
Los modelos híbridos de detección de fraude combinan algoritmos avanzados de aprendizaje profundo (como CNN y RNN) con técnicas clásicas (Random Forest, XGBoost) para analizar transacciones en tiempo real. Aunque son efectivos para detectar patrones complejos, enfrentan problemas al escalar, especialmente en plataformas de e-commerce con miles de transacciones por minuto. Los principales desafíos incluyen:
Para superar estos obstáculos, se recomienda optimizar arquitecturas, automatizar ajustes de hiperparámetros y sincronizar datos en tiempo real mediante APIs. Esto asegura un equilibrio entre velocidad, precisión y experiencia del cliente, optimizando la atención al cliente con IA, reduciendo costos y mejorando la detección de fraudes.
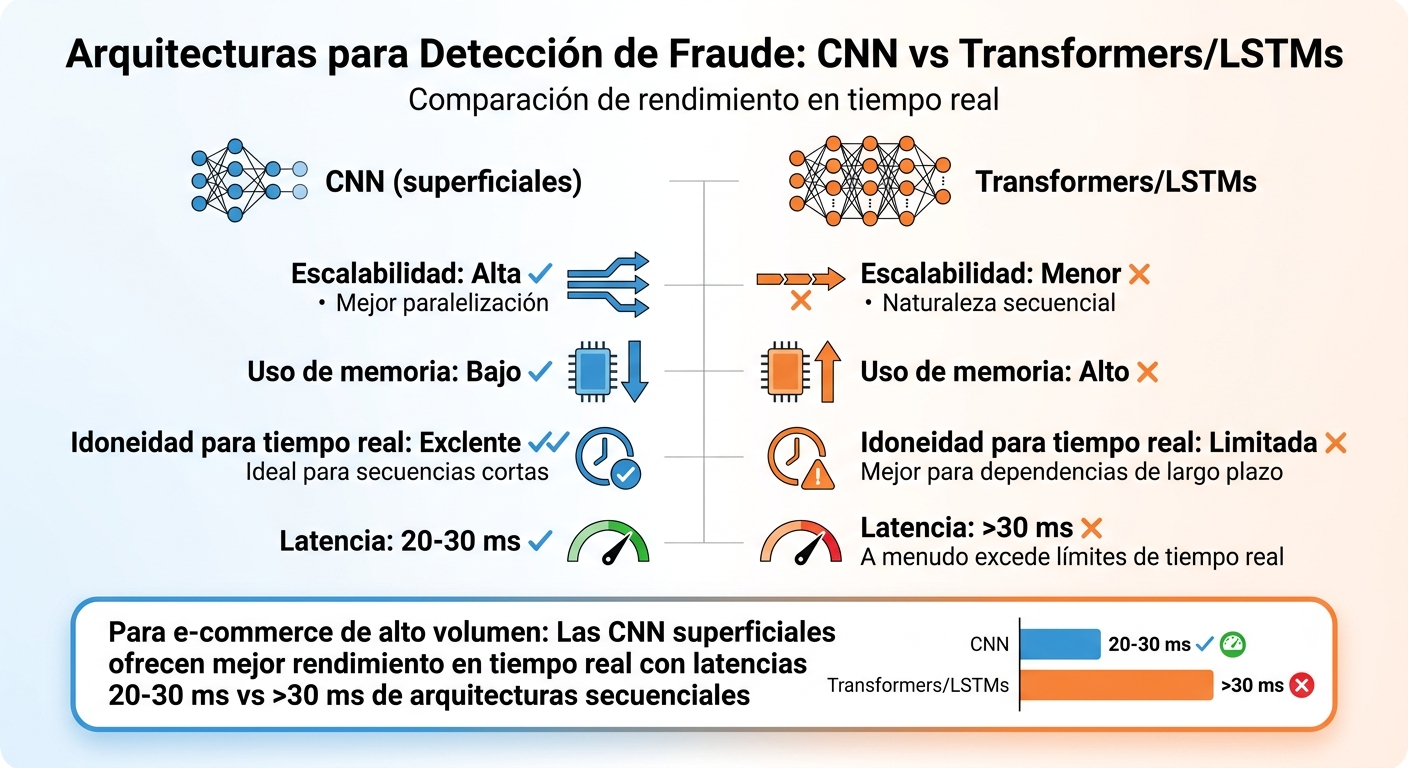
Comparación de arquitecturas CNN vs Transformers/LSTMs para detección de fraude en tiempo real
Identificar las ventajas de los modelos híbridos es solo el comienzo. También es importante analizar los desafíos que afectan su capacidad de escalar sin perder rendimiento. En el caso de plataformas de e-commerce que manejan miles de transacciones simultáneamente, estos problemas se vuelven aún más evidentes. Aquí se describen cuatro obstáculos clave que frenan su crecimiento.
Entrenar modelos híbridos, que combinan redes neuronales profundas con algoritmos tradicionales, requiere una enorme potencia de cómputo. Esto se debe, en parte, a los largos tiempos necesarios para optimizar los hiperparámetros. Cuando los datos de entrenamiento incluyen millones de registros, los costos de infraestructura se disparan. Además, el reentrenamiento frecuente para adaptarse a patrones de fraude emergentes agrava la situación.
Estos elevados costos no solo afectan el entrenamiento inicial. También complican la implementación práctica, especialmente en sistemas que deben procesar datos en tiempo real.
Uno de los mayores retos es mantener una baja latencia mientras se procesan miles de transacciones por minuto. En entornos de alto tráfico, incluso unos pocos milisegundos de retraso pueden tener consecuencias importantes, como estrategias de recuperación de carritos abandonados o clientes insatisfechos. Las diferencias clave entre las arquitecturas más utilizadas se resumen en la siguiente tabla:
| Característica | CNN (superficiales) | Transformers/LSTMs |
|---|---|---|
| Escalabilidad | Alta (mejor paralelización) | Menor (naturaleza secuencial) |
| Uso de memoria | Bajo | Alto |
| Idoneidad para tiempo real | Excelente para secuencias cortas | Mejor para dependencias de largo plazo |
| Latencia | 20–30 ms alcanzables | A menudo excede límites de tiempo real |
Las arquitecturas que incorporan componentes secuenciales, como LSTMs, tienden a tener problemas de paralelización. Esto puede convertirse en un cuello de botella, especialmente durante picos de actividad como eventos de ventas masivas o promociones.
Implementar modelos híbridos en infraestructura distribuida basada en la nube añade un nivel extra de dificultad. La sincronización entre los diferentes componentes del modelo puede generar inconsistencias y aumentar la latencia. Además, es crucial diseñar una arquitectura que asegure una escalabilidad uniforme, minimice las transferencias de datos y mantenga la coherencia en tiempo real. Sin este equilibrio, el sistema puede colapsar bajo una carga inesperada.
El fraude representa solo el 0,172% del total de transacciones, lo que genera un desbalance extremo en los datos de entrenamiento. Este desbalance puede sesgar el modelo hacia clasificar las transacciones como legítimas, aumentando la probabilidad de falsos negativos. En otras palabras, transacciones fraudulentas podrían pasar desapercibidas.
Por otro lado, incluso una tasa baja de falsos positivos puede traducirse en miles de alertas diarias, lo que sobrecarga a los equipos de revisión manual. Este doble problema afecta tanto la eficiencia operativa como la capacidad de detectar fraudes reales.
Estos desafíos destacan la importancia de desarrollar estrategias específicas para mejorar la escalabilidad, las cuales se abordarán en la siguiente sección.
Superar los desafíos de escalabilidad en modelos híbridos de detección de fraude requiere una combinación de técnicas técnicas y estrategias automatizadas. En el competitivo mundo del e-commerce, estas soluciones buscan equilibrar eficiencia y precisión, manejando grandes volúmenes de datos en tiempo real. Aquí repasamos algunas estrategias clave.
La arquitectura del modelo es crucial para manejar la demanda de memoria y garantizar escalabilidad. Por ejemplo, las redes neuronales convolucionales (CNN) superficiales, con solo 1 o 2 capas, consumen menos memoria que las CNN más profundas que tienen 5 o más capas. Esto las convierte en una opción ideal para procesar transacciones cortas en tiempo real sin comprometer el rendimiento.
Reducir la dimensionalidad del conjunto de datos sin perder información relevante es esencial. Una técnica efectiva es el enfoque χ²-RFE, que equilibra precisión y costo computacional. Al seleccionar cuidadosamente las características más útiles, se optimiza el rendimiento del modelo y se mejora su capacidad para detectar fraudes.
El ajuste manual de hiperparámetros puede ser costoso y lento. Automatizar este proceso no solo reduce los costos computacionales, sino que también permite encontrar configuraciones óptimas de manera más eficiente. Esto es especialmente útil cuando el modelo necesita actualizarse para adaptarse a nuevos patrones de fraude. Además, la automatización permite ajustar dinámicamente los recursos según el volumen de transacciones, asegurando que el modelo mantenga un rendimiento constante incluso en momentos de alta demanda.
Para implementar soluciones de escalabilidad en e-commerce, es clave integrarlas en tiempo real con plataformas de comercio electrónico a través de APIs confiables. Esto permite que un modelo híbrido de detección de fraude se conecte directamente con el inventario, los precios y los descuentos de la tienda, evaluando cada transacción mientras se realiza. Así, se identifican anomalías antes de completar la compra, logrando que el modelo funcione eficientemente según la demanda.
Las APIs actúan como un puente entre el modelo de detección y los datos esenciales del negocio. Cada vez que un cliente realiza una compra, el sistema accede inmediatamente a información como productos, órdenes, inventario y descuentos. Este flujo continuo de datos actualizados minimiza los falsos positivos, un problema que puede ser costoso: el 33% de los clientes legítimos no regresa a una tienda si su transacción es rechazada por error.
Un método eficiente para manejar transacciones es el uso de un motor de decisión de tres niveles:
Este sistema equilibra la experiencia del cliente con la protección contra el fraude, permitiendo transacciones fluidas y seguras.
En el blog de Burbuxa exploramos estrategias avanzadas de automatización y agentes para optimizar tiendas online.
Los agentes de IA son un complemento crucial para esta integración en tiempo real. Son capaces de procesar millones de datos en menos de 100 ms, asignando puntajes de riesgo y marcando actividades sospechosas sin intervención humana. Esto no solo mejora la eficiencia, sino que también reduce la necesidad de personal adicional. Mientras los sistemas tradicionales basados en reglas alcanzan tasas de detección del 60-75%, los modelos de machine learning llegan al 92-98%.
Para aumentar la precisión, se recomienda utilizar SDKs de comportamiento en el lado del cliente. Estos recogen datos como movimientos del mouse, patrones de escritura y navegación, que luego se analizan en tiempo real para diferenciar entre bots y humanos. Este enfoque mejora la detección sin perjudicar la experiencia del usuario. Además, es esencial reentrenar los modelos de IA al menos una vez al mes, ya que los modelos estáticos pueden perder entre un 10% y un 15% de precisión en solo 90 días debido a la evolución constante de las tácticas de fraude.
Los modelos híbridos para detectar fraudes enfrentan un desafío importante: garantizar la escalabilidad en un entorno de e-commerce de alto volumen. Con millones de transacciones diarias, la necesidad de procesarlas en milisegundos y la complejidad de los modelos de deep learning, las empresas deben contar con infraestructuras sólidas y estrategias de optimización constante. Sin estas herramientas, se verían obligadas a depender de revisiones manuales, una solución inviable a gran escala.
Adoptar arquitecturas impulsadas por GPU y automatizar el ajuste de hiperparámetros son pasos clave para mantener la eficiencia. Un ejemplo claro es el caso de American Express en 2026. Al implementar deep learning optimizado con NVIDIA TensorRT y Triton Inference Server, lograron manejar más de US$1,2 billones anuales, mejorando la precisión en un 6% y reduciendo la latencia a milisegundos. Este enfoque permitió procesar datos hasta 5 veces más rápido y reducir costos operativos hasta 4 veces en comparación con sistemas basados en CPU. Estos resultados demuestran que invertir en computación acelerada no solo mejora el rendimiento, sino que también reduce gastos.
Para las empresas de e-commerce, la escalabilidad no es solo un objetivo, sino una estrategia esencial. Los atacantes, utilizando tecnologías avanzadas como la IA generativa, están sofisticando sus métodos, lo que obliga a las empresas a actualizar sus sistemas de defensa al mismo ritmo. Sincronizarse en tiempo real con las plataformas de comercio y emplear agentes de IA que tomen decisiones en milisegundos permite equilibrar la seguridad con una experiencia de compra sin interrupciones.
Además, reentrenar los modelos regularmente es vital para adaptarse a las tácticas cambiantes de los atacantes. Esto resalta la importancia de implementar pipelines automatizados que mantengan los sistemas actualizados de manera continua. Una escalabilidad bien diseñada no solo protege los ingresos, sino que también refuerza la confianza del cliente al reducir los falsos positivos que podrían alejar a compradores legítimos.
Si querés manejar picos de ventas sin problemas, es clave elegir una arquitectura que combine velocidad, escalabilidad y eficiencia. Una buena opción son los modelos híbridos, que mezclan inteligencia artificial con análisis humano. Este enfoque permite detectar fraudes en tiempo real con un nivel de precisión muy alto.
Además, es importante trabajar con una infraestructura desacoplada, que facilite la flexibilidad y el manejo de grandes volúmenes de datos. Incorporar técnicas avanzadas como las redes neuronales convolucionales (CNN) y la ingeniería de características temporales puede marcar la diferencia. Estas herramientas ayudan a identificar patrones complejos de forma rápida, disminuyen los falsos positivos y optimizan el uso de recursos, lo que es fundamental en momentos de alta demanda.
Trabajar con datos desbalanceados puede ser un desafío, pero hay estrategias que ayudan a mejorar la precisión de los modelos. Una opción es implementar sobre-muestreo de la clase minoritaria, lo que implica aumentar artificialmente el número de ejemplos de esa clase. Por otro lado, el submuestreo de la clase mayoritaria reduce la cantidad de datos de la clase dominante para equilibrar el conjunto.
Además, es fundamental usar métricas como precisión, recall o F1-score en lugar de depender únicamente de la exactitud, ya que estas métricas ofrecen una visión más completa del rendimiento del modelo en escenarios desbalanceados.
Otro punto clave es la selección de características relevantes, que ayuda a enfocarse en las variables que realmente aportan valor al modelo. Ajustar los umbrales de decisión también puede marcar una gran diferencia, especialmente cuando se trabaja con modelos híbridos que combinan inteligencia artificial y análisis humano. Esto permite un enfoque más afinado y personalizado para minimizar errores.
La frecuencia con la que se debe reentrenar un modelo híbrido de detección de fraude depende de varios factores, como los cambios en los patrones de fraude y la cantidad de datos nuevos que se generan. En general, es aconsejable realizar este proceso de forma periódica, ya sea semanal o mensualmente. Esto asegura que el modelo mantenga su precisión y pueda adaptarse a las tendencias emergentes.
Para mantener el modelo actualizado frente a nuevas amenazas, es posible automatizar el ajuste de hiperparámetros utilizando métodos como:
Estas técnicas permiten ajustar el modelo de manera eficiente y mejorar su rendimiento frente a posibles amenazas.