
¿Por qué son clave las pruebas de escalabilidad en APIs de e-commerce? Porque garantizan que tu plataforma funcione sin problemas, incluso en eventos de alta demanda como Black Friday. Si una API falla o se ralentiza, la experiencia del cliente se ve afectada, y eso puede costarte ventas.
Ejemplo real: Rappi implementó un framework de pruebas sintéticas tras una caída en el Día de la Madre 2020, logrando manejar volúmenes récord en 2021 sin interrupciones.
No se trata solo de hacer que las APIs funcionen, sino de garantizar que lo hagan bajo cualquier circunstancia. Las pruebas de escalabilidad son el escudo que protege tu negocio de colapsos inesperados.
En el mundo del e-commerce, las APIs no son solo herramientas de integración; son el corazón que conecta cada interacción entre los usuarios y los servicios. Desde la navegación inicial hasta la confirmación de un pedido, las APIs garantizan que todo funcione de manera fluida.
Hugo Guerrero y Vanessa Ramos de Red Hat lo explican claramente:
"No importa qué tan extremadamente bien construidas estén tus aplicaciones front-end si las fuentes de datos de la API tardan varios segundos en responder."
Este punto se vuelve aún más crítico durante eventos de alto tráfico, donde suelen aparecer problemas como bases de datos saturadas, aumentos en la latencia (p99) y arranques en frío de microservicios. Sin pruebas adecuadas, los sistemas pueden recurrir a mecanismos automáticos como la limitación de tasa (errores 429) o los circuit breakers (errores 503), dejando a los usuarios sin acceso a los servicios.
Un caso ilustrativo ocurrió en mayo de 2020, cuando Rappi enfrentó una de sus peores caídas durante el Día de la Madre. Un inesperado aumento de tres veces en la demanda reveló fallos en su arquitectura de microservicios. Esto afectó funciones críticas como la asignación de pedidos, dejando a los usuarios sin poder realizar compras, con tiendas marcadas como no disponibles y métodos de pago que fallaban.
Para evitar que esto se repitiera, el equipo de SRE y Arquitectura, liderado por Jonatan Ponzo, creó un framework de pruebas sintéticas llamado "SynthCity". Este simulaba un ecosistema completo con usuarios, repartidores y tiendas ficticias, diseñado para poner a prueba el algoritmo de asignación bajo condiciones extremas. Gracias a esta estrategia, Rappi logró manejar volúmenes récord durante el Día de la Madre de 2021, sin interrupciones.
Okan Yenigün, ingeniero de APIs, lo resume perfectamente:
"Las pruebas de carga son cómo ensayás estos escenarios intencionalmente, en lugar de descubrirlos por primera vez durante un incidente real."
Incluso si una API no colapsa por completo, una latencia alta en percentiles extremos (como p99.9) puede frustrar a miles de usuarios por cada millón de solicitudes procesadas. Además, para plataformas con acuerdos de nivel de servicio (SLAs), no cumplir con las metas de rendimiento, como mantener una latencia p99 por debajo de 300 ms, puede derivar en multas o créditos de servicio para clientes empresariales. Estos ejemplos subrayan lo crucial que es realizar pruebas detalladas para prepararse frente a escenarios de alta demanda.
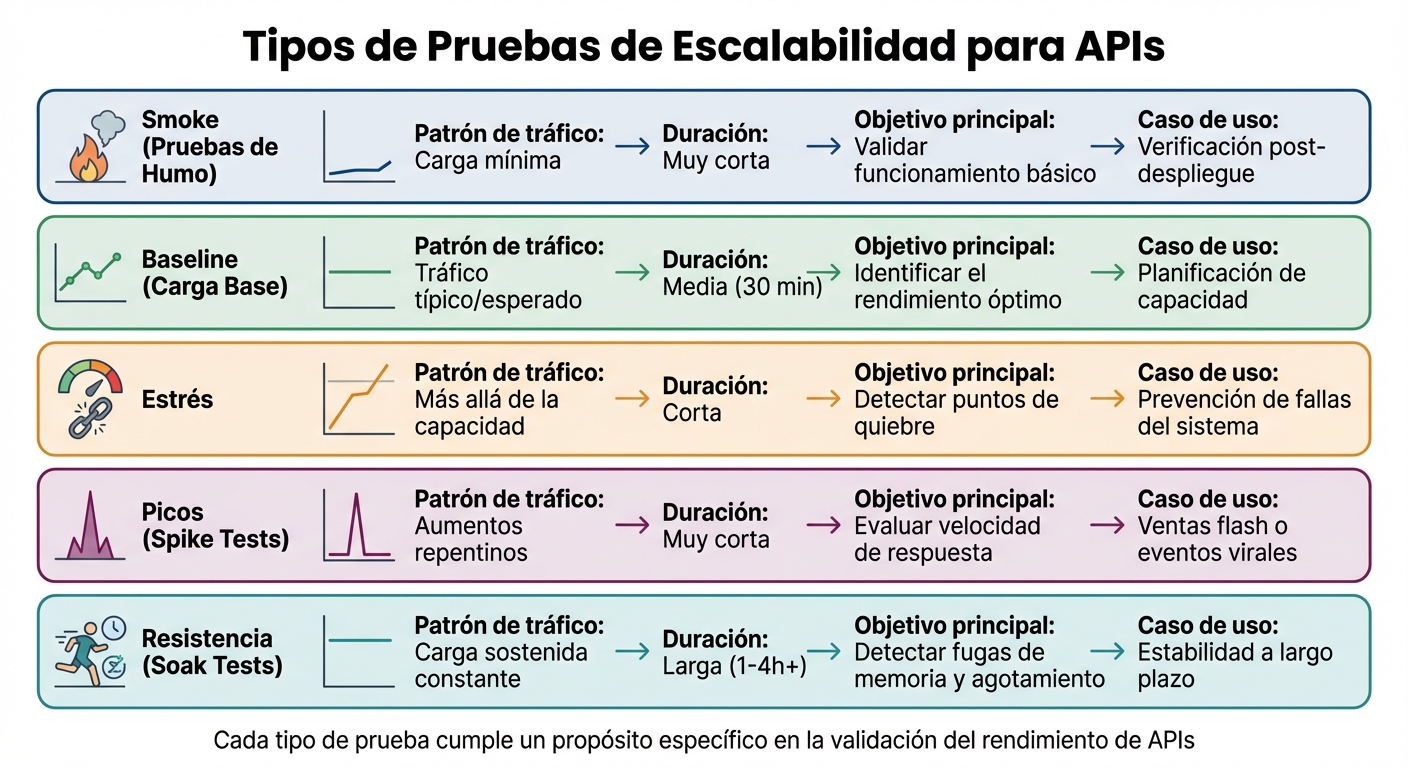
Tipos de pruebas de escalabilidad para APIs: comparación de patrones, duración y objetivos
Las pruebas de rendimiento son clave para evaluar la velocidad, capacidad de respuesta, confiabilidad y escalabilidad de una API. Cada tipo de prueba cumple un propósito específico y se aplica en diferentes etapas del desarrollo.
Las pruebas de humo (smoke tests) verifican el correcto funcionamiento del entorno y de los scripts con una carga mínima antes de realizar pruebas más exigentes. Son ideales para asegurar que todo esté en orden después de un despliegue. Por otro lado, las pruebas de carga base (baseline tests) simulan tráfico típico durante 30 minutos, con un arranque inicial de 15 minutos, para identificar el "punto óptimo" de rendimiento estable. Estas pruebas son esenciales para planificar la capacidad del sistema.
Las pruebas de estrés llevan el sistema al límite, más allá de su capacidad normal, para encontrar su punto de quiebre y observar cómo responde ante fallas. Según Okan Yenigün:
"Las pruebas de estrés muestran si tu sistema muere en silencio o muestran la magnitud del fallo".
Las pruebas de picos (spike tests) simulan incrementos súbitos y masivos de tráfico en cuestión de segundos, siendo útiles para escenarios como ventas flash o eventos virales. Finalmente, las pruebas de resistencia (soak tests) aplican una carga constante durante 1 a 4 horas (o más) para detectar problemas como fugas de memoria o una degradación progresiva en el rendimiento.
| Tipo de prueba | Patrón de tráfico | Duración | Objetivo principal | Caso de uso |
|---|---|---|---|---|
| Smoke | Carga mínima | Muy corta | Validar funcionamiento básico | Verificación post-despliegue |
| Baseline | Tráfico típico/esperado | Media (30 min) | Identificar el rendimiento óptimo | Planificación de capacidad |
| Estrés | Más allá de la capacidad | Corta | Detectar puntos de quiebre | Prevención de fallas del sistema |
| Picos | Aumentos repentinos | Muy corta | Evaluar velocidad de respuesta | Ventas flash o eventos virales |
| Resistencia | Carga sostenida constante | Larga (1-4h+) | Detectar fugas de memoria y agotamiento | Estabilidad a largo plazo |
En las siguientes secciones, veremos cómo diseñar pruebas de escalabilidad utilizando estos enfoques.
El primer paso para realizar pruebas efectivas es basarse en datos reales de uso. Analizá los registros del servidor o usá herramientas de monitoreo como New Relic para identificar el rendimiento promedio, los picos de tráfico y cómo se distribuyen las solicitudes entre endpoints y usuarios. En plataformas de e-commerce, es típico que el 80% del tráfico se concentre en solo el 20% de los endpoints.
Es importante trabajar con datos dinámicos en lugar de valores fijos. Por ejemplo, reemplazá IDs de usuario, contraseñas y productos con datos variables para evitar que las pruebas se limiten a la capa de caché. También podés usar una variedad de correos electrónicos y términos de búsqueda aleatorios para simular interacciones más auténticas con la base de datos. Además, incorporá tiempos de espera entre solicitudes ("think time") para imitar el ritmo natural de los usuarios humanos.
Diversificá las fuentes de tráfico generando solicitudes desde distintas direcciones IP y regiones. Esto ayuda a evitar que se activen medidas de seguridad como la limitación de tasa o el circuit breaking. También es fundamental asegurarte de que los generadores de carga mantengan un uso de recursos (CPU y RAM) por debajo del 80%, para que no se conviertan en un cuello de botella durante las pruebas.
Una vez definidos los escenarios de carga, es momento de validar los flujos completos de los usuarios. Esto incluye pruebas que simulen procesos como navegar por el catálogo, buscar productos, agregar artículos al carrito y completar una compra, coordinando múltiples llamadas a las APIs de manera simultánea.
Según commercetools:
"El objetivo de las pruebas de carga no es hacer que el sistema falle. Más bien, es determinar si el sistema puede manejar el tráfico esperado dentro de umbrales de rendimiento definidos."
Diseñá perfiles de carga que incluyan un período gradual de arranque (ramp-up) de 15 minutos. Esto permite que los mecanismos de auto-escalado se activen y estabilicen antes de alcanzar la carga máxima. Además, documentá la actividad esperada por hora, diferenciando entre tráfico regular y picos, y especificá métricas clave como vistas de productos, búsquedas y el porcentaje de visitas que generan carritos creados. No olvides automatizar la limpieza: los datos generados durante las pruebas, como órdenes y carritos de prueba, deben eliminarse dentro de una semana.
Las pruebas de escalabilidad no solo evalúan la carga, sino también cómo responde el sistema ante errores. Para probar el auto-escalado, simulá picos repentinos de tráfico, como los que ocurren durante una venta flash, y medí la rapidez con que el sistema se adapta. Las pruebas de estrés, por su parte, ayudan a identificar el punto de quiebre y permiten ajustar el manejo de errores. Herramientas como k6 ofrecen funciones para verificar la corrección de las respuestas (códigos de estado, encabezados) y definir umbrales de rendimiento, fallando la prueba si, por ejemplo, la tasa de error supera el 1%.
Recordá que las plataformas multi-tenant suelen implementar medidas como limitación de tasa (HTTP 429) y circuit breaking (HTTP 503) para protegerse de picos de tráfico. Una respuesta 429 Too Many Requests incluirá un encabezado Retry-After que indica cuándo reintentar la solicitud. Para evitar que las pruebas sean interpretadas como un ataque DDoS, notificá al soporte de tu plataforma con al menos tres días hábiles de anticipación antes de realizar pruebas de alto volumen. También es útil distribuir la carga en varias regiones y direcciones IP para simular tráfico global.
Estas prácticas de escalabilidad se integran en el ciclo continuo de desarrollo y monitoreo, asegurando que el sistema esté preparado para manejar tanto el tráfico esperado como situaciones inesperadas.
Una vez que se han definido los escenarios y diseñado las pruebas, es clave observar ciertas métricas que aseguren el rendimiento del sistema bajo condiciones de alta demanda.
El throughput o solicitudes por segundo (RPS, por sus siglas en inglés) mide cuántas peticiones puede manejar el sistema en un segundo, lo que define su capacidad máxima. Por otro lado, el tiempo de respuesta debe analizarse utilizando percentiles como el p95, p99 y p99.9, que muestran cómo se comporta la latencia en los momentos de mayor carga. Idealmente, las mejores APIs responden entre 0,1 y 1 segundo. Para poner esto en perspectiva, un aumento de 100 milisegundos en la latencia podría costarle a Amazon cerca del 1% de sus ingresos, mientras que un retraso de 500 milisegundos podría reducir el tráfico de Google en un 20%.
La tasa de errores también es una métrica crítica. En sistemas de alto volumen, es vital que esta tasa se mantenga por debajo del 0,3% para garantizar la confiabilidad. Por ejemplo, en Salesforce B2C Commerce, si las Shopper APIs tardan más de 10 segundos en responder, se genera un error 504 (timeout), lo que impide completar transacciones.
Otra métrica importante es la utilización de la CPU. Si la CPU está muy ocupada pero el throughput es bajo, esto podría indicar un código ineficiente. Por el contrario, una latencia alta con baja utilización de CPU podría señalar que el pool de conexiones a la base de datos está saturado. Analizando estos indicadores, se pueden establecer límites claros para mantener el rendimiento incluso en picos de tráfico.
Definir umbrales de rendimiento requiere considerar tanto las necesidades del negocio como las expectativas de los usuarios. Por ejemplo, un objetivo interno (SLO) podría ser que el 99% de las solicitudes se completen en menos de 300 ms a un ritmo de 200 RPS. Para manejar picos de tráfico, la infraestructura debería diseñarse para soportar entre 5 y 10 veces el RPS promedio diario.
| Tiempo de respuesta | Percepción del usuario | Impacto en e-commerce |
|---|---|---|
| < 0,1 segundo | Instantáneo | Ideal para búsquedas en tiempo real e interacciones de UI |
| 0,1 - 1,0 segundo | Rápido | Experiencia estándar para la mayoría de las plataformas |
| 1,0 - 3,0 segundos | Demora notable | Riesgo de abandono del carrito debido a la espera |
| > 3,0 segundos | Lento | Alto riesgo de frustración y pérdida de tráfico |
| > 10,0 segundos | Timeout/Falla | Las transacciones no pueden completarse |
El rendimiento de las APIs y su capacidad para transferir datos eficientemente son esenciales para el éxito operativo. Incluso pequeños retrasos pueden tener un impacto importante en la experiencia del usuario y en los resultados comerciales.
Cuando las métricas revelan problemas, es esencial identificar el cuello de botella. Combinar métricas externas, como RPS y latencia, con la monitorización de recursos internos puede ayudar a determinar si el problema proviene de código ineficiente, bloqueos en la base de datos o limitaciones de hardware.
Un aspecto clave es evitar enfocarse únicamente en la velocidad promedio. La variabilidad en los tiempos de respuesta puede ocultar problemas importantes que no se detectan al analizar solo promedios.
También es fundamental monitorear las dependencias de terceros. Analizar los logs puede ayudar a identificar si los errores o picos de latencia provienen de servicios externos, como gateways de pago o herramientas de seguimiento, en lugar de la API propia. Por último, los generadores de carga deben operar con una utilización de recursos inferior al 80% para evitar que se conviertan en otro cuello de botella durante las pruebas.
Incorporar pruebas de escalabilidad en el ciclo de desarrollo es clave para garantizar que el rendimiento no se vea afectado con cada nueva versión y que los problemas se detecten antes de llegar a producción.
Incluir pruebas de escalabilidad en los pipelines de integración continua (CI/CD) permite verificar automáticamente el rendimiento con cada cambio en el código. Este proceso reproduce la configuración de producción en un entorno de prueba, escala recursos, simula tráfico, reduce recursos y limpia los datos al finalizar.
Herramientas como Locust son útiles para ejecutar pruebas sin interfaz gráfica, lo que facilita su integración en los runners de CI/CD. Es importante que el entorno de prueba sea lo más cercano posible al de producción (en términos de CPU, memoria y cantidad de instancias) para obtener resultados confiables.
Un ejemplo interesante es Zalando, que en marzo de 2021 desarrolló un microservicio automatizado en Golang llamado "Load-Test-Conductor". Este sistema gestionaba pruebas en Kubernetes, utilizando Hoverfly para simular dependencias externas y CronJobs para programar las pruebas. Esto permitió a los desarrolladores ejecutar pruebas complejas de escalabilidad mediante una simple llamada API, optimizando su preparación para eventos como la Cyber Week.
Un detalle crucial durante estas pruebas es deshabilitar el autoescalado, ya que la latencia inicial del "arranque en frío" puede alterar los resultados. Además, simular dependencias externas (con herramientas como Hoverfly) ayuda a evaluar el rendimiento de la API sin afectar servicios de terceros, lo que resulta especialmente útil en entornos CI/CD.
Estos pasos aseguran que el rendimiento sea una prioridad constante en cada actualización.
Definir la frecuencia de las pruebas es tan importante como integrarlas. Esto debe ajustarse al ciclo del negocio y a eventos de alto tráfico. Por ejemplo:
Es importante evitar pruebas pesadas en períodos críticos del negocio. Además, las plataformas de e-commerce suelen requerir un aviso de tres días hábiles antes de realizar pruebas de alto volumen. Realizar "ensayos" con incrementos graduales de carga antes de las pruebas finales ayuda a identificar problemas iniciales y ajustar el entorno adecuadamente.
La automatización no solo debe cubrir la ejecución de las pruebas, sino también el análisis de los resultados. Configurar dashboards en tiempo real (por ejemplo, con Grafana) y alertas automáticas permite detectar rápidamente cualquier incumplimiento de los objetivos de nivel de servicio (SLOs) y actuar a tiempo.
Para pruebas de alto volumen, es esencial usar generación de carga distribuida con múltiples nodos trabajadores, ya que un solo inyector de carga puede quedarse corto en recursos. Asimismo, automatizar la limpieza de datos de prueba (como pedidos, carritos y usuarios) al finalizar el pipeline ayuda a mantener el sistema ordenado. Asegurate de que los generadores de carga operen eficientemente para evitar que se conviertan en un nuevo cuello de botella durante las pruebas.
Las pruebas de escalabilidad son fundamentales para que una plataforma de e-commerce conserve la confianza de sus clientes. Como dice API7.ai: "esperar a que tu API se rompa antes de pensar en escalar es una receta para el desastre". Eventos como el Black Friday o campañas virales pueden generar picos de tráfico que, sin una preparación adecuada, se transforman en crisis.
El secreto está en simular escenarios reales de carga, incluyendo variaciones en productos, correos, direcciones IP y tiempos de espera que imiten el comportamiento humano. Esto ayuda a detectar cuellos de botella ocultos, como la saturación de conexiones a la base de datos o picos de latencia en el percentil 99, que solo aparecen bajo condiciones de alta concurrencia.
Incorporar estas pruebas en los pipelines de CI/CD, automatizando su ejecución, análisis y limpieza de datos, asegura que cada actualización mantenga el rendimiento esperado. Un sistema bien diseñado no solo debe funcionar correctamente, sino también fallar de manera controlada. Las pruebas de estrés son clave para saber si tu infraestructura colapsa sin afectar otros servicios o si provoca un efecto dominó.
"Una API escalable demuestra confiabilidad que es la base de una relación sólida con tu comunidad de desarrolladores." - API7.ai
Definir umbrales claros, como mantener la latencia p99 por debajo de 400 ms y una tasa de error inferior al 0,1%, te permitirá escalar con seguridad y aprovechar cada pico de tráfico como una oportunidad de crecimiento.
Las pruebas de escalabilidad son fundamentales para que las APIs de e-commerce ofrezcan una experiencia de usuario rápida y confiable, incluso en momentos de alta demanda, como promociones o eventos especiales. Estas pruebas recrean escenarios de tráfico intenso para identificar posibles puntos débiles y garantizar que la API pueda manejar un gran volumen de solicitudes sin comprometer su rendimiento.
Al realizar estas pruebas, se pueden detectar y solucionar problemas antes de que afecten a los usuarios finales. Esto asegura tiempos de respuesta eficientes y una navegación sin interrupciones. Además, no solo optimiza el desempeño técnico de la plataforma, sino que también protege la satisfacción del cliente, evitando problemas como carritos abandonados, pérdidas de ventas y daños a la reputación de la marca.
Si querés que tu API esté lista para manejar picos de tráfico en plataformas de e-commerce, las pruebas de escalabilidad y carga son fundamentales. Estas pruebas no solo evalúan el rendimiento bajo presión, sino que también te ayudan a prevenir problemas antes de que afecten a tus usuarios.
Pruebas de escalabilidad: Estas pruebas analizan cómo reacciona tu API cuando el volumen de usuarios crece de forma gradual. El objetivo es asegurarse de que el rendimiento no baje a medida que la demanda aumenta.
Pruebas de carga: En este caso, se simulan condiciones de tráfico extremo, como las que suelen darse en campañas de descuentos masivos o eventos especiales. Esto permite verificar si tu API puede mantener su estabilidad y responder correctamente incluso en los momentos de mayor exigencia.
Para que estas pruebas sean efectivas, es clave diseñarlas en base a escenarios reales, como simulaciones de procesos de compra o consultas al servicio de soporte. Además, una monitorización constante del rendimiento es un complemento esencial. Esto te permitirá detectar posibles cuellos de botella y anticiparte a problemas, asegurando que tus usuarios disfruten de una experiencia fluida incluso en los momentos más críticos.
Incorporar pruebas de escalabilidad en los pipelines de CI/CD es clave para asegurarse de que las APIs de e-commerce soporten picos de tráfico y cargas crecientes sin problemas. ¿Cómo se consigue esto? Automatizando pruebas de rendimiento que simulan diferentes escenarios de carga y ejecutándolas automáticamente tras cada despliegue o actualización.
Para llevarlo a cabo, herramientas como Artillery, Locust o k6 son excelentes opciones. Estas permiten realizar pruebas de carga automatizadas y obtener métricas en tiempo real, lo que facilita el análisis del rendimiento. Un detalle importante: desactiva el autoscaling durante las pruebas. Esto es esencial para obtener resultados precisos y ajustar la infraestructura basándote en datos reales.
Con este enfoque, garantizás que las APIs puedan escalar de manera eficiente y cumplir con las exigencias del negocio, incluso en los momentos de mayor demanda.