
El aprendizaje no supervisado permite segmentar clientes sin depender de etiquetas predefinidas, analizando patrones en grandes volúmenes de datos. Esto se traduce en estrategias de marketing más precisas y personalizadas, basadas en el comportamiento real de los usuarios.
La segmentación basada en datos mejora campañas, optimiza precios y organiza catálogos, maximizando el retorno de inversión.
Los algoritmos de aprendizaje no supervisado son herramientas clave para analizar grandes volúmenes de datos y descubrir grupos de clientes con características similares. Cada algoritmo tiene sus propias ventajas dependiendo del tipo de datos y los objetivos comerciales. En el ámbito del e-commerce, tres métodos destacan por su efectividad en la segmentación: K-Means, clustering jerárquico y Self-Organizing Maps (SOM). A continuación, exploraremos cada uno de ellos.
K-Means es un algoritmo basado en centroides que organiza los datos en k grupos diferentes, minimizando la distancia entre los puntos de datos y el centro de su grupo asignado . Su rapidez y simplicidad lo convierten en una opción popular, especialmente para segmentar clientes según métricas como la frecuencia de compra o el valor del carrito.
Por ejemplo, en abril de 2021, el analista David Jaramillo utilizó K-Means con una base de datos de 7.248 clientes estadounidenses del dataset AdventureWorks2019. Al definir k = 3, identificó tres segmentos principales:
Este análisis permitió reasignar recursos de marketing de manera más eficiente, ya que el segmento más rentable, los "Profesionales de Alto Valor", era también el menos numeroso.
Sin embargo, K-Means tiene sus desafíos. Es sensible a valores atípicos y requiere definir previamente el número de clusters. Para determinar el valor óptimo de k, se utiliza el método del "codo", que grafica la suma de errores cuadrados (WCSS) y señala el punto donde la disminución en WCSS se vuelve menos pronunciada .
El clustering jerárquico organiza los datos en una estructura de grupos anidados, ya sea desde los elementos individuales hacia arriba (aglomerativo) o desde un grupo general hacia abajo (divisivo). Sus resultados se representan mediante dendrogramas, que facilitan la visualización de las relaciones entre subgrupos.
Este método es especialmente útil para analizar conjuntos de datos pequeños y para identificar patrones dentro de segmentos más amplios. Por ejemplo, dentro del grupo de "compradores frecuentes", el clustering jerárquico puede revelar microsegmentos con comportamientos ligeramente diferentes. Sin embargo, su eficiencia disminuye frente a grandes volúmenes de datos y es sensible al ruido. Algoritmos como BIRCH (Balanced Iterative Reducing and Clustering using Hierarchies) son reconocidos por manejar mejor estas limitaciones.
Los Self-Organizing Maps (SOM) ofrecen una forma visual de analizar datos complejos. Estas redes neuronales artificiales utilizan aprendizaje competitivo para transformar datos multidimensionales en una representación bidimensional, preservando las relaciones topológicas del espacio de entrada . A diferencia de K-Means, que agrupa datos en torno a centroides, los SOM colocan datos similares cerca unos de otros en el mapa, revelando patrones y relaciones ocultas.
Un caso destacado ocurrió en junio de 2021, cuando los investigadores Joaquín Cordero, Alfredo Bolt y Mauricio Valle desarrollaron un SOM de Kohonen para una cadena de supermercados en Santiago de Chile. Analizaron datos reales de transacciones para agrupar productos frecuentemente comprados juntos. Según los autores:
El resultado del SOM obtiene la relación entre los productos que fueron más comprados posicionándolos topológicamente cerca, para formar promociones, packs y bundles.
Este enfoque permitió crear paquetes de productos optimizados basados en el comportamiento real de los clientes, facilitando estrategias de ventas más efectivas. Aunque los SOM son ideales para visualizar datos de alta dimensionalidad y descubrir tendencias complejas, requieren un ajuste cuidadoso de parámetros y su interpretación puede ser más desafiante .
Después de explorar los algoritmos clave, veamos ejemplos concretos que muestran cómo estas técnicas están transformando estrategias en el mundo del retail y el e-commerce.
Saga Falabella, una reconocida cadena de tiendas por departamento, utilizó técnicas de clustering para segmentar su base de clientes y perfeccionar sus estrategias de marketing. Analizando patrones de compra y comportamiento, lograron identificar grupos específicos de consumidores. Esto les permitió personalizar ofertas y optimizar el uso de recursos publicitarios, lo que resultó en campañas promocionales mucho más efectivas.
La marca de cosméticos Clarins también apostó por el clustering no supervisado para mejorar la personalización de sus recomendaciones de productos. Analizando datos de navegación y compras previas, lograron segmentar a sus usuarios de manera dinámica. Este enfoque les permitió aumentar en un 45% la captación de clientes potenciales y alcanzar un retorno sobre la inversión (ROI) 30 veces mayor en solo 12 semanas.
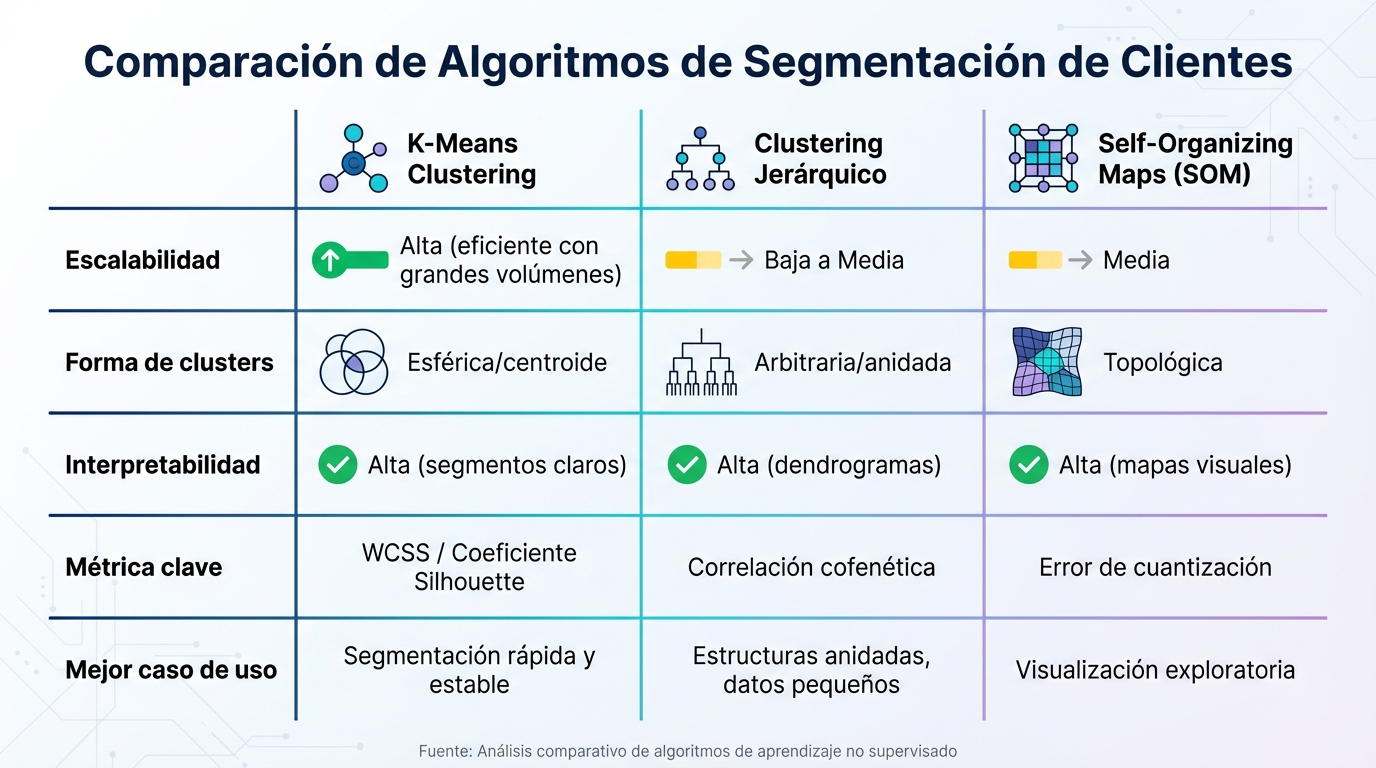
Comparación de algoritmos de segmentación: K-Means vs Clustering Jerárquico vs SOM
Cada técnica de segmentación tiene sus propias ventajas y aplicaciones específicas. Por ejemplo, K-Means se destaca por ser eficiente y confiable a largo plazo. Es ideal para identificar segmentos bien definidos y excluyentes entre sí. Sin embargo, tiene sus limitaciones: requiere que el número de grupos (k) se defina previamente y funciona mejor cuando los clusters tienen formas esféricas.
Por otro lado, los Mapas Auto-Organizados (SOM) son especialmente útiles cuando se trata de visualizar relaciones complejas. A diferencia de K-Means, los SOM pueden capturar patrones no lineales y representar datos de alta dimensionalidad en un mapa bidimensional fácil de interpretar. Esto los convierte en una herramienta valiosa para análisis exploratorios, aunque su entrenamiento requiere más recursos computacionales. Estas características explican por qué los SOM son tan efectivos para analizar y visualizar relaciones complejas en los datos.
"El SOM se muestra como una poderosa herramienta de visualización de datos, capaz de asistir el análisis de datos, proporcionando a los métodos supervisados capacidades explicativas útiles." - A. Vellido, Expert Systems with Applications
Finalmente, el clustering jerárquico es una excelente opción cuando querés entender estructuras anidadas, como jerarquías dentro de categorías de productos. Su principal inconveniente es la escalabilidad: funciona bien con conjuntos de datos pequeños o medianos, pero puede volverse lento y menos eficiente con grandes volúmenes de datos.
La siguiente tabla resume las características principales de cada algoritmo:
| Factor | K-Means | Clustering Jerárquico | SOM |
|---|---|---|---|
| Escalabilidad | Alta (eficiente con grandes volúmenes) | Baja a Media | Media |
| Forma de clusters | Esférica/centroide | Arbitraria/anidada | Topológica |
| Interpretabilidad | Alta (segmentos claros) | Alta (dendrogramas) | Alta (mapas visuales) |
| Métrica clave | WCSS / Coeficiente Silhouette | Correlación cofenética | Error de cuantización |
| Mejor caso de uso | Segmentación rápida y estable | Estructuras anidadas, datos pequeños | Visualización exploratoria |
Esta comparación ayuda a elegir el algoritmo más adecuado según los objetivos y las características del conjunto de datos.
Con los segmentos bien definidos, podés llevar tus estrategias de marketing a otro nivel. La segmentación te permite enfocar tus esfuerzos promocionales en subgrupos específicos, lo que ayuda a utilizar los recursos de manera más eficiente. En lugar de enviar un mensaje genérico a toda tu base de clientes, podés personalizar el contenido, el canal y las ofertas según las características de cada grupo.
Por ejemplo, si identificás un segmento de "clientes de alto valor" que prioriza la calidad sobre el precio, podrías enviarles ofertas exclusivas de productos premium a través de WhatsApp. Por otro lado, un grupo más sensible al precio podría recibir promociones con descuentos atractivos por Instagram. Esta diferenciación no solo mejora las conversiones, sino también el retorno sobre la inversión (ROI).
Plataformas como Burbuxa pueden ser clave en este proceso, ya que utilizan la segmentación comportamental para automatizar interacciones personalizadas en WhatsApp e Instagram. Con ayuda de inteligencia artificial, Burbuxa adapta el tono, las recomendaciones y las ofertas a cada perfil. Por ejemplo, un cliente identificado como "familia estable" recibiría sugerencias de productos orientados a un estilo de vida familiar, mientras que un joven profesional vería opciones alineadas con las últimas tendencias. Además, esta estrategia permite ajustar precios y reorganizar el catálogo de manera eficiente.
La segmentación también es una herramienta poderosa para ajustar precios y reorganizar catálogos de productos. Analizando patrones de co-compra con algoritmos como los SOM, podés identificar qué productos suelen comprarse juntos y diseñar paquetes o promociones específicas. Por ejemplo, si notás que un segmento familiar adquiere regularmente productos de cuidado personal para varios miembros del hogar, podrías ofrecer descuentos por volumen o armar bundles pensados para ese perfil.
Además, esta estrategia ayuda a identificar productos de baja demanda que no aportan valor significativo al negocio. Eliminar estos artículos del catálogo puede aumentar las ganancias al reducir costos asociados con su producción y distribución.
Los datos segmentados también son clave para campañas más precisas y efectivas. Estudios han demostrado que el clustering permite identificar grupos con alta propensión al gasto, lo que facilita diseñar campañas más ajustadas a sus necesidades.
"Una segmentación adecuada puede ser de inmenso valor para cualquier negocio para dirigir correctamente los esfuerzos de promoción de productos dependiendo de los grupos encontrados." - David Jaramillo
En la práctica, esto significa que podés usar WhatsApp para enviar ofertas de alto margen a segmentos "Elite" menos sensibles al precio, mientras que Instagram puede ser el canal para promociones dirigidas a un público más joven y consciente de los precios. Herramientas como Burbuxa simplifican esta tarea al integrar directamente los segmentos con los flujos de trabajo de campañas y mensajes oficiales de WhatsApp. Así, podés asegurarte de que el mensaje correcto llegue al cliente indicado en el momento perfecto.
El aprendizaje no supervisado ha cambiado radicalmente cómo entendemos a los clientes en el mundo del e-commerce. En lugar de depender de categorías rígidas y predefinidas, algoritmos como K-Means, clustering jerárquico y Self-Organizing Maps (SOM) analizan patrones de comportamiento para segmentar audiencias y perfeccionar estrategias de marketing, precios y gestión de productos.
Los números respaldan esta evolución: el mercado global de machine learning está proyectado a crecer de US$ 37,92 mil millones en 2023 a US$ 425,37 mil millones para 2031. Empresas como Amazon ya utilizan técnicas de clustering para mejorar sus motores de recomendación y potenciar estrategias de cross-selling. Por otro lado, el Departamento del Tesoro de Estados Unidos logró prevenir y recuperar más de US$ 4.000 millones en pagos fraudulentos durante 2024, gracias, en parte, a la detección de anomalías.
"El aprendizaje no supervisado permite que los algoritmos detecten patrones y segmenten datos sin intervención humana, lo que acelera la toma de decisiones en escenarios empresariales complejos."
– Gonzalo Castillo, IT Masters Mag
Sin embargo, identificar segmentos no es suficiente; el verdadero desafío está en convertir esos conocimientos en acciones concretas. Herramientas como Burbuxa están llevando esta segmentación al siguiente nivel al integrar perfiles de clientes en flujos automatizados en plataformas como WhatsApp e Instagram. Esto permite personalizar mensajes y ofertas en tiempo real, maximizando las conversiones y el ROI.
Con los métodos y casos analizados, queda claro que el futuro de la segmentación se dirige hacia sistemas que no solo aprenden y se ajustan, sino que también actúan de manera autónoma. Al combinar el aprendizaje no supervisado con herramientas que automatizan la ejecución, las marcas tienen la oportunidad de transformar datos en un crecimiento sostenible y duradero.
El método del codo es una de las técnicas más utilizadas para decidir cuántos clusters usar al aplicar K-Means. Este enfoque implica ejecutar el algoritmo con distintos valores de K y analizar cómo disminuye la variación dentro de los clusters. En la gráfica resultante, el punto donde esta reducción comienza a estabilizarse (formando un "codo") señala el número ideal de clusters, logrando un equilibrio entre simplicidad y precisión.
Pero no todo termina ahí. También existen otros índices, como el índice de Davies-Bouldin y el índice de Calinski-Harabasz, que pueden aportar más claridad. Estas métricas evalúan tanto la cohesión interna de los clusters como la separación entre ellos, proporcionando una perspectiva más sólida. Usar una combinación de estas herramientas permite ajustar la solución de manera más adecuada a las características específicas de los datos.
El clustering jerárquico ofrece varias ventajas importantes para la segmentación de clientes. Una de las principales es su capacidad para generar un dendrograma, una representación en forma de árbol que ilustra las relaciones jerárquicas entre los datos. Esto permite identificar grupos naturales y explorar cómo se organizan los clientes en distintos niveles de similitud, sin necesidad de establecer previamente la cantidad de clusters.
Otra característica destacada es su versatilidad. Puede aplicarse de manera aglomerativa (comenzando desde los elementos individuales y agrupándolos) o divisiva (partiendo de un grupo general y dividiéndolo), lo que lo hace adaptable a diferentes enfoques analíticos. Además, no exige definir de antemano el número de grupos, lo que resulta ideal cuando no se tiene claridad sobre la cantidad de segmentos.
Finalmente, el clustering jerárquico permite descubrir patrones complejos y analizar los datos en diferentes niveles de detalle. Esto es especialmente útil para crear estrategias de marketing más precisas, identificando subgrupos dentro de segmentos más grandes. Gracias a estas capacidades, se convierte en una herramienta clave para una segmentación de clientes más efectiva y personalizada.
Los Mapas Autoorganizados (SOM, por sus siglas en inglés) son una herramienta poderosa para simplificar el análisis de datos complejos. Transforman información de alta dimensión en mapas bidimensionales que son mucho más fáciles de interpretar. Esto permite detectar patrones y agrupaciones en grandes volúmenes de datos que, de otro modo, serían complicados de analizar.
En el ámbito de la segmentación de clientes, los SOM son especialmente útiles para identificar grupos con características o comportamientos similares. Esto no solo facilita diseñar estrategias personalizadas para cada segmento, sino que también mejora la efectividad de las campañas de marketing y respalda decisiones más acertadas. Además, los mapas ofrecen una representación visual clara de las relaciones entre diferentes segmentos, ayudando a comprender mejor las necesidades de los clientes y a anticipar sus preferencias con mayor precisión.