
¿Por qué es importante la selección de características en la detección de fraude?
Porque mejora la precisión de los modelos al enfocarse solo en las variables relevantes, reduciendo ruido y sobreajuste. Esto acelera el entrenamiento y permite identificar patrones en datos desbalanceados, como en transacciones fraudulentas (solo el 0,17 % de los datos).
Conclusión: Seleccionar características relevantes no solo optimiza el rendimiento de los modelos, sino que también es clave para manejar grandes volúmenes de datos y detectar fraudes con mayor precisión.
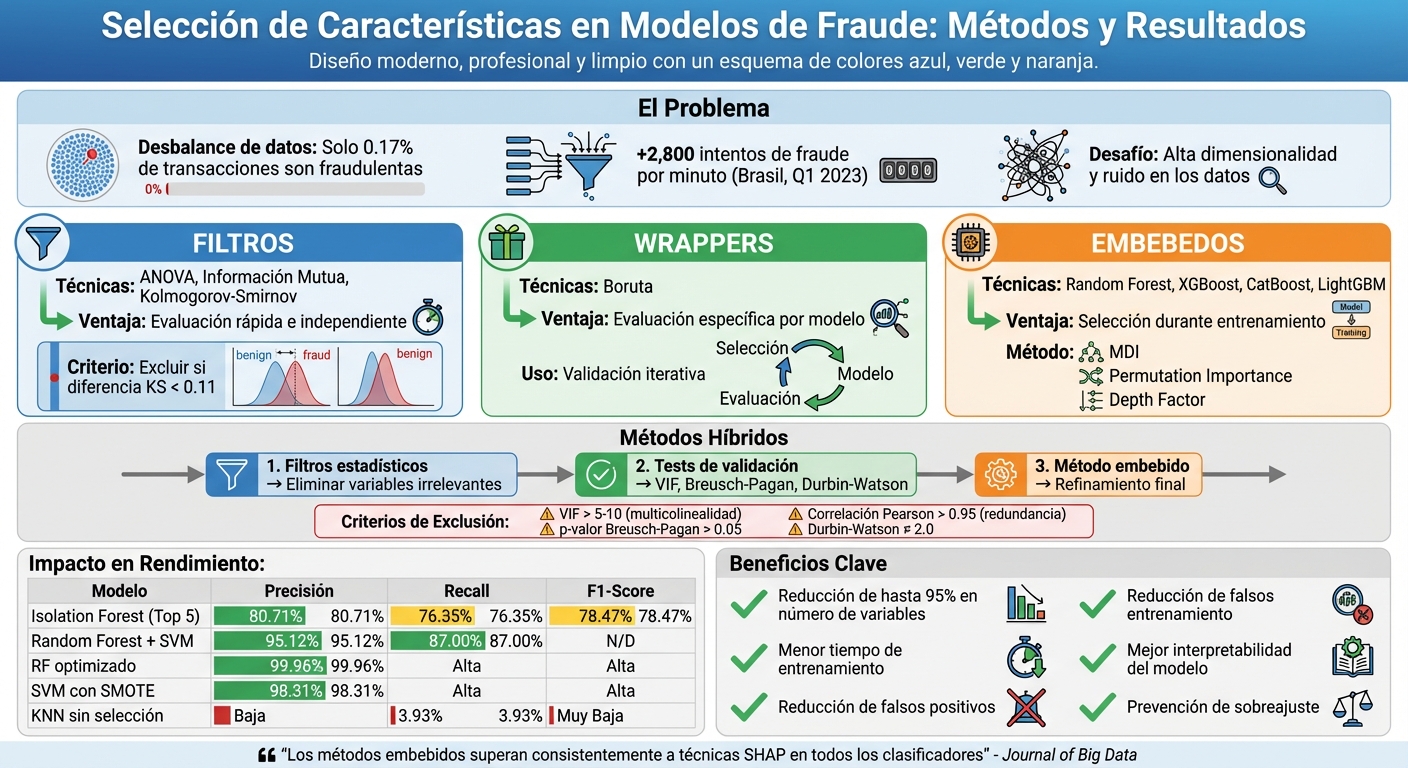
Comparación de Métodos de Selección de Características para Detección de Fraude
Los métodos embebidos combinan la selección de características directamente con el entrenamiento del modelo. Esto significa que el algoritmo identifica, durante el proceso, cuáles variables son más relevantes para mejorar su precisión. A diferencia de los métodos de filtro, que evalúan cada característica de manera independiente, los métodos embebidos aplican penalizaciones como ℓ1 o elastic-net para eliminar variables que no aportan valor. Este enfoque no solo ayuda a reducir el riesgo de sobreajuste, sino que también mejora el rendimiento en tareas como la clasificación binaria, especialmente en conjuntos de datos con elementos estocásticos, como los relacionados con transacciones financieras. Esto establece una base sólida para usar técnicas como MDI, que se explican a continuación.
Random Forest utiliza el método MDI (Mean Decrease Impurity) para determinar qué características son más útiles para segmentar los datos. Sin embargo, este enfoque tiende a sobrevalorar variables con alta cardinalidad. Para mitigar este sesgo, es recomendable complementar MDI con Permutation Importance, calculada sobre un conjunto de prueba independiente. Además, ajustar el parámetro min_samples_leaf entre 5 y 10 ayuda a evitar que el modelo se ajuste al ruido generado por variables de alta cardinalidad.
Un avance reciente en este campo es el uso del Depth Factor (FP), que ha demostrado ser una medida más confiable para evaluar la importancia real de las características en configuraciones de Random Forest. Este enfoque supera a métodos tradicionales como Gini Importance y Error-based Importance.
En el ámbito de los modelos basados en árboles, CatBoost y LightGBM ofrecen ventajas significativas, especialmente en la detección de fraude. Estos algoritmos son particularmente efectivos para manejar el desbalance extremo de clases, una característica común en este tipo de problemas, donde las transacciones fraudulentas pueden representar apenas el 0,17 % del total de datos. Además, son resistentes al ruido y a los valores atípicos, lo cual es esencial para analizar registros financieros.
Mientras que algunos enfoques pueden generar un exceso de falsos positivos, un Random Forest bien ajustado logra un equilibrio entre precisión y reducción de bloqueos innecesarios. Al evaluar estos modelos, es crucial priorizar métricas como Recall, F1-Score y AUC, ya que la exactitud general puede ser engañosa en contextos con clases desbalanceadas. Estos métodos son especialmente valiosos en entornos como el e-commerce, donde detectar el fraude con precisión es fundamental.
Los métodos híbridos son una estrategia en dos etapas que combina filtros estadísticos con técnicas embebidas para seleccionar variables relevantes en modelos de fraude. Primero, se aplican pruebas estadísticas para eliminar variables irrelevantes; luego, se utiliza un método embebido para afinar aún más la selección. Este enfoque reduce la redundancia, mejora la claridad del modelo y ayuda a evitar el sobreajuste, algo crucial cuando solo el 0,17% de las transacciones son fraudulentas. Además, esta metodología es particularmente útil en conjuntos de datos con alta dimensionalidad, complementando los métodos embebidos con una validación adicional.
La base de este enfoque radica en la solidez estadística. Por ejemplo, el test de Breusch-Pagan detecta heterocedasticidad (es decir, varianza no constante en los residuos), mientras que el test de Durbin-Watson evalúa la autocorrelación. Un valor cercano a 2,0 en este último indica que las variables seleccionadas no presentan correlaciones temporales consecutivas, aumentando así la confiabilidad del modelo.
Un framework híbrido típico comienza con el test de Kolmogorov-Smirnov (KS) para medir la capacidad de una variable de separar transacciones fraudulentas de las legítimas. Las variables con una diferencia en el D-test menor al 11% se descartan por su bajo poder predictivo. Como señala Carmen Scartezini:
"Cuanto mayor sea la diferencia entre las distribuciones, mejor podrá el modelo identificar estas diferencias para hacer predicciones".
Para abordar la multicolinealidad, se emplean herramientas como el Factor de Inflación de Varianza (VIF) y matrices de correlación. Las variables con un VIF superior a 5 o 10 se eliminan para evitar distorsiones en los coeficientes del modelo. En la etapa embebida, el ajuste del parámetro class_weight en la Regresión Logística permite priorizar la clase minoritaria (fraude), mejorando notablemente el recall sin necesidad de recurrir a técnicas de oversampling como SMOTE.
| Filtro Estadístico | Propósito en Selección Híbrida | Criterio de Decisión |
|---|---|---|
| Breusch-Pagan | Detectar heterocedasticidad | Excluir si p-valor > 0,05 |
| Durbin-Watson | Verificar autocorrelación | Valor objetivo cercano a 2,0 |
| VIF / Matriz de correlación | Identificar multicolinealidad | Excluir si VIF > 5 o 10 |
| Kolmogorov-Smirnov | Medir separabilidad de clases | Excluir si diferencia < 0,11 |
Este enfoque híbrido no solo refuerza la solidez de los modelos, sino que también se adapta a escenarios de alto volumen transaccional. Por ejemplo, en Brasil, durante el primer trimestre de 2023, se registraron más de 2.800 intentos de fraude financiero por minuto en canales electrónicos. En estos contextos, los métodos híbridos ofrecen una solución eficiente para construir modelos confiables y efectivos.
La selección de características tiene un impacto directo en las métricas clave de los modelos de detección de fraude. Según los datos, acelera el tiempo de entrenamiento y mejora la capacidad del modelo para identificar fraudes, logrando una detección más precisa y efectiva.
| Configuración del Modelo | Precisión | Recall | F1-Score | AUPRC |
|---|---|---|---|---|
| Isolation Forest (Top 5 características) | 80,71% | 76,35% | 78,47% | 0,7592 |
| Random Forest + SVM (con selección) | 95,12% (Exactitud) | 87,00% (Sensibilidad) | N/D | N/D |
| Regresión Logística (sin balanceo) | Alta | Muy Baja | Baja | Baja |
| Regresión Logística (con ajuste class_weight) | Balanceada | Alta | Balanceada | Alta |
Por ejemplo, un modelo Isolation Forest que utilizó solo las 5 variables más relevantes ($V_{14}, V_4, V_{17}, V_{12}, V_{11}$) alcanzó una precisión del 80,71% y un recall del 76,35%, con un F1-score de 78,47%. En comparación, modelos sin selección de características pueden tener un recall críticamente bajo, como el 3,93% reportado en algunos modelos KNN, lo que implica que se pasan por alto la mayoría de los fraudes.
Estos resultados subrayan la importancia de aplicar técnicas de selección de características antes de entrenar modelos de detección de fraude.
La selección de características no solo reduce el sobreajuste, sino que también mejora significativamente el recall del modelo, permitiendo entrenar sistemas más rápidos sin comprometer la precisión. Según el Journal of Big Data:
"Los resultados experimentales y las pruebas estadísticas indican que los métodos de selección de características basados en valores de importancia superan a aquellos basados en valores SHAP en todos los clasificadores y tamaños de subconjuntos de características".
Los métodos embebidos, como Random Forest, XGBoost y CatBoost, destacan por generar rankings durante el entrenamiento, lo que elimina la necesidad de cálculos adicionales complejos. Esto no solo mejora el rendimiento, sino que también reduce el tiempo de procesamiento. En pruebas realizadas con subconjuntos de 3, 5, 7, 10 y 15 características, estos métodos consistentemente demostraron mejores resultados que las técnicas SHAP.
En contextos de alta frecuencia transaccional, como los más de 2.800 intentos de fraude por minuto registrados en Brasil durante el primer trimestre de 2023, esta eficiencia se vuelve esencial. Además, la selección de características ayuda a mitigar problemas como el sobreajuste y la multicolinealidad, desafíos comunes en datasets financieros de alta dimensionalidad donde las transacciones fraudulentas representan solo el 0,17% del total.
Estos casos muestran cómo los métodos híbridos no solo aceleran el entrenamiento, sino que también mejoran notablemente la precisión en la detección de fraude.
En julio de 2025, Siam, Bhowmik y Uddin publicaron en PLOS ONE un estudio donde aplicaron un marco híbrido Pearson-IG-RFI al dataset "European Cardholders 2013", conocido por su desbalance extremo de clases. Este framework se desarrolló en tres etapas: (1) eliminación de variables redundantes mediante correlación de Pearson, (2) evaluación de relevancia con IG y RFI, y (3) fusión de las variables más relevantes.
El método híbrido superó de forma consistente a los enfoques tradicionales en cinco datasets con ratios de desbalance que iban del 0,172% al 55,51%. Según los autores:
"Los resultados demuestran que nuestra metodología supera a los enfoques baseline existentes, logrando un rendimiento superior en la detección de fraude en todos los datasets".
Además, resaltaron:
"Al reducir el número de características, logramos tiempos de entrenamiento más rápidos y minimizamos la complejidad computacional".
El framework fue validado contra cinco algoritmos de machine learning de última generación: Random Forest, Extra Trees, XGBoost, AdaBoost y CatBoost. Para identificar y eliminar características redundantes, se utilizó un umbral de correlación de Pearson de 0,95. Esto permitió desarrollar un sistema de soporte de decisiones en tiempo real para instituciones financieras. Además, PayPal implementó un framework híbrido similar que optimiza aún más la detección de fraude.
PayPal adoptó un sistema de unión/votación que combina métodos de filtro, wrapper y embebidos para mejorar sus modelos de detección de fraude sensibles al riesgo. Este enfoque híbrido integra diversas técnicas de selección para eliminar redundancias y mantener solo las características más relevantes.
La estrategia de PayPal refleja una tendencia en la industria hacia el uso de frameworks que aprovechan diferentes técnicas para procesar grandes volúmenes de datos transaccionales y clasificar fraudes con mayor precisión.
La selección de características es esencial en sistemas de e-commerce y pagos electrónicos, donde el manejo de enormes volúmenes de datos requiere identificar los atributos clave para detectar fraudes . Los frameworks híbridos han demostrado que reducir el número de características no solo acelera los tiempos de entrenamiento, sino que también mantiene altos niveles de precisión, incluso en contextos con alta frecuencia transaccional y desbalances extremos. Estos estudios subrayan la relevancia de la selección de características, marcando un camino claro para futuros avances en la detección de fraude.
La selección de características es un pilar fundamental en la construcción de modelos para detección de fraude. Al eliminar variables redundantes, no solo se reduce el riesgo de sobreajuste, sino que también se acelera el entrenamiento y se mejora la capacidad de interpretación del modelo, aspectos clave para auditorías y cumplimiento normativo. En un escenario donde las transacciones fraudulentas representan apenas el 0,17% del total de datos, enfocarse en variables realmente relevantes puede definir la diferencia entre un sistema eficiente y uno que genere constantes falsas alarmas.
Los enfoques híbridos han demostrado ser altamente efectivos, logrando disminuir hasta un 95% el número de variables sin comprometer la precisión. Por ejemplo, Random Forest puede alcanzar una exactitud del 99,96%, mientras que Support Vector Machines llega al 98,31% cuando se aplican técnicas de balanceo como SMOTE. Esta optimización no solo mejora el rendimiento, sino que permite implementar sistemas de detección en tiempo real, capaces de procesar miles de transacciones por minuto, una necesidad crítica en el e-commerce.
Carmen Scartezini, científica de datos, lo explica así:
"Al excluir variables con distribuciones altamente similares, podemos reducir el riesgo de multicolinealidad y mejorar la interpretabilidad y eficiencia del modelo".
Este tipo de simplificación es particularmente relevante en plataformas de comercio electrónico, donde la rapidez en la detección puede determinar si una transacción fraudulenta se bloquea a tiempo o no.
Los estudios analizados confirman que estos métodos son altamente efectivos. De cara al futuro, la detección de fraude se orienta hacia la integración de modelos optimizados, como FastTree, en APIs escalables. Esto permitirá que plataformas de e-commerce implementen sistemas de prevención sin necesidad de infraestructuras complejas. Además, la tendencia de priorizar el recall sobre la precisión refleja una comprensión más profunda del impacto del fraude: es preferible analizar algunas transacciones legítimas que correr el riesgo de dejar pasar una fraudulenta.
La combinación de métodos híbridos, balanceo de datos y validaciones estadísticas rigurosas está facilitando el acceso a sistemas de detección avanzados. Para plataformas con alto volumen de transacciones, la selección de características ya no es una opción, sino un requisito indispensable para desarrollar sistemas confiables, rápidos y capaces de adaptarse a los patrones en constante evolución del fraude digital.
Al elegir características para modelos de detección de fraude, es clave encontrar un balance entre rapidez y precisión. Aquí te explicamos tres enfoques comunes:
Cada método tiene su lugar, dependiendo de las necesidades y limitaciones del sistema.
Cuando trabajás con Random Forest y variables de alta cardinalidad, es común que estas últimas parezcan más importantes de lo que realmente son. Para evitar este sesgo, podés aplicar métodos como:
Ambas estrategias te ayudan a obtener una evaluación más equilibrada y precisa de la importancia de las variables en tu modelo.
Cuando el fraude alcanza apenas el 0,17%, resulta fundamental enfocarse en métricas que prioricen la precisión y minimicen los falsos positivos. Entre estos indicadores destaca la tasa de falsos positivos, ya que permite reducir el rechazo de transacciones legítimas, optimizando así la experiencia del cliente.