
El fraude online crece al ritmo del comercio electrónico, que alcanzará los $8,03 billones para 2027. Las pérdidas por fraude superarán los $362.000 millones en los próximos cinco años, y los métodos tradicionales no logran frenar esta ola. Las redes neuronales convolucionales (CNN) emergen como una solución clave para detectar patrones complejos en transacciones y comportamientos, abordando amenazas como el robo de datos biométricos y sitios fraudulentos.
La integración de CNN con técnicas avanzadas y datos multimodales redefine cómo enfrentamos el fraude online, ofreciendo herramientas más precisas y eficientes para proteger el comercio digital.
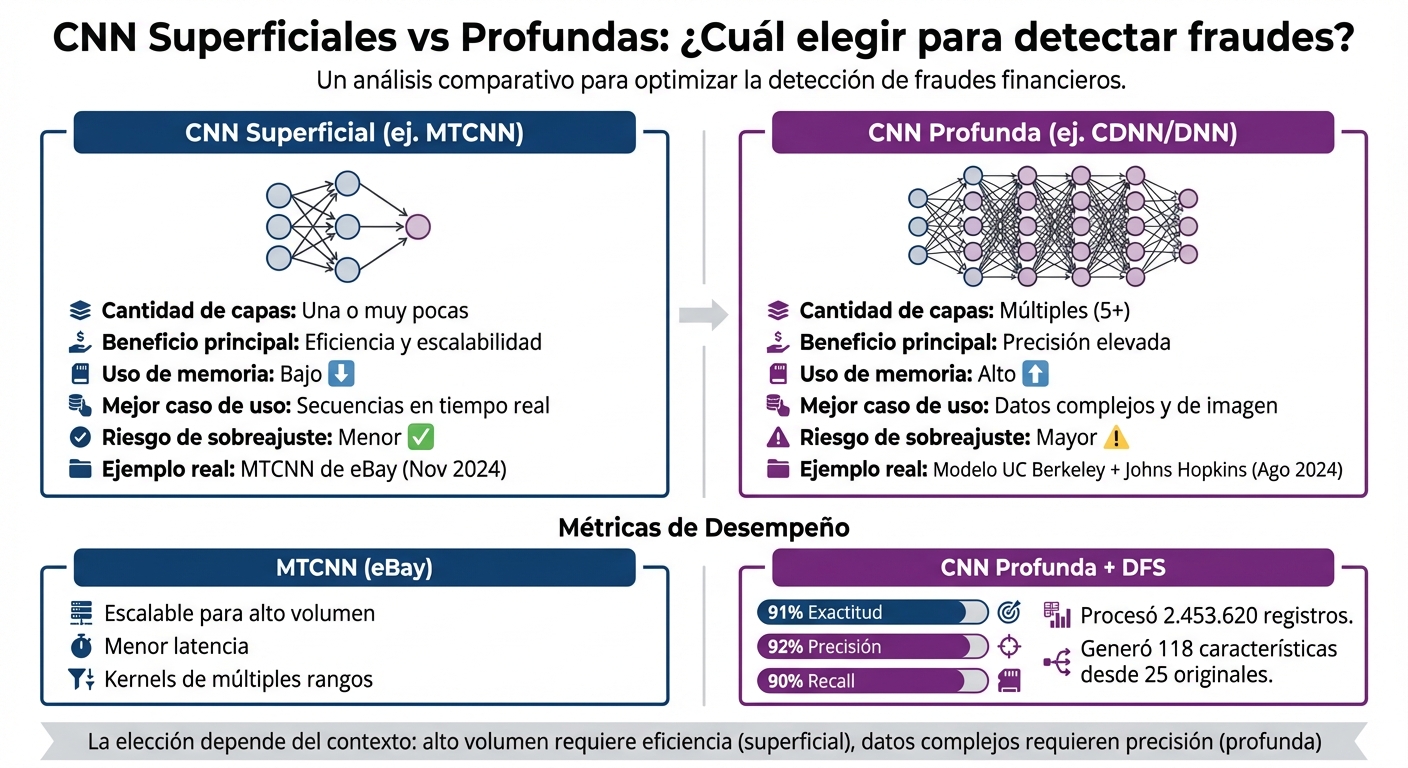
Comparación de arquitecturas CNN superficiales vs profundas para detección de fraudes
Las redes neuronales convolucionales (CNN) procesan datos transaccionales de una manera distinta a los sistemas tradicionales. En lugar de basarse en reglas predefinidas o características seleccionadas manualmente, estas redes aprenden automáticamente qué patrones son importantes. Su arquitectura incluye capas especializadas que trabajan en conjunto: las capas convolucionales actúan como detectores automáticos de patrones, identificando detalles locales y consolidándolos en señales más generales al eliminar redundancias y ruido. A continuación, exploramos las funciones clave de las capas convolucionales y de pooling.
Estas redes no solo analizan datos estructurados como montos y horarios, sino también datos no estructurados como secuencias de comportamiento o imágenes. Un ejemplo destacado es el modelo desarrollado en agosto de 2018 por investigadores de la Universidad de Donghua para un banco comercial. Este modelo procesaba transacciones B2C a través de una "capa de secuenciación de características" que reorganizaba 62 dimensiones de datos antes de pasarlas por cuatro capas alternas de convolución y pooling.
"La función de la capa convolucional es extraer la característica local de los datos de entrada; la capa convolucional derivará automáticamente nuevas características basándose en las características de entrada."
– Zhaohui Zhang, Escuela de Ciencias de la Computación y Tecnología, Universidad de Donghua
Las capas convolucionales emplean un mecanismo llamado "kernel" que escanea los datos transaccionales en busca de patrones específicos. En el contexto de detección de fraudes, los kernels de diferentes tamaños permiten identificar tanto anomalías en transacciones individuales como tendencias en múltiples sesiones.
Por otro lado, las capas de pooling, especialmente el max-pooling, seleccionan las características más relevantes de cada región, descartando información innecesaria. Esto reduce significativamente la cantidad de datos que la red necesita procesar. Un avance notable en este campo fue el modelo MTCNN (Multi-task CNN) desarrollado por el equipo de eBay en noviembre de 2024. Este modelo utilizó una sola capa convolucional con kernels de múltiples rangos y codificación posicional para analizar secuencias de navegación, como el ID de página, la categoría del artículo y el tiempo de permanencia. Su diseño resultó ser más escalable que los modelos basados en Transformers, manteniendo un rendimiento competitivo en datos reales de comercio electrónico.
"Las CNN usan un mecanismo especializado de 'kernel' que les permite identificar rápidamente comportamientos anómalos o fraudulentos en períodos cortos de tiempo."
– Bo Qu, Decision Sciences, eBay
Este enfoque mejora significativamente la paralelización en comparación con modelos como LSTM y Transformers, reduciendo el consumo de memoria y aumentando la eficiencia computacional.
La diferencia entre modelos CNN profundos y superficiales radica en el número de capas que utilizan. Los modelos superficiales, como el MTCNN de eBay, emplean una o muy pocas capas convolucionales. Esto los hace más eficientes, con menor uso de memoria y menor riesgo de sobreajuste, especialmente cuando se dispone de datos limitados para entrenar. En contraste, los modelos profundos integran múltiples capas de convolución y pooling, lo que les permite capturar relaciones más complejas y no lineales en los datos.
Un ejemplo de modelo profundo es el desarrollado en agosto de 2024 por investigadores de la Universidad de California, Berkeley, y la Universidad Johns Hopkins. Este modelo, combinado con Deep Feature Synthesis (DFS), procesó un conjunto de datos de 2.453.620 registros para detectar fraudes en tarjetas de crédito. A partir de 25 características originales, DFS generó 118 nuevas, y el modelo CNN alcanzó un desempeño sobresaliente: 91% de exactitud, 92% de precisión y 90% de recall, superando algoritmos tradicionales como Regresión Logística y Random Forest.
La elección entre un modelo superficial o profundo depende del contexto. Para entornos de comercio electrónico con alto volumen de transacciones, donde la latencia es crítica, las CNN superficiales con kernels de múltiples rangos ofrecen un equilibrio ideal entre capacidad de modelado y eficiencia. Sin embargo, cuando se manejan datos transaccionales complejos o imágenes de productos, los modelos profundos suelen ser más efectivos.
| Característica | CNN Superficial (ej. MTCNN) | CNN Profunda (ej. CDNN/DNN) |
|---|---|---|
| Cantidad de capas | Una o muy pocas | Múltiples (5+) |
| Beneficio principal | Eficiencia y escalabilidad | Precisión elevada |
| Uso de memoria | Bajo | Alto |
| Mejor caso de uso | Secuencias en tiempo real | Datos complejos y de imagen |
| Riesgo de sobreajuste | Menor | Mayor |
Esta comparación entre arquitecturas proporciona una base sólida para entender los desafíos y soluciones en la implementación de CNN para combatir el fraude.
Cuando se combinan las CNN con otros algoritmos, se mejora tanto la precisión como la capacidad del sistema para adaptarse a diferentes escenarios. Esta sinergia aprovecha lo mejor de ambos mundos: las CNN son excelentes para identificar patrones complejos, mientras que otros métodos se enfocan en detectar anomalías y clasificar con eficiencia.
Un enfoque común es usar las CNN para procesar datos no estructurados o secuenciales en una primera etapa. Los resultados de este procesamiento inicial se introducen luego en algoritmos de aprendizaje automático más tradicionales, que toman la decisión final. Este modelo híbrido ha demostrado alcanzar tasas de precisión superiores al 91% en entornos reales de comercio electrónico. A continuación, exploramos algunos de los métodos que suelen combinarse con las CNN.
Los algoritmos de detección de anomalías, como Isolation Forest o Principal Component Analysis (PCA), son herramientas clave para identificar transacciones que se desvían del comportamiento esperado. Cuando se integran con CNN, el proceso se desarrolla en dos fases: primero, la CNN extrae automáticamente características de los datos transaccionales; luego, una capa de detección de anomalías analiza esas características para identificar posibles comportamientos irregulares.
Un enfoque particularmente interesante incluye una "capa de secuenciación de características" antes de la CNN. Esta capa reorganiza los atributos de las transacciones en patrones más óptimos, lo que permite que la red aprenda características derivadas más útiles para detectar fraudes. Además, este método es eficaz para trabajar con datos de baja dimensión sin necesidad de transformaciones previas. En sistemas híbridos, las CNN procesan datos secuenciales, como historiales de transacciones, mientras que los algoritmos de detección de anomalías identifican patrones de fraude "día cero", es decir, aquellos que no han sido etiquetados en los conjuntos de entrenamiento.
"La ventaja de este modelo radica en tomar datos de transacciones en línea de baja dimensión y no derivados como entrada."
– Zhaohui Zhang
Estas técnicas de detección de anomalías suelen combinarse con métodos de ensamble para maximizar la precisión del sistema.
Los métodos de ensamble integran CNN con otros modelos de aprendizaje automático, como Support Vector Machines (SVM), Random Forest o XGBoost, mediante técnicas como stacking o boosting. Este enfoque combina la habilidad de las CNN para extraer características complejas con la capacidad de los algoritmos tradicionales para clasificar con gran precisión.
Estos métodos son especialmente útiles en el procesamiento de datos multimodales. Por ejemplo, las CNN pueden encargarse de analizar datos no estructurados, como imágenes o texto, mientras que modelos como gradient-boosting se ocupan de datos estructurados, como registros transaccionales. Sin embargo, esta combinación aumenta la complejidad computacional y puede ralentizar el tiempo de respuesta, lo que representa un desafío en entornos de alto volumen donde la detección en tiempo real es crucial.
La integración de estas técnicas no solo mejora la precisión, sino que también permite abordar los desafíos de procesar distintos tipos de datos en la detección de fraudes, marcando un avance importante en este campo.
Las redes neuronales convolucionales (CNN) modernas no se limitan a manejar un único tipo de información. Estas redes tienen la capacidad de procesar simultáneamente datos transaccionales, comportamentales y no estructurados, como imágenes y texto. Esta capacidad para manejar múltiples tipos de datos resulta crucial para identificar fraudes complejos que combinan varias señales de riesgo.
El procesamiento integrado permite que las CNN identifiquen relaciones complejas entre diferentes fuentes de datos. Por ejemplo, una transacción de $50.000 podría parecer normal aislada, pero si se combina con un patrón de navegación errático o un tiempo de permanencia inusualmente breve en la página de pago, la red puede identificar señales de alerta que otros sistemas podrían pasar por alto. A continuación, exploramos cómo estas redes combinan distintos tipos de datos utilizando técnicas avanzadas de embedding.
Gracias a su capacidad multimodal, las CNN pueden integrar datos de comportamiento y transacciones mediante capas de embedding. Estas capas convierten variables categóricas en representaciones densas y normalizan las variables continuas, optimizando su procesamiento.
Una técnica particularmente efectiva es la capa de secuenciación de características, que organiza automáticamente los atributos transaccionales en patrones ideales para el análisis convolucional. Esto elimina la necesidad de realizar una ingeniería manual de características, permitiendo que la red aprenda de forma autónoma las relaciones más relevantes. En un caso práctico, un banco comercial implementó esta técnica, logrando una precisión del 91% y un recall del 94%, lo que representó un aumento del 26% en comparación con una CNN estándar.
Para capturar la naturaleza secuencial del comportamiento del usuario, las CNN utilizan codificación posicional, ya sea fija o aprendible, que incorpora señales temporales en los datos. Además, los kernels de múltiples rangos permiten detectar patrones de comportamiento tanto a corto plazo (como clics rápidos sospechosos) como a largo plazo (cambios en el historial de la cuenta), logrando un análisis más completo.
El análisis de datos no estructurados, como chats, correos electrónicos o capturas de pantalla, plantea desafíos únicos en la detección de fraudes. Las CNN modernas abordan estos retos mediante arquitecturas multimodales que combinan el análisis de imágenes con el procesamiento de texto. Por ejemplo, en la detección de "tiendas falsas", se pueden analizar capturas de pantalla para identificar logos copiados de marcas legítimas.
El procesamiento de texto requiere pasos previos, como la eliminación de etiquetas y la normalización, antes de alimentar la red. En cuanto a las imágenes, como documentos de identidad escaneados, la calidad del material y un etiquetado consistente son esenciales para mantener un buen desempeño del modelo.
La integración de estos datos no estructurados con metadatos transaccionales estructurados permite construir un perfil de riesgo más completo. Por ejemplo, un sistema multimodal que combinó análisis de redes sociales con verificaciones tecnológicas alcanzó un F1-score del 96,88%. Sin embargo, esta complejidad también incrementa los requisitos computacionales, lo que puede dificultar la detección en tiempo real a gran escala. A pesar de esto, las CNN ofrecen ventajas sobre arquitecturas como los Transformers, gracias a su menor consumo de memoria y su capacidad de paralelización más eficiente.
Implementar redes neuronales convolucionales (CNN) en el ámbito del comercio electrónico no está libre de retos. Entre los principales destacan la necesidad de escalabilidad, el balance entre precisión y falsas alarmas, y la preparación adecuada de los datos. A continuación, exploramos cómo estas dificultades pueden abordarse con técnicas específicas.
Uno de los mayores desafíos en la detección de fraudes es lograr identificar actividades sospechosas con precisión, sin perjudicar la experiencia de los clientes legítimos. Las CNN modernas emplean estrategias como el aprendizaje multitarea (MTL), que permite al modelo aprender un espacio de representación compartido para distintos tipos de fraudes, desde cargos no autorizados hasta accesos indebidos a cuentas.
Una técnica destacada en este contexto es el Random Loss Weighting (RLW), que ajusta dinámicamente los pesos de las tareas durante el entrenamiento, eliminando la necesidad de calibraciones manuales. Por ejemplo, un modelo CNN equipado con una capa de secuenciación de características logró una precisión del 91% y un recall del 94%, lo que representa un aumento del 26% en comparación con arquitecturas CNN tradicionales.
Además, la integración de herramientas de Inteligencia Artificial Explicable (XAI), como SHAP o LIME, permite a los analistas entender las decisiones del modelo, reduciendo falsas alarmas y aumentando la confianza en el sistema. Por otro lado, los sistemas human-in-the-loop incorporan revisiones manuales para ajustar los umbrales y validar las decisiones del modelo.
La calidad de los datos es clave para el desempeño de cualquier modelo. En el caso de las CNN, el preprocesamiento es crucial. Las variables continuas, como los montos de transacción o los tiempos de permanencia, deben normalizarse logarítmicamente (por ejemplo, ( t_i' = \log(t_i / 1000) )) para estabilizar distribuciones amplias. Por otro lado, las variables categóricas, como los IDs de página o categorías de productos, se manejan mediante codificación de etiquetas. Además, se filtran categorías raras y se asignan valores constantes a datos faltantes para minimizar el ruido.
Para garantizar la uniformidad en las secuencias, se aplican técnicas de padding y truncamiento, asegurando que todas las muestras tengan la misma longitud antes de ser procesadas por la CNN.
Otro desafío importante es el desbalance de clases, que puede llegar a proporciones de hasta 33:1. Para mitigar este problema, se recurre al downsampling aleatorio de datos legítimos, evitando que el modelo se incline hacia la clase mayoritaria.
Un ejemplo notable es el trabajo de investigadores de eBay en noviembre de 2024. Implementaron un modelo Multi-task CNN (MTCNN) utilizando datos de secuencias de comportamiento, aplicando normalización logarítmica y codificación de etiquetas. Este modelo superó a las arquitecturas basadas en Transformers en términos de escalabilidad y detección de comportamientos de riesgo en periodos cortos.
Detectar fraudes en tiempo real en plataformas que procesan millones de transacciones por segundo es un desafío técnico considerable. Las CNN tienen ventajas sobre LSTMs y Transformers gracias a su menor consumo de memoria y su capacidad para paralelizar procesos de manera más eficiente. No obstante, la dependencia de servicios externos, como WHOIS o Alexa, puede introducir retrasos que comprometan la detección inmediata.
| Desafío | Solución basada en CNN | Beneficio |
|---|---|---|
| Alta latencia | Kernels de múltiples rangos / Modelos standalone | Procesamiento en tiempo real a gran escala |
| Modelado de secuencias | Codificación posicional | Captura del comportamiento temporal |
| Ingeniería manual de características | Capa de secuenciación de características | Reducción del sesgo humano |
| Sobreajuste | Aprendizaje multitarea (MTL) | Mejor generalización entre tipos de fraude |
Para evitar retrasos, se recomienda el desarrollo de modelos standalone que utilicen únicamente datos disponibles en el sitio, como HTML, URL o análisis tecnológicos, prescindiendo de APIs externas. En septiembre de 2025, investigadores del Instituto Nacional de Ciberseguridad de España (INCIBE) lograron un F1-score del 96,53% extrayendo 50 características novedosas de HTML, certificados SSL e impacto en redes sociales.
Otra técnica eficaz es el uso de kernels de múltiples rangos, que permite capturar patrones de comportamiento de diferentes longitudes, desde anomalías a corto plazo hasta tendencias más amplias, sin comprometer la velocidad de procesamiento. Combinado con la codificación posicional, este enfoque permite a las CNN interpretar dinámicas complejas del comportamiento del usuario, manteniendo la eficiencia necesaria para entornos de alto volumen.
Las técnicas avanzadas de redes neuronales convolucionales (CNN) están estableciendo un nuevo estándar en la detección de fraudes online. Gracias a su mayor eficiencia computacional en comparación con modelos como LSTMs y Transformers, las CNN se posicionan como la opción ideal para plataformas que procesan millones de transacciones diariamente.
Un aspecto clave es la integración de métodos híbridos y datos multimodales, que permite combinar información estructurada y no estructurada, logrando métricas como un F1-score del 96,9%. Además, la capacidad de estas redes para capturar patrones temporales complejos mediante el uso de kernels múltiples y codificación posicional resulta esencial para mitigar pérdidas que superan los US$362.000 millones. Este procesamiento avanzado de secuencias de comportamiento permite identificar anomalías rápidamente, algo crucial en entornos de alto volumen.
En el ámbito del comercio electrónico, estos avances no solo mejoran la detección de fraudes, sino que también optimizan la operatividad de las plataformas. Por ejemplo, soluciones como Burbuxa integran inteligencia artificial para automatizar procesos de ventas, soporte y marketing en canales como WhatsApp e Instagram. Con sincronización en tiempo real de productos, pedidos e inventarios, estas herramientas muestran cómo la tecnología puede transformar tanto la seguridad como la eficiencia de las tiendas online.
Finalmente, la combinación de CNN con enfoques como el aprendizaje multitarea y las técnicas de inteligencia artificial explicable (XAI) abre la puerta a sistemas más precisos y transparentes. Al incorporar procesamiento multimodal y modelos human-in-the-loop, se establece un marco sólido para enfrentar las tácticas fraudulentas en constante cambio que desafían al comercio electrónico actual.
Las redes neuronales convolucionales (CNN) se destacan en el análisis de transacciones online al identificar patrones complejos mediante filtros que procesan datos como montos, horarios y características del usuario. Cada capa de la red se encarga de detectar patrones específicos, como combinaciones inusuales de eventos o valores que se desvían de lo esperado. Al combinar varias capas, estas redes logran representaciones más avanzadas que revelan relaciones complejas entre los datos.
Los modelos más recientes incorporan kernels multirango, capaces de identificar tanto patrones locales como conexiones más amplias en los datos. Además, al integrar información temporal, estas redes pueden distinguir entre secuencias normales y aquellas con comportamientos repetitivos que suelen estar vinculados al fraude. Entrenadas con grandes volúmenes de datos históricos, las CNN ofrecen una detección rápida y precisa de actividades sospechosas.
Gracias a su habilidad para analizar combinaciones complejas y no lineales de variables, las CNN superan ampliamente los métodos tradicionales, convirtiéndose en una herramienta más eficiente para prevenir el fraude online.
Las redes neuronales convolucionales (CNN) se han convertido en una herramienta clave para detectar fraudes en transacciones online. En términos generales, las CNN superficiales tienen menos capas, lo que permite entrenarlas más rápido. Sin embargo, esta simplicidad puede limitar su capacidad para identificar patrones complejos en los datos. Por el contrario, las CNN profundas, con un mayor número de capas, son capaces de analizar características más detalladas y complejas, lo que las hace más precisas, aunque a costa de un mayor consumo de recursos y tiempo de entrenamiento.
A pesar de estas diferencias, los estudios revisados no han ofrecido explicaciones definitivas sobre cómo estas características afectan directamente la detección de fraudes. Esto indica que la elección entre una CNN superficial o profunda debe ajustarse al caso específico, considerando factores como los recursos disponibles, la naturaleza de los datos y las necesidades particulares de cada plataforma de comercio electrónico.
Las redes neuronales convolucionales (CNN) pueden potenciarse al combinarlas con otros métodos avanzados, logrando una mayor precisión en la detección de fraudes. Por ejemplo, al integrarlas con codificación posicional y aprendizaje multitarea, las CNN no solo identifican patrones locales, sino que también analizan relaciones a largo plazo. Esto resulta especialmente útil para detectar fraudes en plataformas de comercio electrónico, donde la escalabilidad y la precisión son esenciales.
Otra estrategia efectiva es combinar CNN con redes recurrentes (RNN) y autoencoders. En este enfoque, las CNN se encargan de extraer características espaciales de las transacciones, mientras que las RNN analizan patrones temporales y los autoencoders detectan anomalías al comprimir la información. Esta integración no solo reduce los falsos positivos, sino que también permite identificar fraudes emergentes, mejorando la seguridad en tiempo real.
Plataformas como Burbuxa ya implementan estos modelos avanzados en su sistema “Commerce Brain”, ofreciendo una solución más sólida para la detección de fraudes y garantizando una experiencia de compra segura para los usuarios en Argentina.