
El método RFE (Recursive Feature Elimination) es clave para optimizar modelos de detección de fraude. Permite identificar las variables más relevantes de grandes volúmenes de datos, eliminando aquellas que no aportan valor. Esto mejora la precisión y eficiencia de los sistemas, reduciendo el ruido y evitando problemas como el sobreajuste.
En resumen, RFE es una herramienta eficaz para sistemas que necesitan identificar patrones complejos en datos transaccionales, mejorando tanto la precisión como la velocidad operativa.
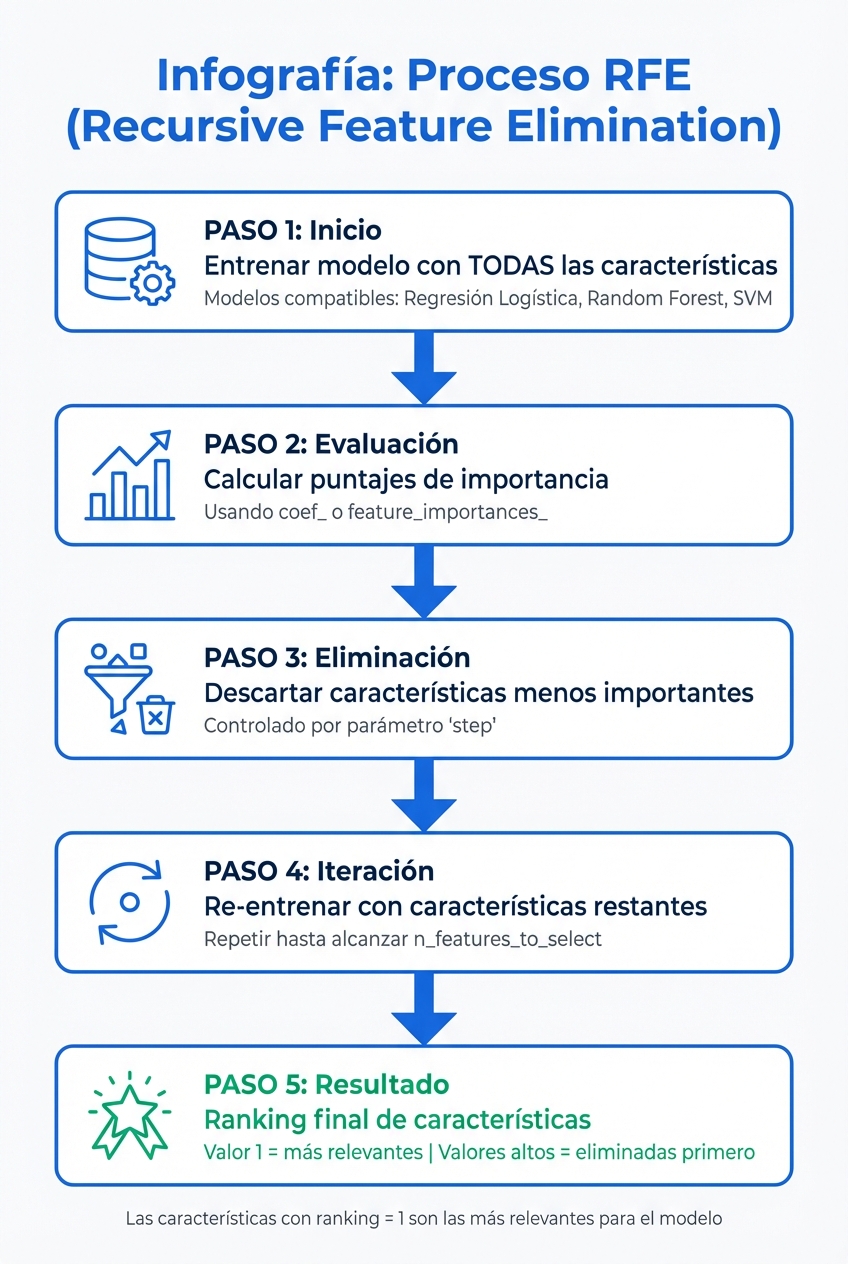
Cómo funciona el algoritmo RFE paso a paso en detección de fraude
RFE (Recursive Feature Elimination) simplifica el proceso de selección de características eliminando, de manera iterativa, las variables menos relevantes hasta encontrar el conjunto óptimo. El procedimiento comienza entrenando un modelo supervisado, como o , utilizando todas las variables disponibles en el dataset. Una vez ajustado el modelo, se calculan los puntajes de relevancia de cada característica a través de atributos específicos, como en modelos lineales o en modelos basados en árboles.
coef_feature_importances_A partir de estos puntajes, RFE identifica las variables menos importantes y las descarta. El modelo se entrena nuevamente con el subconjunto restante, permitiendo que la evaluación de importancia se ajuste dinámicamente a medida que se eliminan atributos irrelevantes o colineales. Este ciclo se repite hasta alcanzar el número de características deseado, definido por el usuario mediante el parámetro n_features_to_select.
El parámetro step controla cuántas variables se eliminan en cada iteración, lo que puede acelerar el proceso en datasets grandes. Al finalizar, RFE asigna un ranking a cada característica: las que llegan a la última iteración obtienen un valor de 1, indicando que son las más relevantes, mientras que las eliminadas antes reciben valores más altos.
Para que RFE funcione correctamente, es crucial elegir un modelo base que permita evaluar la importancia de las variables. Los modelos lineales, como Regresión Logística, SVM Lineal y Perceptron, utilizan el atributo coef_ para calcular la relevancia de cada predictor. Por otro lado, los modelos basados en árboles, como Decision Trees, Random Forest, XGBoost y Gradient Boosting, emplean feature_importances_, que mide la importancia según la reducción de impureza en los nodos.
| Tipo de modelo | Métrica de importancia | Ejemplos |
|---|---|---|
| Modelos lineales | coef_ (Coeficientes) | Regresión Logística, SVM Lineal, Perceptron |
| Modelos basados en árboles | feature_importances_ | Decision Trees, Random Forest, XGBoost, Gradient Boosting |
| Modelos de regresión | coef_ o feature_importances_ | SVR (Kernel Lineal), Decision Tree Regressor |
La elección del modelo base tiene un impacto directo en el rendimiento de RFE. Los modelos basados en árboles suelen ser más adecuados para datos no lineales, ya que calculan la importancia durante el entrenamiento. En cambio, los modelos lineales pueden beneficiarse de recalcular los rankings en cada iteración, especialmente en presencia de predictores colineales.
Además, para evitar la fuga de datos y garantizar una validación adecuada durante la selección de características, se recomienda usar RFECV dentro de un Pipeline. Esto asegura que el proceso de selección sea consistente y confiable.
El método RFE (Eliminación Recursiva de Características) ayuda a identificar las variables más importantes en datos transaccionales al analizar un conjunto completo de predictores y eliminar gradualmente aquellos menos relevantes. En sistemas de pago, este enfoque evalúa atributos clave como el monto de la transacción, la ubicación geográfica, la frecuencia de compras y el horario, lo que mejora la precisión al detectar fraudes.
El proceso consiste en entrenar un modelo con todas las variables disponibles y, en cada iteración, descartar las menos significativas. Esto permite que el sistema revalúe las variables restantes, eliminando la interferencia de datos redundantes o colineales. Al centrarse en los atributos clave, se mejora la detección de fraudes en pagos. Además, combinar RFE con otras técnicas de selección puede optimizar aún más los resultados.
Por ejemplo, en junio de 2021, investigadores usaron RFECV (RFE con validación cruzada) en sistemas de pago con tarjetas de crédito. Lograron reducir el conjunto de características a entre 10 y 13 atributos clave, acelerando significativamente el proceso de clasificación.
Otro estudio sobre fraude en sistemas de pago electrónico demostró que combinar técnicas de selección de características con estrategias de remuestreo generó un incremento financiero de hasta el 57,5% en comparación con los sistemas previos de detección. Este avance se logró eliminando características redundantes y conservando las más informativas, como el monto, la frecuencia y la ubicación de las transacciones. Reducir las variables no solo mejora la precisión del modelo, sino que también lo hace más rápido y eficiente para operar en tiempo real.
Para maximizar la efectividad, RFE se complementa con métodos de filtrado, creando marcos híbridos que combinan la eficiencia de los filtros con la precisión de los wrappers. Una estrategia común es usar un método de filtrado, como Chi-cuadrado o Información Mutua, para descartar características irrelevantes de manera inicial, y luego aplicar RFE para refinar el conjunto de datos basado en el rendimiento del modelo.
En un estudio sobre riesgo crediticio, se aplicó un método híbrido que combinaba χ² y RFE en un conjunto de datos con 47.172 muestras y 535 características iniciales. Este enfoque superó a otros seis métodos en términos de rendimiento promedio, manteniendo un tiempo de cómputo razonable.
| Método de selección | Costo computacional | Precisión | Dependencia del clasificador |
|---|---|---|---|
| Métodos de filtrado | Bajo (rápido) | Moderada | Independiente |
| Wrapper (RFE) | Alto (lento) | Alta | Dependiente |
| Híbrido (χ²-RFE) | Moderado | Muy alta | Dependiente (etapa final) |
Cuando se trabaja con conjuntos de datos que contienen cientos de características, comenzar con un método de filtrado puede reducir drásticamente la carga computacional. Además, optar por RFECV en lugar de RFE estándar permite ajustar automáticamente el número óptimo de características, asegurando una selección más estable y confiable en diferentes particiones de datos.
Entender los beneficios y limitaciones de RFE es clave para aprovecharlo al máximo en sistemas de detección de fraude. Este método mejora la precisión al eliminar características redundantes o ruidosas, lo que ayuda a reducir el sobreajuste. A diferencia de los métodos de filtrado, RFE puede capturar relaciones complejas entre variables transaccionales, como la interacción entre el monto, la frecuencia y la ubicación geográfica. Además, simplifica el modelo reduciéndolo a un número manejable de factores explicativos. Esto lo hace especialmente útil cuando se trabaja con datos de alta dimensionalidad, donde las dependencias entre atributos no siempre son evidentes. Sin embargo, también presenta ciertos desafíos.
Por un lado, su costo computacional es considerable. RFE requiere entrenar el modelo repetidamente, una vez por cada característica o grupo de características eliminadas, lo que puede hacerlo lento para conjuntos de datos grandes o modelos complejos.
Otro punto crítico es su dependencia del estimador base. Como se mencionó anteriormente, el modelo base elegido afecta directamente el rendimiento de RFE. Los rankings de características pueden variar según el estimador utilizado, por lo que es aconsejable emplear uno que sea similar al modelo final que se usará en producción. Además, existe el riesgo de pérdida de información si el estimador base no es capaz de identificar interacciones no lineales entre las variables.
| Ventajas | Desventajas |
|---|---|
| Mayor precisión: Reduce el sobreajuste al eliminar características no útiles. | Alto costo computacional: Requiere entrenar el modelo varias veces. |
| Mejor interpretabilidad: Simplifica el modelo a factores explicativos manejables. | Problemas de escalabilidad: Puede ser muy lento en conjuntos de datos grandes. |
| Captura interacciones: Encuentra relaciones complejas entre variables. | Dependencia del estimador: Los rankings varían según el modelo base. |
| Estabilidad: RFECV ofrece selecciones consistentes en diferentes particiones de datos. | Riesgo de pérdida de información: Puede descartar interacciones no lineales. |
A pesar de estos desafíos, RFE sigue siendo una herramienta efectiva cuando se combina con estrategias de optimización. Por ejemplo, aumentar el tamaño del paso (step) para eliminar varias características en cada iteración o usar procesamiento paralelo con el parámetro n_jobs puede reducir significativamente el tiempo de entrenamiento sin comprometer la calidad de la selección.
Al entender cómo funciona RFE y sus limitaciones, es útil compararlo con otras técnicas wrapper. Aunque RFE es una de las más conocidas, no es la única opción. Métodos como la selección hacia adelante (forward selection) y la selección por pasos (stepwise selection) ofrecen enfoques distintos para la selección de características. La diferencia principal radica en cómo abordan el proceso: mientras que RFE comienza con todas las características y elimina las menos relevantes de manera recursiva, forward selection parte de un conjunto vacío y va añadiendo variables una por una. Este contraste afecta su capacidad para identificar interacciones complejas entre variables, lo que tiene implicaciones prácticas en aplicaciones como la detección de fraude.
RFE tiene la ventaja de capturar esas interacciones complejas que forward selection podría pasar por alto. Esto se debe a que forward selection evalúa características en subconjuntos pequeños y crecientes, lo que limita su capacidad para reconocer combinaciones más intrincadas.
Sin embargo, esta ventaja también implica un costo. RFE es más demandante computacionalmente, ya que requiere entrenar el modelo con todas las características desde el inicio, algo que puede ser lento con conjuntos de datos grandes. En comparación, forward selection trabaja con modelos más simples al principio y puede ser más rápido cuando el subconjunto óptimo de características es pequeño. Además, RFE necesita un estimador que proporcione métricas de importancia como coef_ o feature_importances_, mientras que los otros métodos pueden funcionar con cualquier modelo que ofrezca una métrica de evaluación.
"RFE puede ser una técnica efectiva y relativamente eficiente para reducir la complejidad del modelo eliminando predictores irrelevantes. Aunque es un enfoque greedy, es probablemente el método más utilizado para selección de características." - Max Kuhn y Kjell Johnson
Para facilitar la comparación, aquí hay un resumen de las diferencias clave entre RFE y otros métodos.
| Característica | RFE | Forward Selection | Stepwise Selection |
|---|---|---|---|
| Dirección de búsqueda | Eliminación hacia atrás | Hacia adelante (agrega características) | Bidireccional (agrega y elimina) |
| Base del ranking | Pesos del modelo (coef_, feature_importances_) | Rendimiento del modelo (AUC, precisión) | Rendimiento del modelo (AIC, BIC, AUC) |
| Costo computacional | Alto | Menor | Moderado a alto |
| Captura de interacciones | Alta | Baja | Moderada |
| Requisito del modelo | Debe proporcionar importancia de características | Cualquier modelo con métrica de evaluación | Cualquier modelo con métrica de evaluación |
RFE se posiciona como una herramienta clave para mejorar los modelos de detección de fraude al destacar las características más relevantes dentro de conjuntos de datos complejos. Su capacidad para identificar interacciones entre variables lo hace ideal para abordar patrones de fraude no lineales, que suelen escapar a los métodos más tradicionales. Al eliminar de manera recursiva las características menos útiles, RFE no solo ayuda a prevenir el sobreajuste, sino que también mejora el desempeño estadístico del modelo. Estas mejoras teóricas se traducen en beneficios prácticos para sistemas en producción impulsados por IA.
Un beneficio concreto de RFE en el comercio electrónico es la reducción del tiempo de clasificación en producción. Aunque su proceso de implementación requiere un uso intensivo de recursos computacionales, una vez aplicado, logra disminuir considerablemente los tiempos de clasificación. Esto resulta crítico en contextos como la validación de transacciones con tarjeta de crédito, donde cada milisegundo puede marcar la diferencia.
Sin embargo, su alto costo computacional es un punto que no debe pasarse por alto. Para hacer más eficiente este proceso, es recomendable ajustar el parámetro step o aplicar filtros preliminares.
La efectividad de RFE, por otro lado, depende en gran medida de la selección del estimador base y del uso adecuado de validación cruzada para evitar sesgos en la selección de características. Cuando se implementa correctamente, RFE logra un balance sólido entre precisión y eficiencia, convirtiéndose en una herramienta confiable para sistemas de detección de fraude que necesitan maximizar su rendimiento sin comprometer la velocidad operativa.
No hay un número exacto de características que debas seleccionar al usar RFE (Eliminación Recursiva de Características) para la detección de fraude. Esto varía según el modelo que estés utilizando, la naturaleza de los datos y cómo se lleve a cabo la validación cruzada. En términos generales, lo ideal es ajustar el número de características seleccionadas para maximizar el rendimiento durante las pruebas de validación cruzada, logrando así los mejores resultados posibles.
Es fundamental realizar la selección de características únicamente en el conjunto de entrenamiento. Esto significa que no debes incluir datos de prueba o validación en este proceso. Si lo haces, podrías introducir sesgos y comprometer la evaluación del modelo.
Además, es recomendable utilizar validación cruzada para determinar cuántas características son realmente necesarias. Este enfoque ayuda a construir un modelo más sólido y confiable.
Por último, asegúrate de mantener una separación estricta entre los datos de entrenamiento y los datos de evaluación. Esto es clave para preservar la integridad del modelo y garantizar resultados más precisos.
Si querés que el proceso de Eliminación Recursiva de Características (RFE) sea más rápido, podés ajustar el parámetro step para eliminar varias características en cada iteración. Esto puede reducir el tiempo total de ejecución. Sin embargo, hay que hacerlo con cuidado, ya que eliminar demasiadas características de golpe podría afectar la precisión del modelo.
Otra estrategia útil es implementar validación cruzada para identificar cuántas características son realmente necesarias. Además, si tenés la posibilidad, simplificá el estimador o reducí la cantidad de características antes de aplicar RFE. Esto puede optimizar el proceso desde el inicio.