Las pruebas de carga en APIs son clave para garantizar que tu sistema funcione correctamente bajo condiciones de alta demanda. Se trata de simular tráfico intenso para medir el rendimiento, identificar límites y prevenir problemas como fallas en cascada o tiempos de respuesta lentos. Esto es especialmente importante en sectores como el e-commerce, donde el rendimiento afecta directamente la experiencia del usuario y las ventas.
Tipos de pruebas de carga:
Herramientas útiles:
Pasos clave:
En e-commerce, garantizar que endpoints críticos (checkout, inventario, pagos) funcionen sin interrupciones es imprescindible. Usar datos y entornos similares a producción mejora la precisión de las pruebas. Además, monitorear constantemente ayuda a identificar y resolver problemas antes de que afecten a los usuarios.
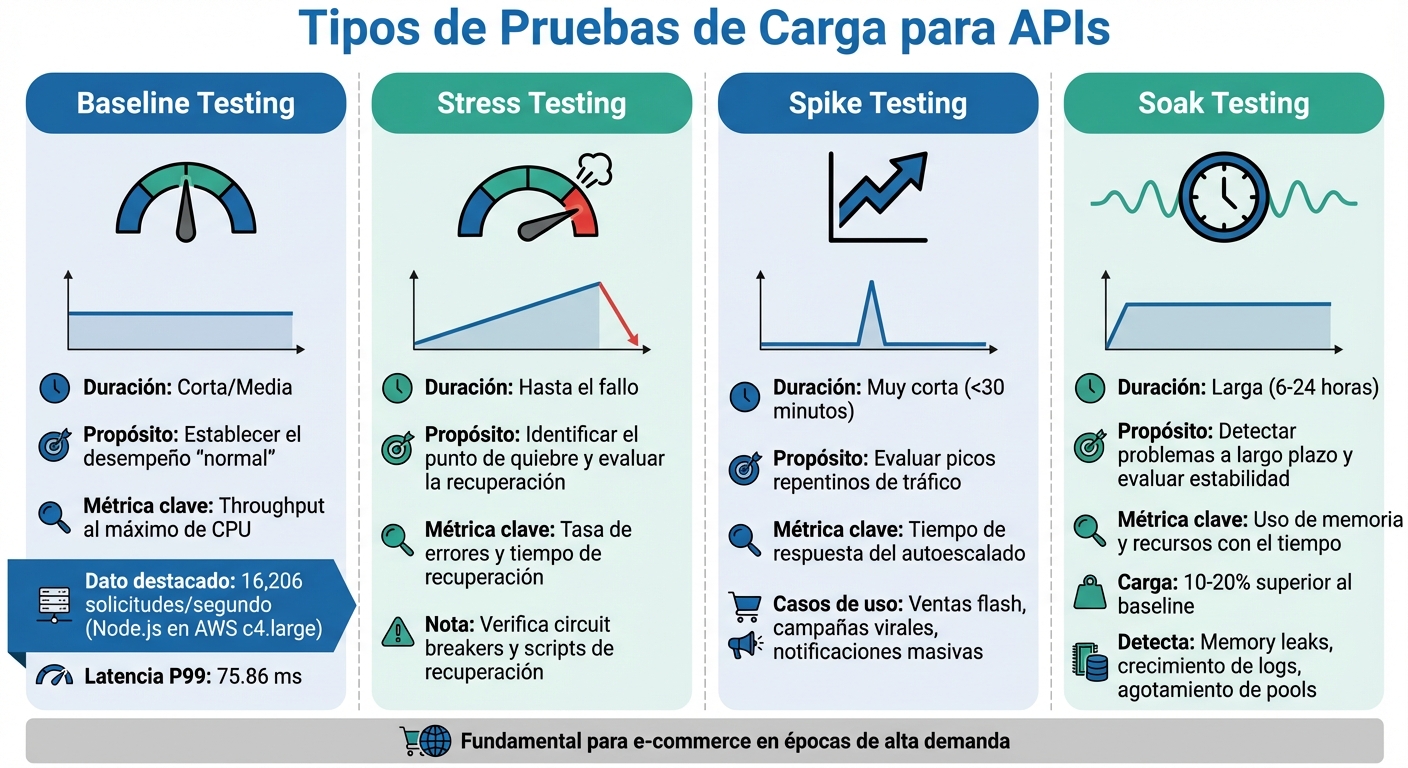
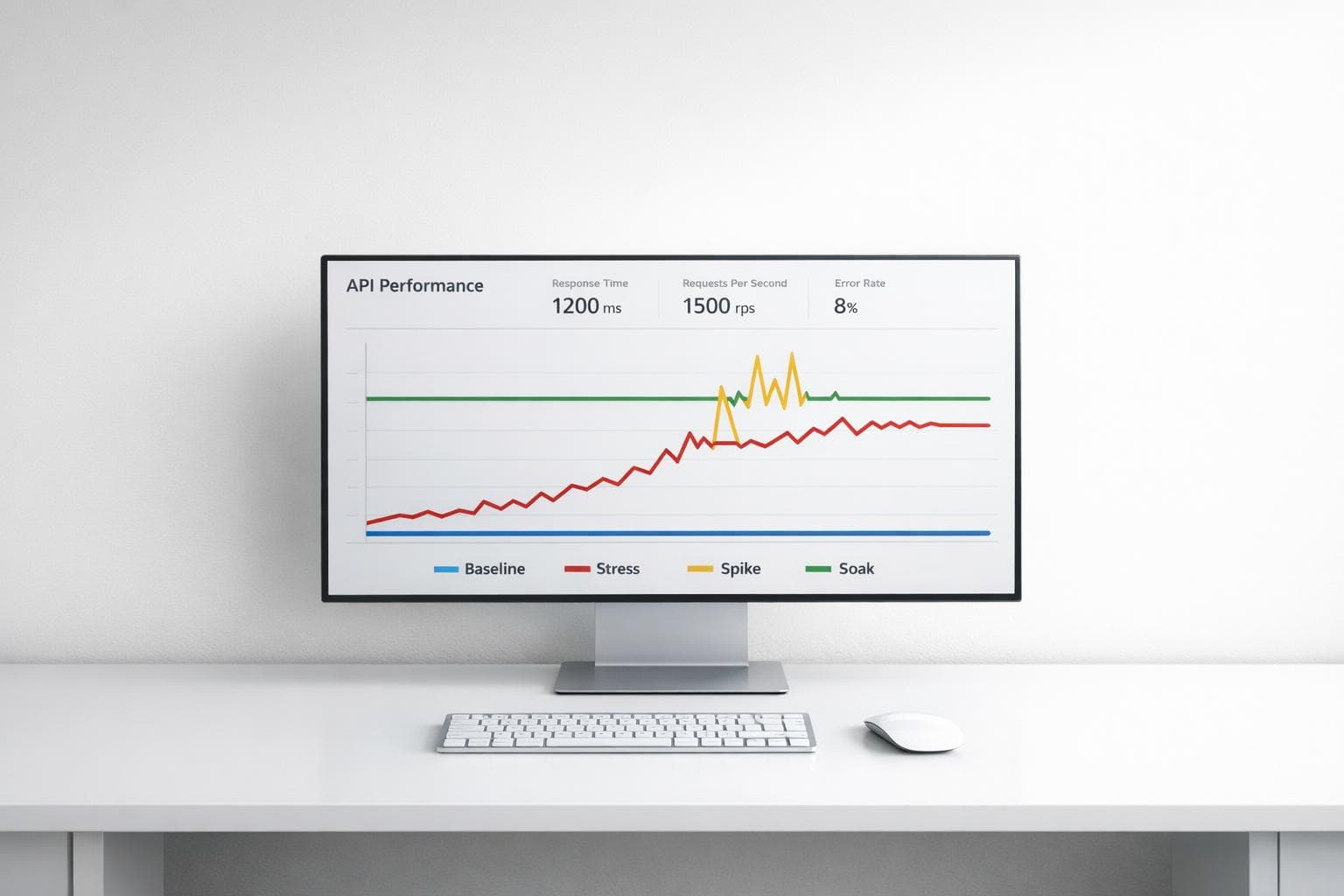
Comparación de tipos de pruebas de carga para APIs: Baseline, Stress, Spike y Soak
Cada tipo de prueba ofrece información valiosa para entender cómo responde una API bajo distintas condiciones.
Baseline testing se utiliza para establecer un rendimiento inicial, midiendo el máximo que una API puede manejar antes de saturarse. Por ejemplo, en una prueba de rendimiento base con una API desarrollada en Node.js, una instancia c4.large de AWS logró procesar hasta 16.206 solicitudes por segundo con una latencia del percentil 99 de 75,86 ms.
Stress testing empuja la API más allá de su capacidad esperada para identificar su punto de quiebre y evaluar cómo se recupera. Estas pruebas también verifican el funcionamiento de mecanismos como circuit breakers y scripts de recuperación. Son especialmente importantes antes de eventos críticos.
Spike testing simula incrementos repentinos de tráfico, como los que podrían ocurrir durante ventas flash o campañas masivas de notificaciones. Estas pruebas, que suelen durar menos de 30 minutos, permiten validar configuraciones de autoescalado, tiempos de inicio de servicios y la lógica de back-pressure. Son clave para prepararse ante situaciones como menciones virales en redes sociales o el impacto de una campaña publicitaria exitosa.
Soak testing, también conocida como prueba de resistencia, aplica una carga sostenida un 10-20% superior al baseline durante un período prolongado, entre 6 y 24 horas. Este tipo de prueba es útil para identificar problemas que surgen con el tiempo, como memory leaks, crecimiento descontrolado de archivos de log o agotamiento de pools de conexiones. En el sector de e-commerce, estas pruebas son fundamentales en épocas de alta demanda continua, como las semanas previas a las fiestas.
A continuación, se resumen las diferencias clave entre estos tipos de pruebas en la siguiente tabla:
| Tipo de prueba | Duración | Propósito principal | Métrica clave |
|---|---|---|---|
| Baseline | Corta/Media | Establecer el desempeño "normal" | Throughput al máximo de CPU |
| Stress | Hasta el fallo | Identificar el punto de quiebre y evaluar la recuperación | Tasa de errores y tiempo de recuperación |
| Spike | Muy corta (<30m) | Evaluar picos repentinos de tráfico | Tiempo de respuesta del autoescalado |
| Soak | Larga (6-24h) | Detectar problemas a largo plazo y evaluar estabilidad | Uso de memoria y recursos con el tiempo |
Elegir la herramienta adecuada depende del tipo de prueba y la complejidad de tu API. Por ejemplo, JMeter es perfecto para modelar flujos de usuario complejos, como procesos de checkout con múltiples pasos o solicitudes que requieren autenticación. Esta herramienta permite validar el comportamiento mediante aserciones y es altamente personalizable gracias a una amplia gama de plugins desarrollados por la comunidad. Además, puede simular miles de usuarios desde diversas regiones, lo que resulta útil para evaluar el rendimiento a nivel global. Por otro lado, existen herramientas que ofrecen soluciones específicas según el tipo de prueba que necesites.
También hay opciones especializadas que se ajustan a escenarios concretos, como pruebas baseline, de estrés, spike o soak, mencionadas previamente.
Gatling sobresale por su capacidad para crear escenarios detallados y su integración sencilla en pipelines de CI/CD. A diferencia de otras herramientas con interfaces gráficas más complejas, Gatling permite definir pruebas mediante código, lo que facilita el control de versiones y la colaboración entre equipos. Es especialmente útil en entornos como el e-commerce, donde es necesario simular comportamientos realistas, como navegar por catálogos, agregar productos al carrito y realizar pagos utilizando diferentes métodos.
k6 se integra perfectamente con Grafana, ofreciendo monitoreo en tiempo real y visualización de métricas durante las pruebas de carga. Esto permite detectar cuellos de botella de forma inmediata. Además, k6 es compatible con plataformas como OpenTelemetry, Datadog, CloudWatch, New Relic, Prometheus y otras, lo que lo convierte en una solución versátil para equipos que ya utilizan estas herramientas de monitoreo.
Si buscás una herramienta sencilla para pruebas de carga a menor escala, Postman es una excelente opción. Es ideal para equipos que ya lo emplean en el desarrollo de APIs, ya que permite realizar pruebas rápidas sin necesidad de configuraciones complejas. Aunque no está diseñado para simular millones de usuarios, es suficiente para evaluar el rendimiento en entornos de desarrollo o APIs con un tráfico moderado.
Para llevar a cabo pruebas de carga efectivas, no basta con simplemente ejecutarlas. Es crucial definir objetivos claros, crear escenarios que reflejen el uso real y analizar los resultados para mejorar el rendimiento de tu API. Una vez que tengas objetivos bien definidos, el siguiente paso es diseñar pruebas que simulen el comportamiento real de los usuarios.
Antes de comenzar, es esencial establecer metas específicas y medibles. Podés usar logs de producción o herramientas como APM para identificar datos clave: el throughput promedio, los picos de tráfico y cómo se distribuye el tráfico entre los distintos endpoints. Esto te ayudará a centrarte en métricas fundamentales como el tiempo de respuesta, el throughput, la tasa de errores y el uso de recursos.
Los Service Level Objectives (SLOs) deben ser precisos y alcanzables. Ejemplos de esto podrían incluir: "El 95% de las solicitudes deben responder en menos de 500 ms" o "La tasa de errores debe permanecer por debajo del 1% durante los picos de tráfico". Es importante priorizar la latencia de cola (percentil 95 o 99) en lugar de promedios, ya que los promedios pueden enmascarar problemas que afectan a una parte significativa de los usuarios.
Los escenarios de prueba deben representar cómo interactúan los usuarios reales con tu sistema. Por ejemplo, podés replicar la distribución del tráfico real, donde el 80% se concentra en el 20% de los endpoints más utilizados. Además, es útil incluir tanto flujos de usuario comunes (happy paths) como casos extremos para detectar posibles cuellos de botella.
Incorporá datos dinámicos en tus pruebas, como términos de búsqueda o IDs de productos aleatorios, para evitar que el sistema se beneficie artificialmente del caché. Asegurate de incluir headers de autenticación realistas (como tokens Bearer) para medir correctamente la carga que genera el procesamiento de seguridad. También es importante simular tráfico desde diferentes regiones para evaluar cómo la latencia y el enrutamiento DNS afectan el rendimiento.
Una vez que hayas configurado escenarios realistas, el siguiente paso es analizar los resultados para identificar y abordar los problemas.
El análisis de resultados debe centrarse en cuatro áreas clave: tiempo de respuesta, throughput, tasa de errores y uso de recursos. Compará los datos obtenidos del generador de carga con métricas internas del sistema, como tiempos de espera en la base de datos, saturación del thread pool o pausas del garbage collector.
Dale prioridad a la latencia del percentil 99 en lugar de los promedios, ya que estos últimos pueden ocultar problemas que afectan a un subconjunto de usuarios en momentos de alta demanda. Iterá constantemente: ejecutá pruebas, analizá los datos, optimizá los resultados y volvé a verificar. Como mencionaron Hugo Guerrero y Vanessa Ramos de Red Hat:
The best feature your API can have is great performance.
En el mundo del e-commerce, las pruebas de carga no son un lujo, son una necesidad. Incluso una breve interrupción puede impactar drásticamente los ingresos. Por eso, es clave seguir un enfoque meticuloso y bien planificado.
Para que las pruebas de carga sean útiles, tu entorno de staging debe replicar exactamente las condiciones de producción: desde las regiones del cloud hasta los tipos de instancia (ya sean optimizadas para CPU o memoria) y las políticas de seguridad. Esto asegura que los resultados obtenidos reflejen lo que realmente sucederá en producción. Como mencionan los expertos de BairesDev:
Load testing turns that gap into a measurable discipline... it shifts conversations from guesswork to probabilities, from 'we hope it holds' to 'we can survive three times last quarter's peak'.
Además, es fundamental usar trazas de producción anonimizadas para simular cargas reales. Evitá depender de datos estáticos o repetitivos, ya que podrían ser afectados por el caché y generar resultados poco fiables. También es buena práctica ejecutar pruebas desde varias regiones geográficas, para evaluar la latencia y el comportamiento del enrutamiento DNS que experimentan los usuarios de diferentes partes del mundo.
Un entorno bien configurado no solo mejora la precisión de las pruebas, sino que también allana el camino para automatizar estas pruebas dentro del ciclo de desarrollo.
La automatización es clave para detectar problemas de rendimiento antes de que lleguen a producción. Al integrar las pruebas de carga en tus pipelines de CI/CD, podés identificar regresiones de rendimiento en etapas tempranas del desarrollo, donde resolverlas es mucho más económico y sencillo. Además, la automatización asegura que las pruebas se realicen siempre bajo las mismas condiciones, eliminando posibles errores humanos.
Configurá los pipelines para que rechacen builds que no cumplan con los umbrales establecidos. Por ejemplo, podés definir límites como una latencia del percentil 95 que no supere los 500 ms o una tasa de errores inferior al 1%. Herramientas como Locust permiten ejecutar estas pruebas de manera eficiente en modo headless (locust --headless), recolectando métricas sin intervención manual.
Para microservicios, implementá pruebas rápidas en cada pull request, lo que permite detectar problemas obvios en minutos. Reservá las pruebas más complejas para entornos de staging, donde se puedan simular escenarios más detallados.
El monitoreo específico de los endpoints más importantes es un complemento esencial de las pruebas automatizadas. Prestá especial atención a los endpoints que soportan los flujos críticos del negocio, como el checkout, el procesamiento de pedidos, la sincronización de inventario en tiempo real y la búsqueda de productos. Según las estadísticas, el 90% de los usuarios sigue un "happy path" predecible, concentrando la mayor parte del tráfico en estos puntos.
Además de medir la latencia, es importante monitorear métricas más profundas del sistema, como bloqueos de base de datos, saturación del thread pool y pausas del garbage collector. En integraciones de e-commerce en tiempo real, como webhooks o sistemas de mensajería, asegurate de que los endpoints puedan manejar actualizaciones incluso durante los picos de carga.
Por último, nunca realices pruebas de rendimiento directamente en sistemas de producción. Usá un entorno de staging dedicado que replique fielmente la topología, los volúmenes de datos y las políticas de seguridad de producción. Esto no solo protege tu entorno en vivo, sino que también garantiza que las pruebas sean lo más realistas posible.
Las pruebas de carga no son un lujo en el desarrollo de APIs para e-commerce; son una obligación. En un contexto donde las APIs actúan como el puente esencial entre el usuario final y el servicio, garantizar su escalabilidad y confiabilidad es clave para mantenerse competitivo.
Un test realizado en Node.js alcanzó 16.206 solicitudes por segundo con una latencia del percentil 99 de 75,86 ms, lo que subraya la importancia de medir para poder mejorar. Establecer una línea base, identificar cuellos de botella y analizar métricas como el P95 y el P99 de latencia te permite dejar de lado las suposiciones y asegurarte de que tu API pueda manejar picos significativos de tráfico sin problemas.
Simular tráfico realista, automatizar pruebas en pipelines CI/CD y priorizar endpoints críticos en los flujos más importantes son pasos esenciales. Herramientas como Locust, JMeter y Vegeta ofrecen opciones variadas, desde pruebas funcionales detalladas hasta la medición del máximo rendimiento posible.
Con estos principios en mente, es hora de tomar acción. Empezá revisando los logs de producción o utilizando herramientas de monitoreo APM para analizar el throughput promedio, los picos de tráfico y cómo se distribuyen las solicitudes entre tus endpoints. A partir de ahí, definí umbrales claros de rendimiento y automatizá las pruebas para validar cada nuevo despliegue antes de que llegue a producción.
Para marcas que dependen de integraciones en tiempo real, como sistemas de mensajería o webhooks, estas prácticas son aún más críticas. Por ejemplo, plataformas como Burbuxa, que conectan tu tienda con agentes de IA en WhatsApp e Instagram, requieren APIs capaces de manejar actualizaciones de inventario, pedidos y datos de clientes incluso en momentos de alta demanda. Si trabajás con Shopify, Tiendanube o VTEX, garantizar la velocidad y confiabilidad de estas integraciones mediante pruebas de carga puede marcar la diferencia en los momentos más exigentes.
Al momento de elegir una herramienta para realizar pruebas de carga en tu API, es fundamental que esta se ajuste a tus requisitos específicos. Verifica que pueda simular el tráfico esperado, como la interacción de múltiples usuarios simultáneos, y que te permita configurar métricas clave de rendimiento. Esto será vital para detectar y resolver posibles cuellos de botella. También resulta valioso que la herramienta ofrezca la opción de ejecutar pruebas desde diversas ubicaciones geográficas, ya que esto ayuda a recrear escenarios más cercanos a la realidad.
Otro aspecto importante es la capacidad de escalamiento y la facilidad de uso. Si tu sistema necesita manejar grandes volúmenes de tráfico o pruebas personalizadas, busca herramientas que ofrezcan esa flexibilidad. Además, contar con una buena documentación y un soporte técnico eficiente puede marcar la diferencia, ya que simplifica tanto la implementación como la resolución de cualquier inconveniente. En definitiva, optá por una solución que combine funcionalidad, flexibilidad y un soporte confiable para garantizar resultados precisos y mejorar el rendimiento de tu API.
Cuando se trata de automatizar pruebas de carga dentro de un pipeline CI/CD, podés seguir estos pasos clave para asegurarte de que tu API esté lista para manejar el tráfico esperado:
Al incorporar estas pruebas en tu flujo de trabajo, no solo asegurás que tu API soporte las demandas esperadas, sino que también mejorás su rendimiento con cada iteración del desarrollo.
Simular tráfico real durante las pruebas de carga es clave para detectar posibles puntos débiles y analizar cómo reacciona la API ante condiciones que reflejan su uso diario. Este enfoque ayuda a asegurar que el sistema funcione correctamente incluso en momentos de alta demanda o cuando los patrones de tráfico cambian.
Al recrear situaciones cercanas a la realidad, también es posible anticipar cómo se desempeñará la API en diferentes regiones o con diversos niveles de usuarios, garantizando un servicio estable y sin interrupciones para todos.