El análisis de regresión ayuda a prever la demanda futura en e-commerce, optimizando inventarios y reduciendo costos. Al combinar datos como precios, clima o ingresos, permite decisiones más precisas. Por ejemplo, Big Sky Foods disminuyó un 15% sus costos de inventario y un 60% los quiebres de stock al usar regresión múltiple. Además, modelos avanzados integrados con IA, como los usados por MercadoLibre, automatizan reabastecimientos y alertas, mejorando la eficiencia. Estas técnicas no solo evitan pérdidas por falta de stock, sino que también liberan capital inmovilizado en exceso de inventario.
Puntos clave:
La combinación de regresión e IA transforma la gestión de inventarios, logrando mayor precisión y eficiencia operativa.
Los modelos de regresión convierten la relación entre la demanda (Y) y sus factores influyentes (X₁, X₂, …, Xₙ) en ecuaciones matemáticas mediante la fórmula Y = a + b₁X₁ + b₂X₂ + ... + bₙXₙ + e. En esta ecuación, cada coeficiente b representa cuánto impacta cada variable X en la demanda estimada. Veamos cómo se comportan estos enfoques en situaciones reales.
La regresión lineal simple se enfoca en cómo un único factor afecta las ventas. Por ejemplo, puede analizar cómo la temperatura influye en la demanda de helados. Aunque es un buen punto de partida, en e-commerce tiende a quedarse corta. En julio de 2025, un estudio analizó este método en la plataforma HSR Wheels para predecir precios y stock del producto "BOROKO TJH HSR R18X8 H8X100-114.3 ET45 SANDY GREY". Los resultados mostraron un MAE de $2.071.435,85 y un R² del 1,2%, indicando una capacidad muy limitada para explicar la variabilidad.
Por otro lado, la regresión múltiple toma en cuenta varios factores al mismo tiempo, como precio, ingresos del consumidor, clima, actividad de la competencia y patrones estacionales. Este enfoque es más adecuado para el e-commerce, donde múltiples variables interactúan constantemente. Por ejemplo, Corporation Favorita, una cadena de supermercados ecuatoriana, encontró que las promociones tenían un impacto positivo en las ventas, mientras que los precios del petróleo afectaban negativamente el consumo minorista.
La regresión lineal es útil en escenarios donde una sola variable domina las ventas, pero no logra capturar la complejidad de entornos como el e-commerce. En cambio, la regresión múltiple permite analizar cómo varios factores influyen en la demanda de manera conjunta.
La transición a este enfoque mejora considerablemente el porcentaje de variabilidad explicada (R²), lo que se traduce en beneficios operativos concretos. Estos incluyen una mejor planificación de inventarios, reducción de costos y minimización de quiebres de stock.
En entornos de e-commerce, ciertas variables se destacan como las más influyentes. Estas se dividen en cuatro categorías principales:
Además, las variables operativas son especialmente relevantes en el e-commerce. Aspectos como el tipo de publicación (premium vs. clásica), el método de envío (fulfillment vs. cross-docking), los "minutos activos" (tiempo que un producto estuvo disponible) y los tiempos de entrega tienen un impacto directo en las preferencias del consumidor digital y permiten ajustar el stock con mayor precisión.
"La belleza [de la regresión] radica en su capacidad de considerar múltiples factores simultáneamente, brindándote una visión integral de qué impulsa tu demanda." - SLM (Self Learning Material) for MBA
Los patrones estacionales también juegan un papel importante. En el caso de los retailers de alimentos, las ventas tienden a seguir un patrón semanal con picos los lunes y durante los fines de semana (sábado y domingo). Ignorar estas variables puede llevar a errores en los pronósticos y problemas en la cadena de suministro, como exceso de inventario o quiebres de stock, ambos con consecuencias financieras negativas.
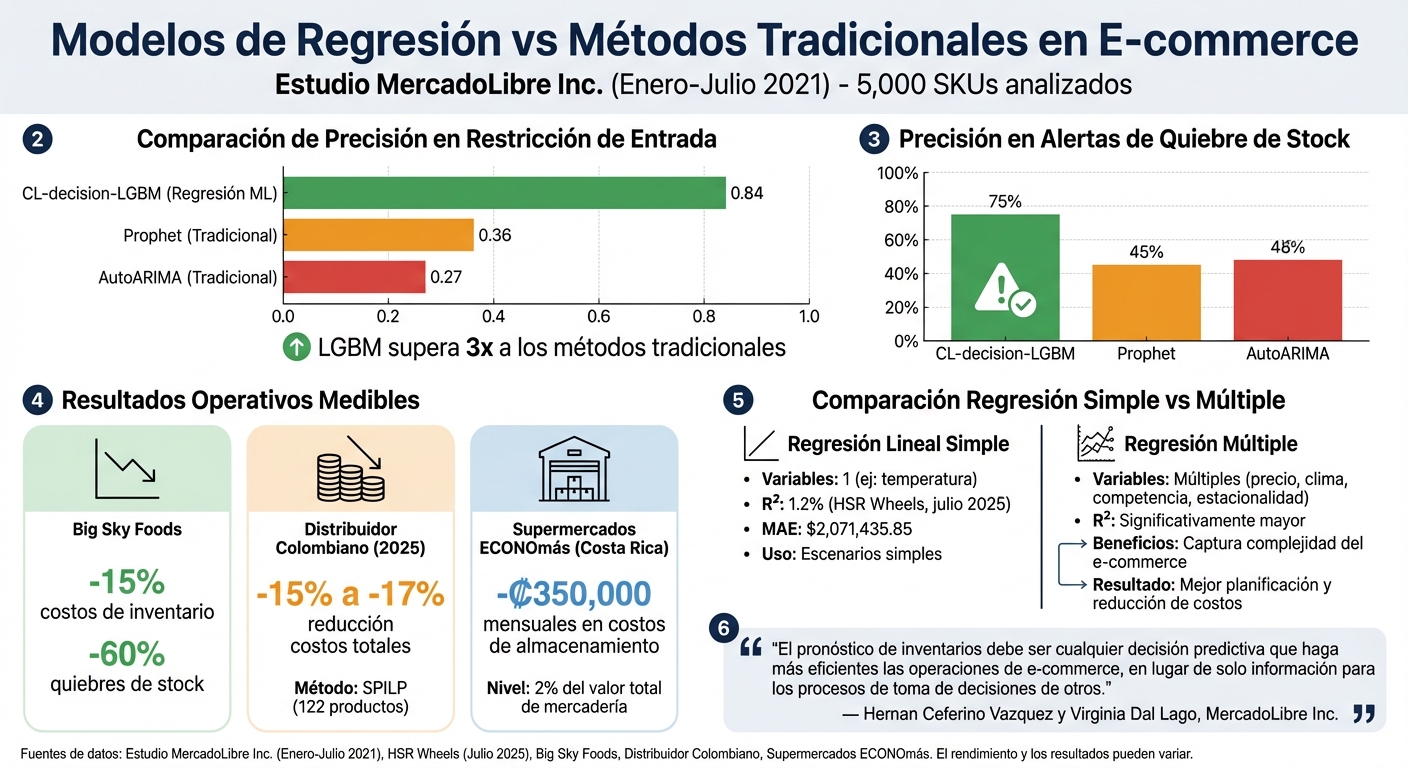
Comparación de modelos de regresión vs métodos tradicionales en gestión de inventarios e-commerce
Entre enero y julio de 2021, el equipo de Applied Machine Learning Research de MercadoLibre Inc. realizó un análisis comparativo con 5.000 SKUs. Los investigadores Hernan Ceferino Vazquez y Virginia Dal Lago evaluaron métodos tradicionales como AutoARIMA y Prophet frente a modelos de regresión basados en machine learning, como LGBM. Descubrieron que predecir directamente las decisiones de inventario (como reposición o limitación de unidades) era más eficiente que estimar la demanda para definir necesidades.
El modelo CL-decision-LGBM destacó por su precisión, logrando un puntaje de 0,84 en tareas de restricción de entrada, mientras que AutoARIMA y Prophet alcanzaron apenas 0,27 y 0,36, respectivamente. Además, este modelo de regresión logró un 75% de precisión en alertas de quiebre de stock, superando significativamente a AutoARIMA (48%) y Prophet (45%).
"El pronóstico de inventarios debe ser cualquier decisión predictiva que haga más eficientes las operaciones de e-commerce, en lugar de solo información para los procesos de toma de decisiones de otros." - Hernan Ceferino Vazquez y Virginia Dal Lago, Applied Machine Learning Research, MercadoLibre Inc.
Estos resultados impulsaron la adopción de modelos integrados, cuyos impactos se analizan en los siguientes casos.
En septiembre de 2025, un distribuidor colombiano de accesorios automotrices aplicó un modelo de Programación Lineal Entera Estocástica (SPILP) a 122 productos que representaban el 85% de sus ventas totales. Este enfoque combinó pronósticos de demanda estocástica con restricciones financieras reales, como presupuestos limitados y condiciones de crédito. El resultado fue una reducción promedio del 15% en costos totales, alcanzando hasta un 17% en algunos escenarios, sin comprometer los niveles de servicio.
En Costa Rica, en 2017, Maureen María Porras-Méndez implementó un modelo de gestión de inventarios basado en técnicas de predicción de ventas en los Supermercados ECONOmás. Este modelo permitió reducir los costos mensuales de almacenamiento en ₡350.000,00, manteniéndolos en un 2% del valor total de la mercadería.
Estos ejemplos no solo resaltan la precisión mejorada de los modelos de regresión, sino que también demuestran su impacto tangible en la reducción de costos operativos y la optimización de recursos.
La precisión de los modelos de regresión depende directamente de contar con datos actualizados y de calidad. Las plataformas de IA modernas facilitan este proceso al conectarse con fuentes como BigQuery, servidores SQL o sistemas de gestión de almacenes. Desde estas fuentes, extraen información clave como identificadores de productos, tickets de facturación, frecuencia de compra y variables de precio. Además, los procesos automatizados de aprendizaje automático permiten no solo la extracción diaria de datos, sino también el entrenamiento y la generación de predicciones. Esto asegura que los modelos reflejen los cambios repentinos en las tendencias del mercado o interrupciones en la cadena de suministro. Por ello, configurar extracciones diarias resulta crucial para mantener la vigencia de los datos.
La sincronización en tiempo real también abre la puerta a técnicas avanzadas como el aprendizaje cruzado. Este método utiliza información de múltiples series de productos al mismo tiempo, mejorando la precisión de los pronósticos, especialmente en el caso de artículos estacionales o poco relacionados entre sí. Un ejemplo de esto es Burbuxa, que sincroniza automáticamente datos como productos, pedidos, clientes, inventario, descuentos y políticas desde plataformas como Shopify, Tiendanube, VTEX o integraciones personalizadas vía API. Este enfoque asegura que tanto los modelos de regresión como los agentes de IA trabajen con información consistente y actualizada, estableciendo una base sólida para tomar decisiones operativas automatizadas, un tema que exploraremos más adelante.
Con datos actualizados, las automatizaciones de IA convierten las predicciones en acciones concretas. Ya no se trata solo de estimar cuántas unidades se venderán, sino también de decidir cuántas comprar, cómo distribuirlas o incluso restringir su ingreso al almacén.
Estas automatizaciones conectan directamente las salidas de los modelos de regresión con herramientas de producción, reduciendo el tiempo entre la predicción y la ejecución. Por ejemplo, si se detecta un riesgo de quiebre de stock en un producto de alta rotación, el sistema puede emitir automáticamente una orden de reposición o enviar alertas a través de plataformas como Slack o Salesforce . También es posible automatizar reglas de reabastecimiento: artículos estables de "clase X" pueden gestionarse de forma automática, mientras que productos más volátiles, como los de "clase Y" y "Z", se marcan para revisión manual. Este balance entre automatización y supervisión humana permite optimizar la eficiencia operativa y minimizar riesgos.
En el ámbito del e-commerce conversacional, Burbuxa utiliza estos datos sincronizados para que su agente de IA responda preguntas sobre disponibilidad, tiempos de reposición y productos complementarios con información precisa. Paralelamente, los flujos automatizados ajustan campañas como la recuperación de carritos abandonados o los recordatorios de recompra, basándose en los niveles de inventario proyectados por los modelos de regresión. Esto no solo mejora la experiencia del cliente, sino que también optimiza la gestión del inventario en tiempo real.
Los modelos de regresión ofrecen una ventaja clara frente a métodos tradicionales como EOQ, ya que permiten identificar dinámicas no lineales entre costos, demanda y pérdida de ventas. Esto se traduce en una reducción del Ratio de Rotación de Inventario (ITR) y en la liberación de capital que antes quedaba inmovilizado en stock innecesario.
Además, esta precisión transforma los procesos operativos. La integración con plataformas de IA lleva los resultados a otro nivel: cuando los datos se actualizan en tiempo real desde herramientas como Shopify, Tiendanube o VTEX, los modelos responden de inmediato a los cambios del mercado. Hernan Ceferino Vazquez de MercadoLibre lo resume perfectamente:
"El pronóstico de inventario debe ser cualquier decisión predictiva que haga más eficientes las operaciones de e-commerce, en lugar de solo información para los procesos de toma de decisiones de otros".
Como se mencionó, las automatizaciones convierten estas predicciones en acciones concretas: órdenes de reposición automáticas, alertas ante posibles quiebres de stock y ajustes en campañas de recuperación de carritos según los niveles proyectados. Un ejemplo práctico es el caso de Burbuxa, que utiliza esta sincronización para que su agente de IA responda consultas sobre disponibilidad con datos precisos y adapte flujos automatizados según el inventario real. Esto mejora tanto la experiencia del cliente como la eficiencia operativa.
El sistema no se limita a predecir, también ejecuta decisiones en tiempo real. Las empresas que implementan este enfoque logran un servicio optimizado, reducen el stock de seguridad y maximizan el rendimiento del capital invertido en inventarios. En un contexto donde el 90% de los datos de pequeños negocios sigue sin aprovecharse, la combinación de regresión e IA ofrece una ventaja competitiva que se traduce en resultados medibles.
Para desarrollar un modelo de regresión de demanda, es fundamental contar con datos históricos sobre las cantidades vendidas en períodos anteriores. Además, se deben incluir variables que puedan afectar la demanda, como precios, promociones, estacionalidad y características específicas del producto o del mercado.
También es útil incorporar información adicional, como el estado actual del inventario, los tiempos de entrega y factores externos, como tendencias del mercado o eventos relevantes. Estos elementos ayudan a refinar el modelo y a mejorar su precisión en las predicciones.
Todo depende de cuántas variables estén afectando la demanda. La regresión simple es perfecta cuando solo necesitas analizar cómo una única variable independiente influye en la dependiente. Es ideal para relaciones lineales y escenarios más básicos.
Por otro lado, la regresión múltiple entra en juego cuando hay varias variables influyendo al mismo tiempo. Esto la hace especialmente útil en contextos más complejos, como el e-commerce, donde múltiples factores pueden afectar los niveles de inventario. Eso sí, para aplicar esta técnica necesitas contar con suficientes datos para que el análisis sea confiable.
La regresión basada en inteligencia artificial (IA) facilita la automatización del proceso de reposición de inventario. A través de modelos predictivos, se analizan datos históricos como ventas anteriores y patrones estacionales para calcular los niveles óptimos de stock.
Estos modelos, integrados en plataformas como Burbuxa, permiten ajustar en tiempo real tanto los puntos de reorden como las cantidades necesarias. Esto no solo minimiza errores, sino que también ayuda a evitar problemas como rupturas de stock o acumulación excesiva de productos, optimizando así los costos logísticos.