstracta
Un caso interesante es el de Tinybird, que durante la preparación para el Black Friday de una tienda de electrónica simuló un tráfico 10 veces mayor al habitual, alcanzando 100 QPS en búsquedas. Al monitorear la latencia p99 y el uso de CPU, detectaron que el endpoint /sales era un cuello de botella debido a consultas costosas. Para solucionarlo, implementaron vistas materializadas precalculadas, logrando mantener la latencia promedio por debajo de 200 ms incluso en picos de tráfico.
| Tipo de prueba | Frecuencia | Criterio de éxito |
|---|---|---|
| Prueba de carga | Cada despliegue | Latencia p95 < 200 ms bajo 2× carga normal |
| Prueba de estrés | Semanal | Manejar 5× carga normal sin fallas del sistema |
| Prueba de resistencia | Mensual | Rendimiento estable y uso de memoria constante durante 24 horas |
Además de manejar cargas elevadas, las APIs deben ofrecer una experiencia fluida, algo que se mide a través de los Core Web Vitals.
El rendimiento de una API afecta directamente los Core Web Vitals, métricas que Google usa para evaluar la experiencia del usuario. El Time to First Byte (TTFB), por ejemplo, influye en el First Contentful Paint (FCP), ya que mide el tiempo que tarda el navegador en mostrar el primer contenido visible. Si una API tarda 800 ms, la página se percibirá lenta antes de que el contenido sea visible.
El Interaction to Next Paint (INP) evalúa la capacidad de respuesta del sitio ante interacciones, como cuando un usuario hace clic en "Agregar al carrito". Si la API que valida el inventario tiene alta latencia, esto puede provocar demoras que lleven al abandono del carrito. Reducir el TTFB con estrategias como el uso de caché en memoria o CDNs no solo mejora el backend, sino también la percepción de velocidad en el frontend.
Monitorear estas métricas de manera integral ayuda a identificar si los problemas de experiencia del usuario provienen del frontend, del backend o de la interacción entre ambos. Un sistema escalable no solo debe manejar un alto volumen de solicitudes, sino hacerlo manteniendo tiempos de respuesta consistentes para todos los usuarios.
Una vez que las métricas están definidas, el siguiente paso es usar herramientas que las monitoreen en tiempo real. Esto es clave para identificar y solucionar problemas de rendimiento antes de que afecten a los usuarios. Este enfoque complementa las métricas mencionadas anteriormente y permite realizar ajustes inmediatos.
Para lograrlo, combiná pruebas de carga en preproducción (como k6 o JMeter) con herramientas de observabilidad en tiempo real (como Datadog o Prometheus). Las pruebas de carga ayudan a simular escenarios de alta demanda antes del lanzamiento, mientras que las herramientas de observabilidad monitorean el comportamiento en un entorno de producción real.
Además, integrá estas herramientas con API gateways como Apache APISIX o AWS API Gateway, que centralizan las métricas de todos los microservicios. También, soluciones como Catchpoint ofrecen dos enfoques muy útiles: monitoreo sintético, que simula transacciones incluso cuando no hay usuarios activos, y Real-User Monitoring (RUM), que captura la experiencia real de los usuarios.
"Recibimos alertas de Catchpoint en segundos cuando un sitio cae. Y podemos, en tres minutos, identificar exactamente de dónde proviene el problema." – Martin Norato Auer, VP de Servicios de Observabilidad CX, SAP
Elegir la herramienta adecuada puede marcar la diferencia en el rendimiento y estabilidad de tus APIs. A continuación, un resumen de las principales opciones disponibles:
| Herramienta | Métricas soportadas | Integración con e-commerce | Modelo de precios |
|---|---|---|---|
| Datadog | Latencia (p99), tasas de error, throughput, uso de CPU/RAM | Alta (AWS, Azure, Shopify, webhooks personalizados) | Comercial (por uso) |
| Catchpoint | DNS, CDN, latencia, RUM, transacciones sintéticas | Alta (nodos globales, seguimiento a nivel ISP) | Comercial (empresarial) |
| Prometheus + Grafana | Métricas personalizadas, conteo de solicitudes, distribuciones de latencia | Alta (exportadores para K8s, bases de datos, cloud) | Gratuito (código abierto) |
| Pingdom | Uptime, monitoreo de transacciones, velocidad de página | Media (alertas web, plugins CMS) | Comercial (suscripción) |
| Google PageSpeed Insights | Core Web Vitals, TTFB, rendimiento frontend | Baja (enfocado en URLs web) | Gratuito |
Configurá alertas específicas por endpoint para detectar problemas rápidamente. Por ejemplo, si el endpoint /checkout tiene una latencia p99 mayor a 500 ms, el equipo debería recibir una notificación inmediata. También es útil configurar alertas basadas en códigos HTTP:
Este tipo de segmentación te permitirá identificar la causa del problema con mayor rapidez y precisión.
Para garantizar un rendimiento sólido, es clave establecer objetivos claros, como mantener tiempos de respuesta de menos de 200 ms en el percentil 95 y un uptime del 99,9%, lo que equivale a solo 43 minutos de inactividad mensual. Además, es fundamental identificar métricas clave como latencia (p99), tasas de error (4xx/5xx), throughput y disponibilidad.
Integrar verificaciones de rendimiento en tu pipeline CI/CD puede marcar la diferencia. Por ejemplo, si un deployment aumenta la tasa de errores por encima del 5% durante más de dos minutos, configurá un rollback automático. También, implementá monitoreo sintético para simular transacciones cuando no hay usuarios activos, asegurando que todo funcione correctamente antes de períodos de alto tráfico.
Con un monitoreo centralizado, podés establecer benchmarks y configurar alertas que detecten cualquier desviación del rendimiento esperado.
En el ámbito del e-commerce, las mejores prácticas sugieren mantener un uptime del 99,9% y tiempos de respuesta inferiores a 2 segundos para APIs críticas. Para endpoints específicos, como consultas (GET), el objetivo debería ser menos de 100 ms, y para pagos (POST), no más de 500 ms.
Configurar alertas basadas en umbrales dinámicos es esencial. Si normalmente tu API responde en 200 ms durante horas pico, una respuesta de 300 ms debería activar una alerta, incluso si no parece excesiva. Prestá especial atención a endpoints clave como /checkout, /payments/process y /auth/login, ya que tienen un impacto directo en los ingresos.
En lugar de depender de promedios, monitoreá percentiles como p95 y p99, ya que estos reflejan mejor las experiencias de los usuarios. Por ejemplo, un p99 de 800 ms significa que el 1% de los usuarios experimenta ese tiempo de respuesta o más, lo que en entornos de alto tráfico puede representar miles de clientes.
Estas prácticas no solo permiten actuar rápidamente ante problemas, sino que también mejoran la experiencia del usuario y reducen el abandono del carrito.
Una alta latencia en APIs críticas, como las de checkout, afecta directamente las tasas de conversión. Si el tiempo de respuesta supera los 200 ms, las conversiones pueden disminuir en tiempo real. Para mitigar esto, adoptá estrategias como las siguientes:
Además, configurá auto-escalado inteligente basado en patrones históricos. Por ejemplo, si tu API maneja normalmente 1.000 solicitudes por segundo (RPS), configurá el escalado horizontal para activarse a 1.500 RPS, dejando margen ante picos inesperados. También es importante monitorear el uso de CPU y memoria, activando alertas cuando superen el 80%, para identificar problemas antes de que afecten el servicio.
Supervisar y mejorar las métricas de rendimiento de las APIs no es solo una tarea técnica, sino una pieza clave para el éxito en el e-commerce. Problemas como una latencia elevada, una alta tasa de errores o un throughput insuficiente afectan directamente la experiencia del usuario y, en última instancia, los ingresos de la empresa.
Este tipo de análisis abre una puerta hacia una operativa más eficiente y orientada al futuro. ¿La diferencia principal? Un enfoque reactivo espera a que las crisis lleguen y suele depender de los reportes de los usuarios. En cambio, un enfoque proactivo identifica y soluciona problemas antes de que los clientes siquiera los perciban. Este cambio no solo mejora la operativa diaria, sino que también transforma la mentalidad de las marcas, pasando de reaccionar ante los problemas a prevenirlos.
Las métricas clave son esenciales para evaluar el estado de las APIs. Por ejemplo, un p99 de 800 ms significa que el 1% de los usuarios experimenta tiempos de espera superiores, lo que, en momentos de alta demanda, puede traducirse en miles de transacciones perdidas.
Adoptar herramientas de monitoreo en tiempo real, configurar alertas basadas en umbrales dinámicos y optimizar los endpoints más críticos no solo protege los ingresos, sino que también refuerza la confianza en la marca. Este enfoque proactivo convierte el rendimiento de las APIs en un pilar fundamental para el éxito comercial, demostrando que no es solo un indicador técnico, sino un motor directo para el crecimiento en el e-commerce.
Reducir la latencia de tu API es fundamental para lograr un mejor rendimiento. Algunas formas efectivas de hacerlo incluyen usar caché para aliviar la carga sobre el backend, mejorar las consultas para que sean más rápidas y eficientes, y aprovechar una infraestructura distribuida que minimice los tiempos de espera. También es crucial monitorear métricas como el Tiempo hasta el Primer Byte (TTFB) y analizar momentos de alta demanda para detectar posibles cuellos de botella.
Además, realizar pruebas de carga y mantener un monitoreo constante te ayudará a evaluar cómo responde tu API bajo diferentes condiciones. Esto te permitirá ajustar configuraciones relacionadas con el servidor, la base de datos y la red según sea necesario. Otra estrategia para mejorar los tiempos de respuesta es implementar endpoints regionales y optimizar la infraestructura de red, asegurando una experiencia más rápida y confiable para quienes usan tu API.
Monitorear APIs de comercio electrónico requiere una combinación de monitoreo en tiempo real, análisis de métricas clave y procesos automatizados. Es esencial prestar atención a indicadores como la latencia, las tasas de error, el rendimiento y la disponibilidad para garantizar que los usuarios tengan una experiencia fluida y confiable.
Herramientas como Prometheus y Grafana destacan en el monitoreo en tiempo real, ofreciendo alertas personalizables y visualizaciones claras de datos. Por otro lado, los gateways API actúan como un punto centralizado para recopilar y analizar datos de rendimiento, haciendo que la interpretación sea más sencilla. Si se combinan con herramientas de pruebas de rendimiento como k6, es posible detectar problemas potenciales antes de que lleguen al entorno de producción. Además, las soluciones de observabilidad permiten mantener un monitoreo constante, lo que ayuda a identificar anomalías rápidamente.
El enfoque ideal es ser proactivo, recopilando las métricas necesarias para anticiparse a los problemas y resolverlos antes de que afecten a los usuarios. Esto asegura que las APIs operen con estabilidad y eficiencia, incluso en escenarios de alta demanda dentro del comercio electrónico.
Para mantener tus APIs funcionando de manera eficiente, es esencial monitorear constantemente métricas clave como la tasa de errores, el tiempo de respuesta y la disponibilidad. Este seguimiento te permite detectar patrones de fallos y cuellos de botella en tiempo real, lo que facilita abordar los problemas antes de que se conviertan en algo más grande.
Otra práctica importante es automatizar pruebas de carga y trazabilidad. Estas pruebas te ayudan a prever posibles fallos bajo diferentes condiciones, mejorando la preparación de tu sistema. Además, implementar un gateway de API puede ser un gran aliado, ya que centraliza el monitoreo del rendimiento y simplifica la gestión.
Por último, configurar alertas automáticas para errores críticos es clave. Estas alertas te permiten actuar rápidamente ante problemas graves, asegurando que tu servicio mantenga su estabilidad y sea confiable para los usuarios.