
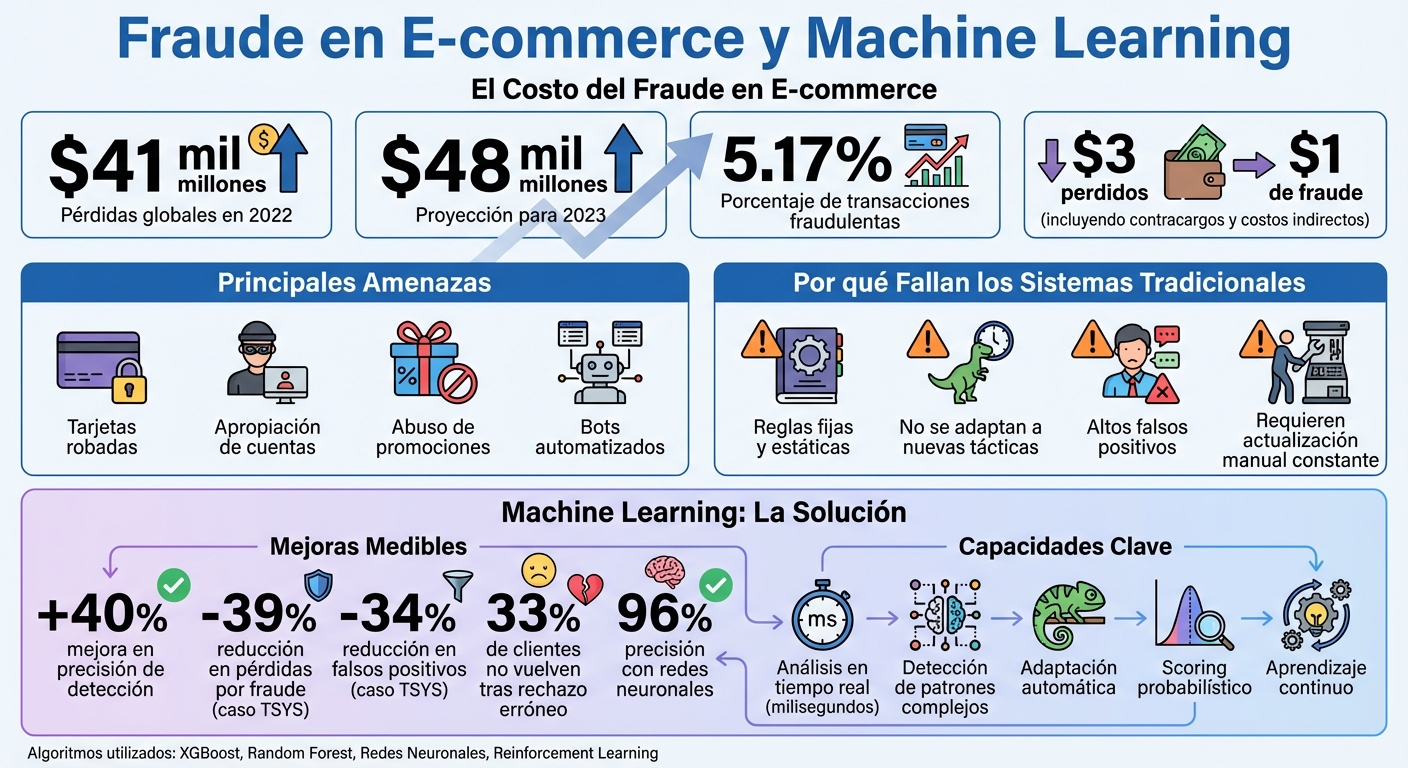
El fraude en e-commerce genera pérdidas millonarias y afecta tanto a empresas como a usuarios. En 2022, las pérdidas globales por pagos fraudulentos alcanzaron los $41.000 millones, y se proyectaron $48.000 millones para 2023. Los métodos tradicionales para combatirlo, basados en reglas fijas, no logran responder a tácticas cada vez más sofisticadas. Aquí es donde entra el machine learning, que permite analizar grandes volúmenes de datos en tiempo real, detectar patrones complejos y reducir errores como los falsos positivos.
El avance hacia modelos basados en inteligencia artificial no solo ayuda a prevenir pérdidas económicas, sino que también permite a las empresas generar confianza en sus clientes al ofrecer una experiencia más segura y fluida.
Fraude en E-commerce: Estadísticas Clave y Beneficios del Machine Learning
Los sistemas basados en reglas presentan limitaciones importantes, y los desafíos actuales se centran en responder en tiempo real, reducir los falsos positivos y adaptarse a tácticas fraudulentas que evolucionan constantemente. Las empresas enfrentan barreras técnicas y operativas que impactan directamente en su capacidad para protegerse sin comprometer la experiencia del cliente.
Los sistemas de detección deben procesar una enorme cantidad de datos en milisegundos, evaluando factores como geolocalización, huella digital del dispositivo, biometría pasiva y velocidad de navegación. Este desafío se intensifica durante eventos de alto tráfico como Black Friday o Hot Sale, donde un sistema diseñado para manejar 1.000 transacciones por hora podría colapsar si debe procesar 50.000 en el mismo tiempo.
Además, las transacciones fraudulentas representan una proporción mínima del total, lo que dificulta que los modelos detecten patrones sin sesgarse hacia las transacciones legítimas. En estos escenarios de alta demanda, es fundamental una respuesta precisa y rápida. Para lograrlo, se necesitan APIs de baja latencia que se integren directamente con el backend del e‑commerce y los sistemas de autorización de pagos, permitiendo operar sin afectar el rendimiento del sistema.
Rechazar transacciones legítimas puede ser tan costoso como el fraude mismo. Por cada $1 perdido por fraude, los comerciantes pierden cerca de $3 si se consideran contracargos, comisiones y costos de reemplazo de productos. Los falsos positivos no solo implican pérdidas económicas, sino que también afectan la confianza del cliente. En este sentido, integrar IA en WhatsApp puede ayudar a recuperar la comunicación y mejorar la experiencia tras un incidente. Un usuario rechazado por error es poco probable que vuelva a comprar en la misma tienda.
La inteligencia artificial puede ayudar a mejorar la precisión de los sistemas de detección hasta en un 40%, ajustando el scoring de riesgo con base en el comportamiento real del usuario. Sin embargo, este desafío se complica aún más por la rapidez con la que evolucionan las tácticas fraudulentas.
Los estafadores están en constante evolución, adaptándose más rápido que los sistemas tradicionales basados en reglas estáticas. Estas reglas suelen quedar obsoletas rápidamente, ya que son retrospectivas y requieren actualizaciones constantes para mantenerse relevantes frente a nuevos comportamientos.
Un ejemplo de éxito en este ámbito es el de TSYS, una compañía global de pagos que, en marzo de 2022, logró reducir las pérdidas por fraude en un 39% y los falsos positivos en un 34% gracias a la implementación de ARIC Risk Hub de Featurespace, una solución diseñada para tomar decisiones en tiempo real. Este caso evidencia cómo las herramientas adaptativas pueden superar las limitaciones de los enfoques tradicionales.
El machine learning ha transformado la detección de fraude al analizar múltiples variables al mismo tiempo, dejando atrás las reglas rígidas como "bloquear todas las tarjetas internacionales". Esta tecnología puede identificar patrones sutiles que los sistemas tradicionales no detectan, logrando una precisión que, según comerciantes que implementaron soluciones basadas en IA, mejora en un 40%. Además, a diferencia de los sistemas basados en reglas, que requieren constantes ajustes manuales, el machine learning se ajusta automáticamente a las nuevas tácticas de los estafadores.
Una de las claves es el uso de scoring probabilístico. Este enfoque asigna un valor de riesgo a cada transacción (por ejemplo, 0,7) basándose en datos como geolocalización, huella digital del dispositivo y biometría pasiva durante el proceso de compra. Este nivel de precisión es esencial, ya que el 33% de los consumidores no vuelve a comprar en una tienda si su transacción legítima es rechazada erróneamente.
Para analizar el fraude desde múltiples ángulos, se combinan algoritmos supervisados y no supervisados. Los supervisados, como la regresión logística, Random Forest y XGBoost, trabajan con datos etiquetados para identificar patrones conocidos. Por ejemplo, Marisa Zizmond, investigadora en Argentina, utilizó XGBoost y Random Forest para analizar 23.634 transacciones, descubriendo que variables como la antigüedad de la cuenta, la hora de la transacción y el monto eran las más relevantes.
Mientras tanto, los algoritmos no supervisados, como el clustering (k-means) e Isolation Forest, destacan por detectar anomalías en datos que no encajan con perfiles de fraude ya conocidos. Esta combinación permite abordar tanto fraudes tradicionales (como el uso de tarjetas robadas) como tácticas emergentes.
Los modelos de machine learning analizan varias categorías de señales para determinar el riesgo de cada transacción:
| Categoría de señal | Indicadores específicos analizados |
|---|---|
| Identidad y cuenta | Antigüedad de la cuenta, historial de compras, intentos fallidos de login |
| Dispositivo y técnica | Dirección IP, huella digital del dispositivo, sistema operativo, diferencia entre hora local y UTC |
| Transaccional | Montos atípicos, categoría de producto, cantidad de ítems, frecuencia de uso |
| Comportamiento | Velocidad de tipeo, gestos de deslizamiento, patrones de navegación |
| Geográfica | País de emisión de la tarjeta, geolocalización del IP, distancia entre direcciones de envío y facturación |
Empresas como Stripe aprovechan el efecto de red para mejorar la precisión. Procesando el 90% de las tarjetas que ya se han usado en su red, pueden asignar scores de riesgo basados en el historial global de cada tarjeta.
La capacidad de adaptarse es lo que diferencia al machine learning. Los algoritmos ajustan automáticamente el peso de las variables a medida que los estafadores cambian sus tácticas, eliminando la necesidad de actualizar manualmente las reglas. Según Oscar Aparicio, Product Owner de Corebiz:
"El mayor diferenciador es la adaptabilidad, ya que a medida que los atacantes modifican sus tácticas, los algoritmos ajustan sus pesos sin necesidad de reglas manuales".
Además, los modelos se mantienen actualizados gracias al reentrenamiento continuo con datos recientes. Algunos sistemas avanzados incluso utilizan embeddings (representaciones matemáticas) para transferir conocimiento entre regiones. Por ejemplo, si se detecta un nuevo tipo de fraude en Brasil, el modelo puede reconocerlo en Estados Unidos sin necesidad de un reentrenamiento específico. Este enfoque de transfer learning permite responder más rápido a nuevas amenazas y reduce el tiempo necesario para adaptarse.
Después de analizar las limitaciones de los sistemas basados en reglas y la evolución del machine learning, es momento de adentrarnos en las técnicas de deep learning y reinforcement learning, que representan un paso adelante en la detección de fraudes. Estas herramientas avanzadas son capaces de identificar patrones complejos que los métodos clásicos no logran captar, ajustándose automáticamente a las tácticas en constante cambio de los estafadores.
Las redes neuronales tienen la capacidad de identificar relaciones no lineales entre variables como el monto de una transacción, la ubicación geográfica, la huella digital del dispositivo y señales de comportamiento del usuario. Esta habilidad es clave en el contexto del e-commerce, donde se generan datos complejos en múltiples capas, desde la presentación hasta la lógica y los datos.
Un estudio publicado en el International Journal of Advanced Computer Science and Applications mostró que las redes neuronales alcanzaron una precisión del 96% en la detección de fraudes, superando a otros modelos como Random Forest (95%), Naive Bayes (95%) y Decision Tree (91%).
Además, las redes neuronales pueden procesar información de biometría conductual, como la velocidad al escribir, los gestos al deslizar en una pantalla y el uso general de una aplicación. Esto permite verificar identidades y detectar anomalías de manera más efectiva, especialmente contra bots avanzados y casos de apropiación de cuentas.
El reinforcement learning actúa como un "agente" que interactúa con el entorno de transacciones, recibiendo recompensas por detecciones correctas y penalizaciones por errores. Este sistema, basado en prueba y error, optimiza de forma autónoma su estrategia de detección. Según Stripe:
"El objetivo del algoritmo es aprender la mejor estrategia, o política, para tomar decisiones que aumenten sus recompensas acumuladas a lo largo del tiempo. Lo hace mediante prueba y error, adaptando y mejorando su estrategia basándose en la retroalimentación".
Gracias a su capacidad de aprendizaje continuo, estos modelos se actualizan constantemente con datos nuevos, adaptándose a amenazas emergentes como el "fraude amistoso" o el robo de cuentas. A diferencia de los sistemas basados en reglas estáticas (como "bloquear si el monto > $500"), el reinforcement learning puede identificar conexiones ocultas entre cientos de variables que escapan a la percepción humana.
Estas características hacen que el reinforcement learning no solo complemente los enfoques tradicionales, sino que también aumente la capacidad adaptativa de los sistemas, lo que resulta especialmente útil para aplicaciones en el e-commerce.
El uso de estas técnicas avanzadas no solo mejora la capacidad de detección, sino que también optimiza las decisiones en tiempo real, minimizando errores que podrían afectar la experiencia del cliente y reducir ingresos. En muchos casos, los comerciantes que implementaron soluciones basadas en inteligencia artificial reportaron hasta un 40% de mejora en la precisión del sistema.
Estos modelos probabilísticos correlacionan múltiples dimensiones - geolocalización, huella digital y biometría pasiva - con una latencia casi imperceptible. Corebiz lo explica así:
"La IA permite refinar el scoring de riesgo basándose en el comportamiento real del usuario, minimizando errores sin sacrificar seguridad".
Para plataformas de e-commerce en Argentina, este enfoque es esencial. La precisión en la detección debe equilibrarse con una experiencia fluida para los usuarios legítimos. Con pérdidas globales por fraude en pagos online que alcanzaron los $41.000 millones en 2022 y una proyección de $48.000 millones para 2023, queda claro que implementar sistemas que evolucionen al ritmo de las amenazas es una prioridad urgente.
Implementar un sistema de machine learning para detección de fraude en producción no es solo un tema técnico; requiere la colaboración estrecha entre equipos clave como riesgo, pagos, producto y atención al cliente. Esta coordinación es fundamental para superar desafíos como el procesamiento en tiempo real y la capacidad de adaptación continua, mencionados anteriormente.
Para que el sistema funcione eficazmente, es necesario integrarlo a través de APIs de baja latencia. Esto permite realizar verificaciones antifraude en el checkout en cuestión de milisegundos, garantizando que la validación ocurra antes de autorizar el pago sin generar fricción perceptible para el cliente.
Otro paso crucial es establecer umbrales de riesgo consensuados. Esto asegura un equilibrio entre rechazos automáticos y casos que requieren revisión manual, impactando directamente en la tasa de conversión y en los costos operativos. Estas optimizaciones son fundamentales para mejorar el CTR en ecommerce al asegurar que las ofertas lleguen a usuarios legítimos. Como lo menciona Oscar Aparicio, Product Owner de Corebiz:
"La IA antifraude no puede ser una caja negra".
Además, es indispensable monitorear y reentrenar los modelos de forma continua utilizando datos actualizados. Esto permite enfrentar nuevas tácticas de fraude que evolucionan constantemente. Un enfoque híbrido, que combine puntuaciones automáticas con la intervención humana en casos límite, no solo optimiza costos, sino que también reduce errores. Una vez implementado, el sistema puede generar beneficios tangibles, como los que se describen a continuación.
El rendimiento del modelo debe evaluarse utilizando métricas como precisión, recall y F1 Score. Los comercios que implementan sistemas de detección de fraude basados en IA suelen lograr mejoras de hasta un 40% en la precisión. Esto se traduce en menos bloqueos de transacciones legítimas y una reducción significativa del fraude no detectado.
Los beneficios también incluyen una disminución en el volumen de revisiones manuales, menores costos de personal, reducción de contracargos y una mejora en la experiencia del cliente. Al reducir los falsos positivos, el proceso de compra se vuelve más fluido y satisfactorio.
En Argentina, estas soluciones ya están presentes en plataformas avanzadas. Por ejemplo, Burbuxa utiliza agentes de IA para gestionar ventas y soporte en canales como WhatsApp e Instagram. Además, sincroniza en tiempo real productos, pedidos e inventario desde plataformas como Shopify, Tiendanube o VTEX. Su arquitectura conocida como "Commerce Brain" permite que todos los módulos, incluida la detección de anomalías, compartan un único conjunto de datos. Esto facilita una respuesta coordinada ante comportamientos sospechosos, eliminando la necesidad de desarrollos personalizados.
El fraude en el e-commerce sigue siendo un desafío constante y costoso. Frente a este panorama, los sistemas basados en reglas fijas han quedado obsoletos. El machine learning se presenta como una solución que permite adaptarse en tiempo real, identificando amenazas emergentes sin necesidad de intervención manual. Esto se logra ajustando automáticamente sus parámetros a medida que los atacantes cambian sus tácticas .
El balance entre seguridad y experiencia del usuario es clave. Gracias al refinamiento del scoring de riesgo basado en el comportamiento individual de cada usuario, el ML logra reducir significativamente los falsos positivos. Esto no solo protege las tasas de conversión, sino que también refuerza la confianza de los clientes .
Según Elio Rincón, VP de Ingeniería en Conekta:
"El machine learning no es milagroso, pero con el enfoque correcto y un conocimiento profundo del comportamiento del usuario, se convierte en una herramienta poderosa para construir un entorno de pagos más seguro y fluido".
Los avances en ML ya están mostrando resultados concretos: por cada $1 perdido debido al fraude, las empresas pierden alrededor de $3 al incluir contracargos, comisiones y costos de reposición de mercadería. Reducir estas pérdidas tiene un impacto directo en la rentabilidad.
El camino a seguir es claro: los modelos híbridos son el próximo paso. Estos combinan la velocidad y eficiencia de la inteligencia artificial, que puede procesar hasta el 98% de las transacciones, con la intervención humana en los casos más complejos, que representan cerca del 2% restante. Esta combinación asegura un equilibrio entre altas tasas de aprobación y un control efectivo del riesgo. Sin embargo, implementar esta tecnología no es tarea sencilla; requiere la colaboración de equipos de riesgo, pagos, producto y atención al cliente para definir umbrales y estrategias coherentes.
Como se ha discutido, adoptar machine learning para la prevención de fraude no es solo una ventaja competitiva, sino una estrategia esencial para cualquier e-commerce que busque proteger sus ingresos, mejorar la eficiencia operativa y construir relaciones de confianza duraderas con sus clientes.
Para desarrollar un modelo eficaz contra el fraude en e-commerce, es indispensable contar con un conjunto de datos que capture la información esencial de cada transacción. Algunos de los datos clave que deben incluirse son:
Además, incluir variables adicionales como la antigüedad de la cuenta y el horario de la transacción puede mejorar la precisión del modelo al proporcionar mayor contexto sobre los comportamientos de los usuarios.
Dado que los casos de fraude suelen ser una minoría en los datos, el preprocesamiento es un paso crítico. Esto implica manejar el desbalance entre clases (fraude vs. no fraude) y solucionar problemas de calidad en los datos, como valores faltantes o inconsistencias. Un enfoque cuidadoso en esta etapa puede marcar la diferencia en el desempeño del modelo.
Para lograr un equilibrio entre detectar fraudes y evitar falsos positivos, es fundamental ajustar cuidadosamente los modelos de machine learning. El objetivo es maximizar la detección de actividades fraudulentas sin interferir con las compras legítimas de los clientes.
Un enfoque útil es implementar análisis adaptativos que puedan ajustar los umbrales automáticamente en función de los patrones más recientes. Esto permite que el sistema se mantenga actualizado frente a nuevas tácticas de fraude. Además, la calibración continua y el aprendizaje automático son herramientas clave para encontrar el balance perfecto entre seguridad y una experiencia de usuario fluida.
El reentrenamiento de los modelos debe realizarse de forma regular y ajustarse a los cambios, ya que los atacantes siempre están ideando nuevos métodos. Por lo general, se sugiere actualizar los modelos de machine learning cada semana o mes, dependiendo del volumen de transacciones y la rapidez con que evoluciona el fraude. Mantenerlos al día es clave para detectar amenazas de manera eficaz, reduciendo tanto los falsos positivos como los negativos frente a riesgos emergentes.