
La reducción de dimensionalidad es clave para mejorar los sistemas de recomendación en plataformas de e-commerce. Permite procesar grandes volúmenes de datos de usuarios y productos, optimizando el rendimiento y reduciendo costos de almacenamiento. Técnicas como PCA, SVD, t-SNE, UMAP y cuantización ayudan a simplificar matrices dispersas, identificar patrones ocultos y comprimir datos sin perder precisión.
Estas técnicas son esenciales para manejar la dispersión de datos y generar recomendaciones personalizadas en tiempo real, maximizando la experiencia del cliente y los ingresos en e-commerce.
El PCA simplifica matrices de alta dimensión al reducirlas a un espacio latente más compacto, conservando los patrones más importantes. Este proceso permite transformar millones de interacciones dispersas en una estructura más sencilla de manejar. Al realizarse de manera offline, garantiza que las recomendaciones puedan generarse en tiempo real sin sobrecargar el sistema.
Este enfoque posiciona tanto a usuarios como a productos en un espacio de características latentes compartido. Esto facilita la predicción de preferencias incluso cuando no hay interacciones directas entre ellos. Por ejemplo, si dos usuarios nunca calificaron los mismos productos, pero comparten factores latentes similares, el PCA puede identificar esta relación y sugerir productos relevantes.
Entre 2006 y 2009, el Netflix Prize se convirtió en un experimento clave para probar algoritmos de reducción de dimensionalidad. Con un dataset que contenía más de 100 millones de calificaciones, se emplearon técnicas como PCA y SVD incremental para identificar factores latentes que explicaran las valoraciones. Un ejemplo destacado es el algoritmo Eigentaste, aplicado al dataset Jester con 1,7 millones de calificaciones. Este algoritmo mostró cómo el PCA puede agrupar usuarios con preferencias similares mediante clustering recursivo.
Ventajas:
Limitaciones:
Este análisis abre el camino para comparar PCA con otras técnicas de reducción, como SVD y métodos no lineales, que se explorarán más adelante.
La descomposición en valores singulares (SVD) divide una matriz dispersa de interacciones entre usuarios y productos en tres matrices más pequeñas. Este proceso posiciona a usuarios y productos en un espacio latente, donde cada dimensión refleja características implícitas, como preferencias por un estilo o categoría. Esto no solo reduce el ruido en los datos, sino que también resalta relaciones clave.
Al enfocarse únicamente en los valores singulares más relevantes, SVD logra eliminar información irrelevante y optimizar las relaciones esenciales entre datos. Esto permite un procesamiento más rápido y eficiente. A diferencia de los métodos tradicionales de filtrado colaborativo basados en vecindad, que requieren un espacio de $O(m^2)$, los sistemas basados en SVD solo necesitan $O(m+n)$, lo que los hace mucho más prácticos para plataformas a gran escala. Este enfoque es especialmente útil para aplicaciones en e-commerce, donde la escalabilidad es crucial.
En el ámbito del e-commerce, SVD ha demostrado ser una herramienta poderosa. Por ejemplo, en diciembre de 2025, un estudio publicado en el Journal of Applied Informatics and Computing aplicó un modelo de filtrado colaborativo basado en SVD a un dataset de e-commerce de gran escala con nueve tablas transaccionales interconectadas. Los resultados fueron impresionantes: el modelo obtuvo un RMSE de 1,25 y un MAE de 0,98, superando los estándares de la industria, que eran de 1,31 y 1,04 respectivamente.
"El modelo SVD supera eficazmente el desafío de escasez inherente a los datos transaccionales de e-commerce a gran escala, proporcionando capacidades de predicción robustas que superan los benchmarks establecidos de la industria." - Galih Mahalisa, Investigador, Universitas Islam Kalimantan MAB
Otro ejemplo relevante ocurrió en septiembre de 2022, cuando investigadores del Institut Teknologi Bandung aplicaron un modelo SVD optimizado al dataset ModCloth Amazon. Ajustando los hiperparámetros, lograron reducir el RMSE de 1,055586 a 1,041784, demostrando que SVD puede ofrecer una mayor precisión frente a otros algoritmos de factorización.
Aunque SVD y PCA son técnicas de reducción de dimensionalidad, tienen diferencias clave que las hacen aptas para diferentes escenarios. SVD es particularmente eficaz para trabajar con matrices dispersas y no cuadradas, comunes en el filtrado colaborativo. Por otro lado, PCA generalmente requiere matrices densas y se enfoca en maximizar la varianza, lo que lo hace menos eficiente en contextos con datos faltantes.
Estudios experimentales utilizando el dataset MovieLens han demostrado que SVD-CF supera a PCA-CF en precisión para tareas de recomendación. Mientras que PCA se utiliza principalmente para simplificar conjuntos de características, SVD se centra en predecir interacciones faltantes entre usuarios y productos, lo que lo convierte en una herramienta clave para generar recomendaciones personalizadas en tiempo real.
Después de analizar PCA y SVD, es hora de adentrarse en métodos no lineales que capturan relaciones más complejas en los datos.
t-SNE es una técnica que convierte las distancias en alta dimensión en probabilidades condicionales, enfocándose en preservar las relaciones locales. Esto lo hace ideal para identificar pequeños grupos de productos o usuarios similares en datasets de recomendación. Por ejemplo, es muy útil para visualizar embeddings generados con herramientas como doc2vec o BERT, ayudando a detectar patrones, clusters o incluso anomalías en los datos.
Sin embargo, t-SNE tiene una complejidad computacional elevada de $O(N^2)$, lo que lo vuelve poco práctico para datasets grandes. Afortunadamente, la variante Barnes-Hut reduce esta complejidad a $O(N \log N)$, haciéndolo más manejable.
"t-SNE preserva similitudes locales y es estándar para... visualización de word-embeddings, pero su sensibilidad a la perplejidad y la distorsión de la estructura global requieren precaución." - PeerJ Computer Science
UMAP (Uniform Manifold Approximation and Projection) se basa en principios de geometría riemanniana y topología algebraica, logrando un equilibrio entre la preservación de estructuras locales y globales. Su complejidad de $O(N \log N)$ lo hace considerablemente más rápido que el t-SNE estándar, lo que lo convierte en una opción más adecuada para grandes volúmenes de datos.
Una de sus ventajas más destacadas es Metric UMAP, que permite personalizar las métricas de distancia, como Cosine o Jaccard, algo muy relevante en sistemas de recomendación. Esto le da una flexibilidad que lo diferencia de t-SNE.
"UMAP aprovecha gráficos topológicos difusos para equilibrar la fidelidad local y global con menor tiempo de ejecución." - Healy & McInnes
Esta flexibilidad y rapidez permiten que UMAP se adapte mejor a datasets complejos, contrastando con el enfoque más localizado de t-SNE.
Ambas herramientas tienen fortalezas específicas según el caso de uso. Mientras que t-SNE es excelente para explorar clusters pequeños y relaciones locales, UMAP destaca al representar tanto agrupaciones locales como conexiones más amplias entre categorías. Sin embargo, es importante considerar que una reducción extrema (como pasar de 20.000 dimensiones a solo 2) puede conservar menos del 0,1% de la varianza, lo que podría afectar la interpretación.
| Característica | t-SNE | UMAP |
|---|---|---|
| Objetivo principal | Preserva vecindarios locales | Preserva estructura local y global |
| Complejidad | $O(N^2)$ (estándar) o $O(N \log N)$ (Barnes-Hut) | $O(N \log N)$ |
| Escalabilidad | Baja a moderada | Alta |
| Métricas de distancia | Euclidiana | Soporta Cosine, Jaccard, etc. |
| Estructura global | A menudo distorsionada | Generalmente preservada |
En sistemas en producción que trabajan con datos en tiempo real, UMAP ofrece variantes paramétricas que usan redes neuronales para aprender un mapeo explícito. Esto permite incorporar nuevos usuarios o productos con una complejidad de $O(N)$ durante la inferencia, sin necesidad de reentrenar todo el modelo.
Un enfoque híbrido muy eficiente es combinar PCA y UMAP: primero, PCA reduce el ruido y decorrelaciona los datos, y luego UMAP realiza un refinamiento no lineal para obtener representaciones más claras y útiles.
Después de aplicar métodos de reducción de dimensionalidad, el siguiente paso es optimizar cómo se almacenan y consultan los embeddings generados. En sistemas industriales, estos embeddings pueden ocupar desde cientos de GB hasta 10 TB, lo que plantea desafíos importantes en términos de almacenamiento y eficiencia.
La cuantización binaria convierte los pesos de embeddings de precisión completa (normalmente de 32 bits) en códigos binarios de 1 bit. Esto permite reducir el uso de memoria hasta 32 veces y acelera las búsquedas de similitud mediante el uso de la distancia de Hamming. Sin embargo, esta compresión extrema puede disminuir la precisión del modelo en un 0,1%, lo que podría impactar en los ingresos. Para minimizar estos riesgos, se emplean técnicas como el Straight-Through Estimator, que optimizan el proceso de cuantización de extremo a extremo.
Aunque la cuantización binaria logra la mayor compresión, la cuantización de producto ofrece un mejor equilibrio entre compresión y precisión, especialmente en sistemas de gran escala. Este método divide el espacio en D subespacios, asignando a cada uno K centroides y representando los productos mediante los índices de sus centroides más cercanos.
Un ejemplo destacado es el de los Multi-Granular Quantized Embeddings (MGQE). En abril de 2020, investigadores de Google y UC San Diego aplicaron MGQE al dataset de Google Play Store, logrando igualar el rendimiento de un modelo de precisión completa utilizando solo el 20% del tamaño original. Más recientemente, en agosto de 2023, el equipo de Kuaishou implementó el framework SHARK en sus plataformas de video corto y comercio electrónico, logrando reducir el almacenamiento de embeddings en un 70% y aumentar las consultas por segundo en un 30%.
La cuantización no solo es una técnica de compresión, sino también una estrategia de optimización. Al reducir significativamente el tamaño de las tablas de embeddings, mejora el uso de la memoria caché y disminuye la latencia, lo cual es crítico en e-commerce, donde cada milisegundo puede marcar la diferencia.
Mientras que la binarización maximiza la velocidad, la cuantización de 8 bits ofrece un equilibrio con pérdidas mínimas en comparación con los modelos de 32 bits. Además, en catálogos con una distribución de cola larga, los esquemas multi-granulares como MGQE ayudan a evitar el sobreajuste en productos menos frecuentes, manteniendo la precisión en los más populares. Estas mejoras en compresión y consulta permiten que sistemas como los de Burbuxa ofrezcan recomendaciones en tiempo real, optimizando la experiencia en plataformas de e-commerce.
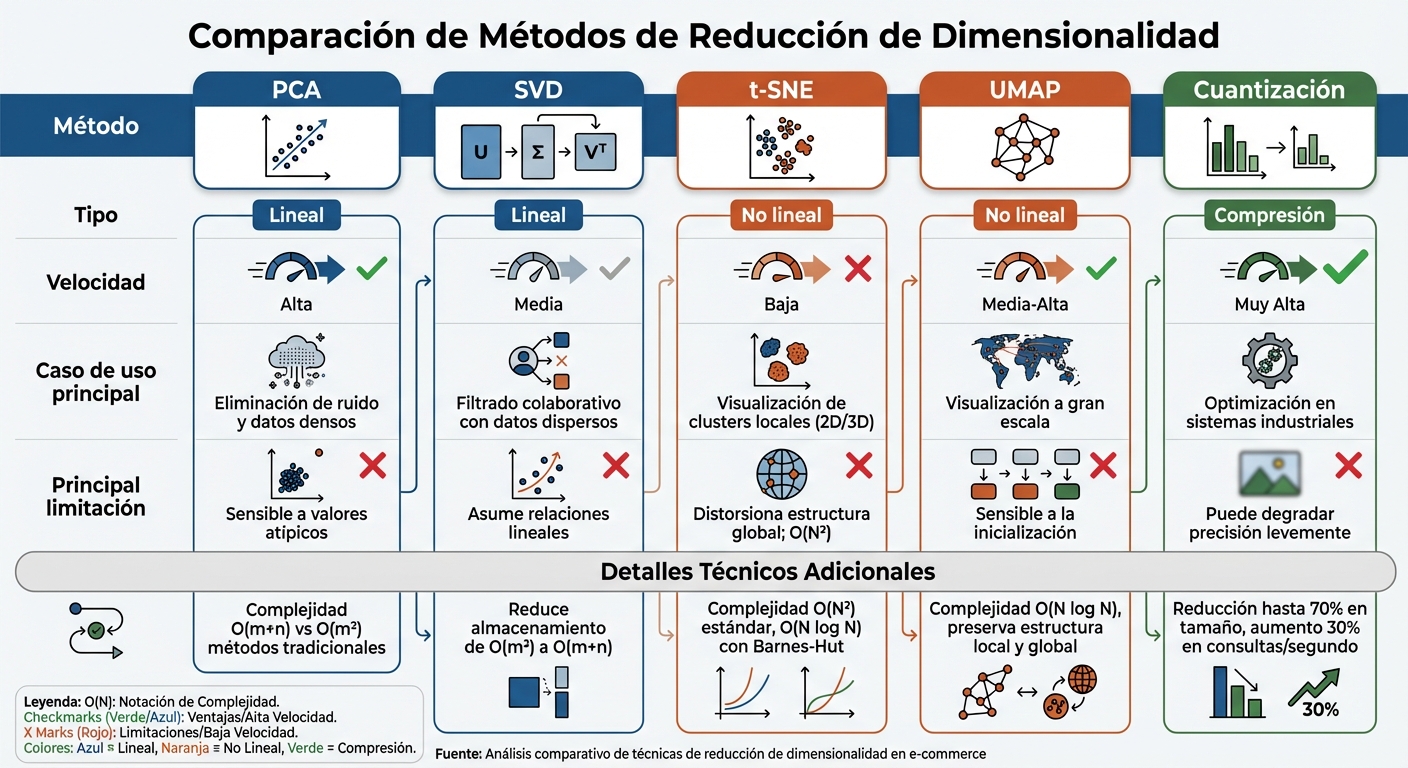
Comparación de métodos de reducción de dimensionalidad para sistemas de recomendación en e-commerce
Esta sección sintetiza y compara las técnicas previamente descritas, ayudando a identificar cuál es la más adecuada según el contexto del e-commerce.
Cada método tiene características que lo hacen más o menos útil según la situación. Por ejemplo, PCA es excelente para eliminar ruido, aunque no detecta relaciones no lineales y es susceptible a valores atípicos. Por otro lado, SVD es ideal para trabajar con datos dispersos en filtrado colaborativo, reduciendo significativamente los requisitos de almacenamiento, pasando de $O(m^2)$ a $O(m+n)$. t-SNE y UMAP son mejores para preservar estructuras complejas, pero difieren en escalabilidad: t-SNE tiene una complejidad de $O(N^2)$, mientras que UMAP es más eficiente con $O(N \log N)$, manteniendo tanto estructuras locales como globales. Finalmente, la cuantización es perfecta para comprimir embeddings, logrando velocidades muy altas con una pérdida mínima de precisión.
| Método | Tipo | Velocidad | Caso de uso principal | Principal limitación |
|---|---|---|---|---|
| PCA | Lineal | Alta | Eliminación de ruido y datos densos | Sensible a valores atípicos |
| SVD | Lineal | Media | Filtrado colaborativo con datos dispersos | Asume relaciones lineales |
| t-SNE | No lineal | Baja | Visualización de clusters locales (2D/3D) | Distorsiona la estructura global; complejidad $O(N^2)$ |
| UMAP | No lineal | Media-Alta | Visualización a gran escala | Sensible a la inicialización |
| Cuantización | Compresión | Muy Alta | Optimización en sistemas industriales | Puede degradar la precisión levemente |
Con base en la comparación anterior, estas son las recomendaciones según las necesidades del sistema y las características del conjunto de datos.
SVD es la mejor opción para sistemas de recomendación que trabajan con matrices dispersas de usuarios y productos en e-commerce. Como explica George Karypis, profesor de informática:
SVD has the potential to meet many of the challenges of recommender systems, under certain conditions.
Para conjuntos de datos masivos, SVD no solo mantiene la calidad de las recomendaciones, sino que también reduce drásticamente los requisitos de almacenamiento.
PCA es ideal como paso inicial para eliminar ruido, especialmente cuando se trabaja con datos densos o cuando la velocidad es prioritaria. Por otro lado, UMAP supera a t-SNE en la exploración de relaciones dentro de catálogos extensos, ya que equilibra de manera más efectiva la conservación de estructuras locales y globales. Por último, la cuantización es clave en entornos de producción donde las tablas de embeddings pueden alcanzar cientos de GB, ayudando a reducir latencia y costos de memoria sin comprometer demasiado la precisión.
Elegir el método correcto es crucial para mejorar las recomendaciones y optimizar el rendimiento en plataformas de e-commerce.
Burbuxa aplica metodologías avanzadas para mejorar sus recomendaciones en tiempo real. Su plataforma utiliza técnicas de reducción de dimensionalidad, como PCA y SVD, que transforman datos de productos, usuarios y conversaciones en representaciones más compactas. Esto ayuda a identificar patrones clave y a eliminar información irrelevante.
El "Commerce Brain" de Burbuxa procesa datos de compras, búsquedas, conversaciones en WhatsApp e Instagram, y otros factores demográficos para ofrecer experiencias personalizadas. A través de factorización de matrices, el sistema crea una matriz usuario-producto que, al descomponerse con SVD, predice preferencias y genera recomendaciones Top‑N en tiempo real. Esto permite sugerir productos complementarios, rutinas personalizadas y bundles relevantes durante las interacciones con los clientes.
Además de personalizar recomendaciones, Burbuxa automatiza el procesamiento de datos para garantizar un rendimiento eficiente. Utiliza SVD truncado y PCA para reducir las dimensiones de características visuales y matrices usuario-producto, disminuyendo costos computacionales y uso de memoria sin comprometer la precisión. También aplica compresión de embeddings con precisión reducida en dimensiones mixtas para manejar grandes volúmenes de datos industriales. Este procesamiento continuo permite optimizar recomendaciones para campañas como recuperación de carritos, mensajes de cross‑sell y broadcasts segmentados en WhatsApp.
Las recomendaciones optimizadas de Burbuxa influyen directamente en métricas clave. La plataforma implementa motores como "Los clientes también compraron" o "Frecuentemente comprados juntos" en las etapas de checkout, impulsando estrategias de upsell y cross‑sell que aumentan el valor promedio de pedido (AOV) y los ingresos totales. Además, reporta un aumento del 32% en la recuperación de carritos y un engagement 3,5 veces mayor en comparación con métodos tradicionales. La reducción de dimensionalidad también permite respuestas más rápidas durante las interacciones con los clientes, mejorando la experiencia general.
La reducción de dimensionalidad está transformando los sistemas de recomendación en el e-commerce. En el corazón de estas soluciones se encuentra la factorización de matrices, que mejora la precisión, la diversidad y la novedad de las sugerencias. Estas técnicas no solo optimizan el almacenamiento, sino que también resuelven problemas críticos como la dispersión de datos - donde los usuarios interactúan con menos del 1% del catálogo - y el problema de sinonimia, al identificar relaciones ocultas entre productos similares. Por otro lado, métodos no lineales como t-SNE y UMAP permiten explorar visualmente patrones en catálogos extensos, mientras que la cuantización reduce de manera drástica los costos de memoria en entornos industriales.
Con estas técnicas ya consolidadas, el panorama futuro presenta nuevos retos y oportunidades para perfeccionar la personalización. Los modelos de factores latentes no lineales y neuronales están ganando terreno, integrando datos implícitos, redes de confianza social y contenido multimedia. Además, la evaluación de sistemas está evolucionando más allá de la precisión, incluyendo métricas como diversidad, novedad y explicabilidad. También se espera que las estrategias híbridas permitan actualizaciones en tiempo real para adaptarse a los cambios en el comportamiento de los usuarios. En paralelo, la compresión de embeddings seguirá desarrollándose mediante enfoques de baja precisión y dimensiones mixtas, una respuesta necesaria ante la creciente cantidad de datos.
Estas innovaciones tecnológicas se traducen en acciones concretas para optimizar las recomendaciones en tiempo real. Las marcas pueden implementar SVD para manejar grandes volúmenes de datos y superar las limitaciones de los métodos basados en vecinos. Plataformas como Burbuxa ya están aplicando estas técnicas avanzadas, procesando datos de conversaciones en WhatsApp e Instagram junto con historiales de compra, generando sugerencias personalizadas en cuestión de milisegundos. La elección del modelo dependerá de los objetivos específicos: si necesitás interpretar el significado semántico o realizar recomendaciones grupales, un enfoque más complejo basado en la factorización de matrices es ideal; si la prioridad es velocidad y eficiencia, las técnicas de cuantización son la mejor opción. Combinando el procesamiento offline de descomposiciones matriciales con respuestas online ultrarrápidas, las marcas pueden escalar sin comprometer la experiencia del cliente.
La elección entre PCA (Análisis de Componentes Principales) y SVD (Descomposición en Valores Singulares) depende del propósito del sistema de recomendación y del tipo de datos con los que se trabaja.
Si el objetivo es simplificar datos para identificar patrones o reducir redundancia en conjuntos con muchas variables, PCA es una excelente opción. Esta técnica transforma las variables originales en un conjunto más pequeño de componentes principales que capturan la mayor parte de la variabilidad de los datos, lo que facilita su análisis e interpretación.
Por otro lado, SVD resulta más práctico cuando se manejan matrices grandes que contienen datos de usuarios y productos. Es especialmente útil en filtrado colaborativo, ya que permite reducir la complejidad de las matrices y mejora la eficiencia al identificar similitudes en un espacio de menor dimensión.
En pocas palabras, PCA es ideal para análisis interpretativos, mientras que SVD es más adecuado para optimizar cálculos en sistemas de recomendación con grandes volúmenes de datos.
UMAP (Uniform Manifold Approximation and Projection) ofrece varios beneficios cuando se compara con t-SNE, especialmente al trabajar con grandes volúmenes de datos. Una de sus principales fortalezas es su velocidad de ejecución, lo que lo convierte en una opción ideal para analizar conjuntos de datos masivos sin consumir tanto tiempo.
Otro punto fuerte de UMAP es su capacidad para preservar mejor la estructura global de los datos. Esto puede ser clave en aplicaciones donde entender la relación general entre los datos es tan importante como observar patrones locales.
Además, UMAP no impone límites en la dimensión del embedding resultante. Esto lo hace mucho más versátil para tareas de reducción de dimensionalidad, tanto en aprendizaje automático como en visualización de datos. Estas características lo posicionan como una herramienta eficiente y adaptable para análisis a gran escala.
La cuantización influye directamente en la precisión de los sistemas de recomendación, ya que comprime los vectores de embeddings. Este proceso puede generar errores o pérdida de información, lo que dificulta que el modelo identifique con claridad las preferencias de los usuarios o las características de los productos. Como resultado, la calidad de las recomendaciones puede verse afectada.
Sin embargo, la cuantización también trae ventajas importantes: mejora la eficiencia computacional y reduce el tamaño de los modelos. Esto es especialmente útil en aplicaciones a gran escala o en entornos con recursos limitados. A pesar de sus beneficios, esta compresión puede tener un impacto mayor en las características menos frecuentes, ya que no siempre logra capturar todos los detalles presentes en los datos originales.
En esencia, la cuantización requiere encontrar un punto medio entre precisión y eficiencia. Una mayor compresión puede implicar una ligera pérdida de exactitud, pero a cambio ofrece ventajas en términos de escalabilidad y rapidez.