
¿Sabías que el fraude online le costó a las empresas más de $38.000 millones de dólares en 2023? Y eso no es todo: se espera que esta cifra supere los $362.000 millones en los próximos cinco años. Cada transacción rechazada por error no solo representa una venta perdida, sino también la confianza del cliente. La detección de fraude en tiempo real es un desafío que requiere precisión y velocidad, ya que los sistemas tienen apenas 200 milisegundos para decidir.
Para mejorar tus modelos, es clave elegir las características correctas. Estas son las más útiles:
Además, los métodos de selección como filtros, envolturas y técnicas embebidas permiten encontrar un balance entre velocidad y precisión. Usar métricas específicas para conjuntos desbalanceados y pruebas en tiempo real garantiza resultados confiables sin afectar la experiencia del usuario.
El resultado: sistemas que detectan fraudes en milisegundos, mejoran la seguridad y reducen falsos positivos, protegiendo tanto a tu negocio como a tus clientes.
Para que un modelo sea efectivo, debe combinar diversas señales que permitan, en cuestión de milisegundos, diferenciar entre un cliente legítimo y un estafador.
Un cambio abrupto en el gasto mensual, como pasar de $5.000 a $50.000, genera una alerta inmediata. La velocidad de las transacciones también es clave: múltiples compras en segundos pueden ser señal de ataques automatizados o "carding". Además, el BIN (Bank Identification Number) de la tarjeta ayuda a validar si el país emisor coincide con la ubicación del usuario, detectando posibles inconsistencias geográficas.
Otros factores importantes incluyen el tiempo desde la creación de la cuenta. Las cuentas nuevas que realizan compras de alto valor de inmediato representan un mayor riesgo. También es útil analizar la moneda utilizada y el uso excesivo de códigos promocionales, lo que podría indicar "bonus abuse".
El análisis del comportamiento del usuario refuerza la detección de fraude en tiempo real. La biometría conductual, como la velocidad al tipear, los movimientos del mouse o la presión táctil en dispositivos móviles, permite diferenciar entre humanos y bots. Los sistemas avanzados crean un perfil de comportamiento normal para cada usuario, evaluando hábitos de navegación, frecuencia de inicio de sesión y patrones de compra. Si un usuario se desvía de su comportamiento habitual, como realizar sesiones muy cortas o movimientos del mouse extraños, se disparan alertas automáticas.
En 2020, ActiveCampaign implementó Amazon Fraud Detector para identificar registros fraudulentos, demostrando cómo los datos de comportamiento pueden prevenir ataques de phishing.
La dirección IP y la geolocalización son herramientas esenciales para identificar anomalías. Por ejemplo, si un usuario que suele comprar desde Buenos Aires aparece conectado desde Rumania, la transacción merece una revisión. El fingerprinting de dispositivo genera una huella digital única basada en la configuración de hardware y software, ayudando a rastrear estafadores que operan con múltiples cuentas.
También resulta valioso analizar el tipo de navegador, su versión y el sistema operativo, ya que los cibercriminales suelen usar emuladores o configuraciones específicas. En 2024, la red de fraude china "BogusBazaar" creó 75.000 sitios web falsos de comercio electrónico, procesando casi $50 millones en pedidos fraudulentos y robando datos de tarjetas de crédito de más de 850.000 personas. Detectar este tipo de operaciones requiere combinar datos de dispositivo con información de dominio, como la antigüedad del sitio web, ya que los dominios fraudulentos suelen ser muy recientes.
Además de los datos transaccionales y de comportamiento, las conexiones entre cuentas ofrecen una dimensión crítica en la detección de fraude. Las relaciones entre usuarios, cuentas y transacciones pueden revelar redes organizadas. Si varias cuentas comparten la misma dirección IP, dispositivo o utilizan dominios de correo similares, es probable que se trate de un esquema coordinado.
Bank Rakyat Indonesia (Bank BRI) implementó Confluent Platform y Apache Kafka para procesar datos de transacciones y contexto en tiempo real. Kaspar Situmorang, Executive Vice President de Bank BRI, afirmó: "Confluent Platform and Apache Kafka have helped us turn Bank BRI into the most profitable bank in Indonesia by allowing us to create and deploy real-time event-driven systems for credit scoring."
Analizar estas conexiones permite identificar patrones de colusión y detectar cuando un estafador opera bajo múltiples identidades. Procesar estos datos en tiempo real es crucial para evitar retrasos que afecten la experiencia del usuario. Estos enfoques integrados son clave para construir sistemas de selección y validación efectivos en tiempo real.
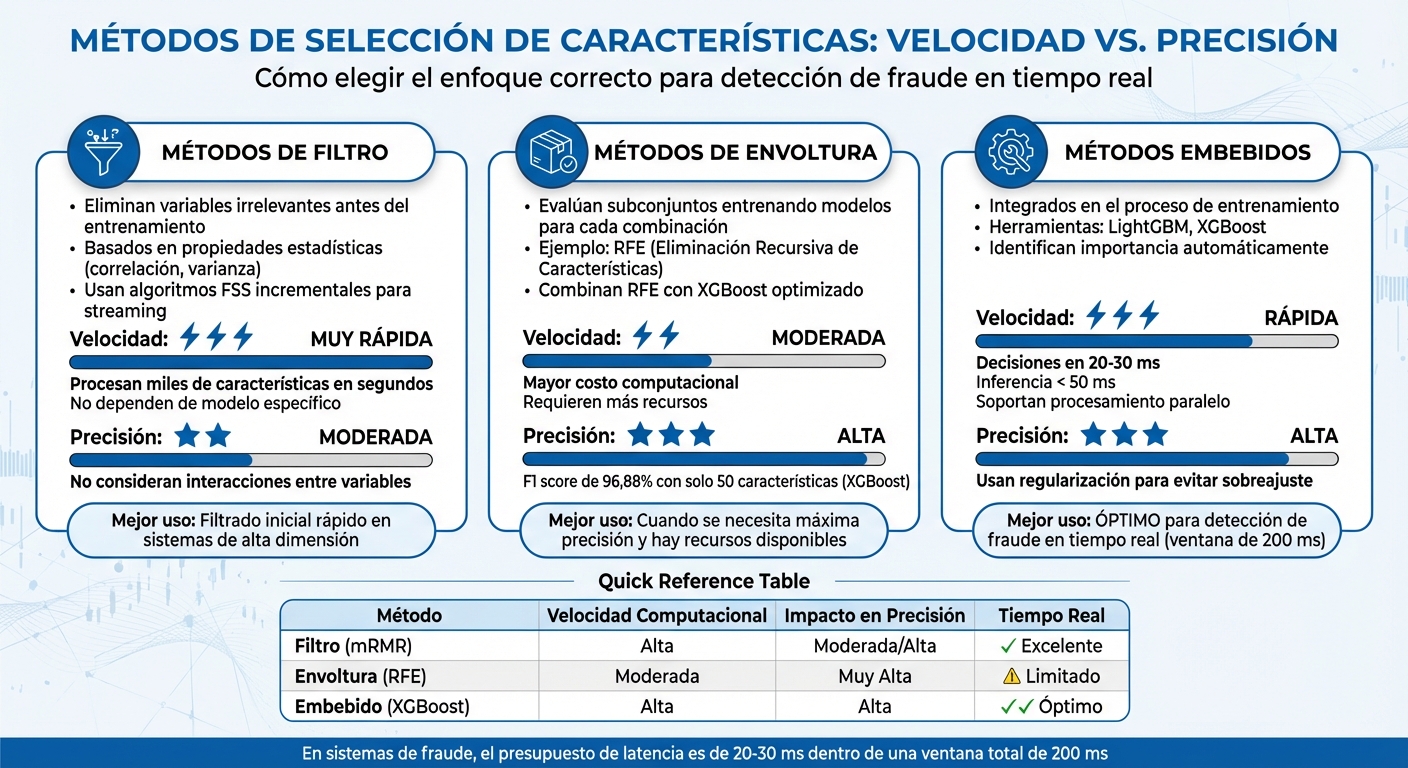
Comparación de métodos de selección de características para detección de fraude en tiempo real
Una vez que se identifican las características relevantes, el siguiente reto es elegir cuáles usar sin afectar la velocidad del sistema. En entornos de streaming, donde cada milisegundo cuenta, hay tres enfoques que logran un balance entre precisión y rapidez. Aquí te cuento más sobre estos métodos y cómo se aplican.
Los métodos de filtro son como un primer colador: eliminan características irrelevantes o redundantes antes de que el modelo siquiera comience a entrenarse. Se basan en propiedades estadísticas como la correlación entre variables o la varianza. Por ejemplo, si dos variables están muy correlacionadas (como "monto de la transacción" y "monto en pesos"), se puede descartar una sin perder información clave.
En sistemas de streaming, los algoritmos FSS (Feature Subset Selection) incrementales son los favoritos porque actualizan los pesos de las características a medida que llegan nuevos datos.
"Los algoritmos FSS tradicionales por lotes pueden no ser adecuados para manejar eficientemente grandes volúmenes de datos, ya sea porque surgen problemas de memoria o porque los datos se reciben de manera secuencial." - Carlos Villa Blanco, investigador de la Universidad Politécnica de Madrid
La gran ventaja de estos métodos es su rapidez: pueden procesar miles de características en segundos y no dependen de un modelo específico. Sin embargo, tienen una limitación importante: no consideran cómo interactúan las variables entre sí, lo que podría resultar en la pérdida de combinaciones valiosas. Son perfectos para un filtrado inicial rápido, pero no para análisis más complejos.
Los métodos de envoltura (wrapper methods) evalúan subconjuntos de características entrenando un modelo predictivo para cada combinación posible. Un ejemplo conocido es la Eliminación Recursiva de Características (RFE), que elimina progresivamente las variables menos útiles. En streaming, combinar RFE con XGBoost optimizado permite seleccionar características de forma efectiva, aunque a un costo computacional mayor.
En un estudio de septiembre de 2025 sobre detección de fraude en e-commerce, un modelo XGBoost optimizado con solo 50 características alcanzó un F1 score de 96,88%. Esto demuestra que una selección bien hecha puede igualar el rendimiento de modelos más complejos. Sin embargo, estos métodos requieren más recursos para mantener tiempos de respuesta aceptables, lo que puede ser un desafío en sistemas que necesitan rapidez.
Los métodos embebidos integran la selección de características directamente en el proceso de entrenamiento del modelo. Herramientas como LightGBM y XGBoost identifican automáticamente la importancia de cada variable mientras construyen el modelo, eliminando la necesidad de pasos separados. Esto es clave en escenarios como la detección de fraude, donde las decisiones deben tomarse en 20–30 ms dentro de una ventana total de autorización de aproximadamente 200 ms.
"Lo que hace destacar a XGBoost es su uso de regularización, que ayuda a controlar el sobreajuste y mejorar la precisión... También soporta procesamiento paralelo, lo que permite tiempos de entrenamiento más rápidos." - insightsoftware
Estos métodos priorizan características que pueden calcularse internamente, asegurando que el tiempo de inferencia del modelo se mantenga por debajo de 50 ms. Por ejemplo, usar análisis de URL o HTML como características "standalone" permite mantener una experiencia fluida para el usuario final, incluso en sistemas que operan a gran velocidad.
Para verificar cómo funcionan las características en producción, es clave procesar transacciones reales. En entornos de fraude, donde este representa apenas el 0,172% de las transacciones, confiar exclusivamente en métricas tradicionales como la precisión puede llevar a conclusiones erróneas. Por ejemplo, un modelo que clasifique todas las transacciones como legítimas alcanzaría un 99,9% de precisión, pero no detectaría ni un solo caso de fraude.
Una vez definidas las características, es crucial evaluarlas con métricas diseñadas para conjuntos de datos desbalanceados. En sistemas de detección de fraude, las métricas deben centrarse en la clase minoritaria. Por esta razón, el AUC-PR (Área bajo la curva de Precisión-Recall) resulta más útil que el AUC-ROC, ya que mide cómo el modelo identifica fraudes sin generar demasiadas falsas alarmas.
"En datos altamente desbalanceados como la detección de fraude, el AUC-PR es más informativo que el AUC-ROC porque responde qué tan bien el modelo balancea Precisión y Recall donde realmente importa." - Cesar Soto Valero, PhD en Ciencias de la Computación
Otra métrica importante es la Card Precision @k, que mide cuántos fraudes se detectan entre los "k" casos más sospechosos. En la práctica, una tasa de falsos positivos (FPR) mayor a 0,001 (0,1%) suele ser inaceptable, ya que genera más alertas de las que un equipo humano puede manejar.
A diferencia de otros modelos de machine learning, los sistemas de detección de fraude no pueden usar validación cruzada aleatoria. Esto se debe a que los patrones de fraude cambian constantemente. Por ello, se utiliza validación temporal: se entrena con datos de una semana y se prueba con los de la siguiente. Este enfoque garantiza que el modelo pueda identificar fraudes futuros en lugar de limitarse a patrones pasados.
Algunos sistemas avanzados implementan modelos adaptativos diarios, que se reentrenan cada 24 horas para mantenerse actualizados frente a las nuevas técnicas de fraude. Esto es especialmente importante si consideramos que el fraude de pagos autorizados (APPF) constituye el 75% del fraude bancario digital a nivel global. Este enfoque no solo mejora la precisión, sino que también minimiza los falsos positivos.
Para validar estos resultados, se recomienda probar nuevas características en modo sombra. En este enfoque, el nuevo modelo procesa transacciones reales en paralelo al sistema actual, pero sin influir en las decisiones de aprobación o rechazo. Esto permite comparar el rendimiento del modelo con los resultados reales sin poner en riesgo las operaciones.
En producción, es esencial monitorear la latencia de decisión (ODL), que mide cuánto tiempo tarda el modelo en calificar cada transacción.
"La latencia y la complejidad importan en los sistemas de pago... cualquier fluctuación (como un problema de red o una respuesta lenta de un tercero) puede crear un cuello de botella en todo el flujo." - Cesar Soto Valero, PhD en Ciencias de la Computación
Seleccionar características para modelos de fraude en tiempo real puede convertirse en un reto técnico, afectando tanto la precisión como la velocidad de respuesta. Estos inconvenientes suelen aparecer una vez que el modelo ya está en producción, por lo que es clave anticiparlos durante la fase de diseño y selección de variables. Aquí te explicamos cómo abordar estos desafíos.
La redundancia entre características similares no solo reduce el rendimiento del modelo, sino que también aumenta el riesgo de sobreajuste. Por ejemplo, en el conocido dataset de Kaggle sobre fraude con tarjetas de crédito, donde apenas 492 de 284.807 transacciones (0,172%) son fraudulentas, cada característica debe ser precisa para minimizar falsas alarmas.
"Cuando las variables tienen distribuciones similares, tienden a capturar patrones o información similar, lo que puede llevar a redundancia en el modelo." - Carmen Scartezini, Data Scientist
Para identificar esta redundancia, podés usar el Factor de Inflación de Varianza (VIF). Si el VIF supera 5 o 10, es señal de que una característica está altamente correlacionada con otras y podría eliminarse. Además, calcular una matriz de correlación te permitirá detectar variables redundantes con coeficientes mayores a 0,4, ayudándote a decidir cuál aporta más valor único.
Los patrones de fraude evolucionan constantemente, lo que puede volver obsoletas las características que antes funcionaban bien. Mientras que los modelos basados en árboles como XGBoost o Random Forest requieren reentrenamiento completo, las redes neuronales permiten un aprendizaje incremental, adaptándose a los datos más recientes sin necesidad de empezar desde cero.
Para detectar la pérdida de efectividad en las características, utilizá el test KS de manera periódica. Si los valores del "D-test" disminuyen con el tiempo, significa que una variable ya no distingue de forma efectiva entre clases y debería reemplazarse. Por ejemplo, si la diferencia en distribuciones entre transacciones fraudulentas y legítimas cae por debajo del 11%, la característica pierde valor discriminatorio. También podés aplicar validación prequencial, entrenando con datos históricos y probando en períodos recientes, para garantizar que las características sigan siendo útiles frente a nuevas tácticas de fraude.
El framework mRMR (Minimum Redundancy Maximum Relevance) es una herramienta útil para seleccionar variables predictivas que no estén correlacionadas entre sí, especialmente al incorporar nuevas fuentes de datos. Para modelos de gran escala, priorizá métodos como la importancia integrada del modelo (como el "gain" en XGBoost), ya que los valores SHAP, aunque más detallados, requieren cálculos adicionales y son más costosos computacionalmente.
En sistemas de tiempo real, cada milisegundo cuenta. Las variables que dependen de servicios externos pueden aumentar significativamente la latencia, por lo que deben evitarse en este contexto. Es preferible priorizar variables internas, ya que un modelo que utiliza únicamente datos internos puede alcanzar un F1 score de 96,53%, un rendimiento casi idéntico al 96,88% de un modelo que incluye recursos externos, pero con menor latencia.
| Método de selección | Velocidad computacional | Impacto en precisión | Adecuación para tiempo real |
|---|---|---|---|
| Métodos de filtro (mRMR) | Alta | Moderada/Alta | Excelente para datos de alta dimensión |
| Importancia integrada | Alta | Alta | Óptimo para producción a gran escala |
| Valores SHAP | Baja | Muy Alta | Mejor para análisis offline |
| Características de APIs externas | Muy Baja | Alta | Deficiente; causa retrasos en pagos rápidos |
En 2024, el Departamento del Tesoro de Estados Unidos logró prevenir y recuperar más de US$4.000 millones en fraude gracias a procesos mejorados de detección en tiempo real y machine learning. Para replicar este éxito, evaluá el tiempo de respuesta de cada característica: si una variable mejora la precisión pero es lenta de obtener, es mejor excluirla de las decisiones en tiempo real.
Además, implementá autenticación basada en riesgo (RBA) para activar medidas adicionales, como autenticación de dos factores, solo en casos de alto riesgo. Esto permite que las transacciones legítimas y de bajo riesgo se procesen rápidamente. Recordá que el 67% de los consumidores están dispuestos a abandonar una transacción si los procedimientos de autenticación son complejos o lentos.
Para reducir la latencia en la detección de fraude, es clave priorizar características internas. Las consultas a APIs de terceros pueden generar retrasos impredecibles que afectan el flujo de autorización. Un ejemplo claro: un modelo basado únicamente en datos internos logró un F1 score de 96,53%, apenas por debajo del 96,88% obtenido con datos externos, pero con tiempos de respuesta mucho más rápidos. Esto demuestra que, con los mecanismos adecuados, es posible reaccionar con rapidez ante anomalías.
Además, es recomendable usar feature flags para desactivar rápidamente variables vulnerables durante un ataque activo. Esta herramienta permite cambiar a una versión de respaldo del modelo sin necesidad de redesplegar código. También es esencial monitorear los percentiles 90 y 99, además de los promedios, ya que los ataques adversariales suelen manifestarse en los extremos de la distribución. Este enfoque complementa el control de la latencia, que es crítico en sistemas que deben operar en ventanas de autorización de 20–30 ms.
"La única solución sostenible a largo plazo es aceptar que los modelos orientados al usuario eventualmente serán manipulados y tener un cronograma de reentrenamiento frecuente - para que los puntos ciegos se incorporen rápidamente en el próximo ciclo de reentrenamiento." - Felipe Almeida, Staff Data Scientist, Nubank
El reentrenamiento diario se vuelve indispensable para enfrentar técnicas de fraude en constante evolución. Antes de implementar cambios, es útil ejecutar nuevos modelos en modo shadow. Esto permite evaluar su desempeño con datos en vivo sin afectar las transacciones reales. Este enfoque asegura que los nuevos modelos mantengan los tiempos de respuesta necesarios para operar en tiempo real.
En sistemas de tiempo real, el presupuesto de latencia para verificaciones de fraude suele ser de apenas 20–30 ms, dentro de una ventana total de autorización de aproximadamente 200 ms.
Para combatir el fraude en tiempo real de manera eficaz, es fundamental centrarse en elementos clave que ayuden a identificar comportamientos sospechosos. Algunas de las estrategias más efectivas incluyen:
Cuando estas técnicas se combinan con herramientas de inteligencia artificial, es posible prevenir el fraude de manera ágil y precisa, asegurando la protección tanto de las empresas como de sus clientes.
Reducir los falsos positivos en la detección de fraude en tiempo real requiere un enfoque cuidadoso y bien planificado. Uno de los pasos clave es priorizar la selección de características relevantes y aplicar técnicas que equilibren los datos. Esto puede incluir ajustes en los umbrales de decisión, la ponderación de clases desbalanceadas y el uso de métodos de muestreo para nivelar los datos. Estas acciones no solo mejoran la precisión del modelo, sino que también preservan su habilidad para identificar fraudes de manera efectiva.
Otra pieza fundamental es medir el rendimiento del modelo utilizando métricas específicas, como la tasa de falsos positivos (FPR). Evaluar estas métricas permite ajustar los parámetros para encontrar un equilibrio entre precisión y sensibilidad, asegurando que el modelo sea eficiente sin generar interrupciones innecesarias.
En definitiva, combinar un análisis detallado de datos históricos, una selección precisa de características y ajustes constantes puede reducir drásticamente los falsos positivos. Esto beneficia tanto a los usuarios, que disfrutan de una experiencia más fluida, como a las empresas, que optimizan sus procesos de detección de fraude.
Cuando se trata de modelos de detección de fraude en tiempo real, elegir las características correctas es clave para lograr resultados rápidos y efectivos en escenarios dinámicos. Es fundamental centrarse en métodos que analicen tres aspectos esenciales: relevancia, redundancia y cooperación entre los atributos. Esto permite identificar patrones complejos que pueden marcar la diferencia en la precisión del modelo.
Entre las técnicas más útiles se encuentran el análisis estadístico, como la correlación, combinado con métodos que evalúan la importancia de las características basándose en modelos. Además, las herramientas automáticas para la ingeniería de características pueden ahorrar tiempo y mejorar los resultados. Otro aspecto crítico es emplear algoritmos que se ajusten rápidamente a los cambios en los patrones de fraude, ya que estos pueden evolucionar constantemente. Por último, es vital priorizar métricas que midan el impacto de los falsos positivos y negativos en tiempo real, ya que estos errores pueden tener consecuencias significativas.
En pocas palabras, el proceso de selección de características debe ser rápido, eficiente y capaz de captar relaciones complejas en los datos para optimizar la detección de fraude en entornos que cambian constantemente.