
El algoritmo K-Means es una herramienta clave para identificar fraudes en e-commerce. A diferencia de los métodos tradicionales, analiza patrones de comportamiento normal en transacciones y detecta anomalías sin necesidad de datos etiquetados. Esto lo hace ideal para enfrentar tácticas de fraude nuevas y dinámicas.
¿Por qué funciona?
Implementación técnica:
Desafíos:
Definir el número de clusters (K) y manejar valores extremos. Técnicas como el Método del Codo y el Silhouette Score ayudan a optimizar el modelo.
En la práctica, K-Means se ha usado para detectar fraudes con tarjetas de crédito y cuentas comprometidas, destacándose por su capacidad de segmentar riesgos y generar alertas tempranas. Su integración con otros modelos mejora la precisión y reduce falsos positivos.
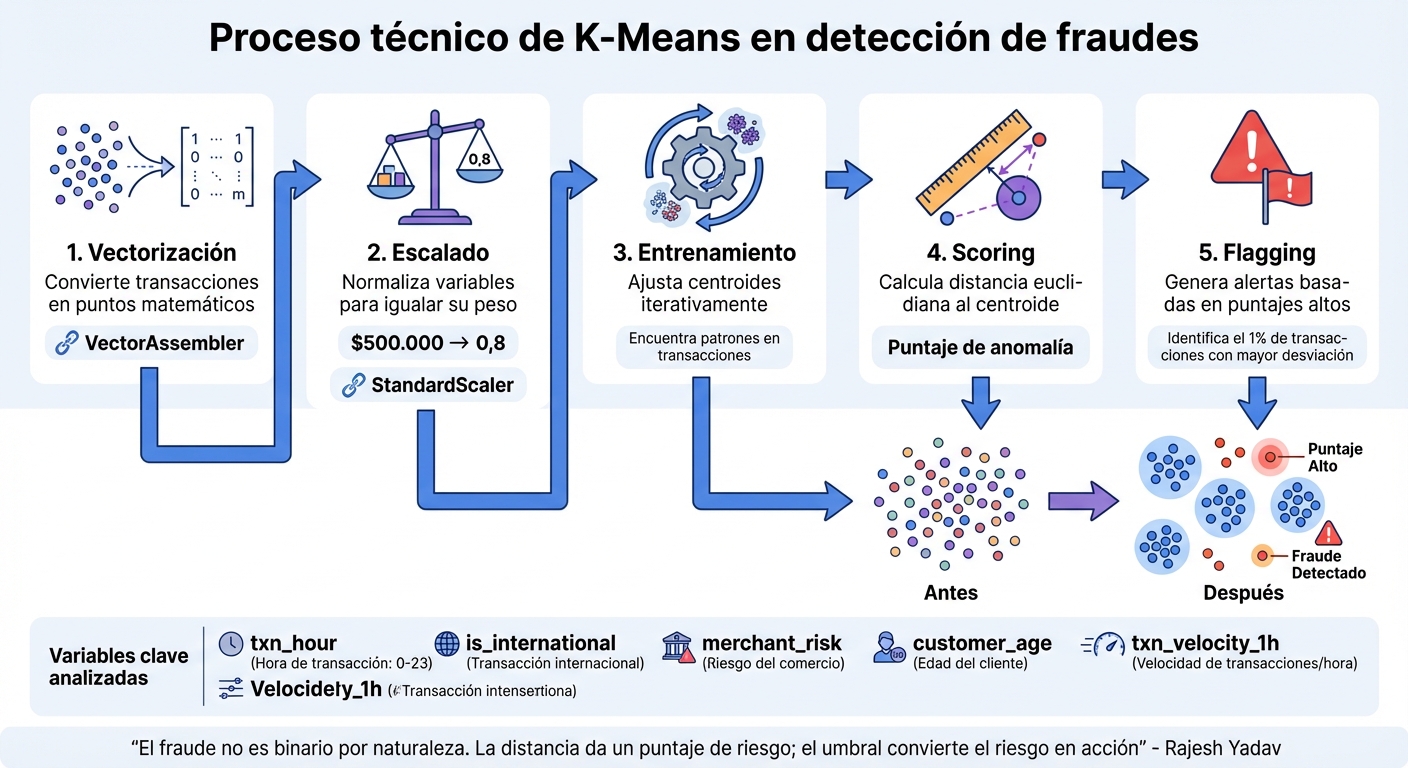
Proceso de implementación técnica de K-Means para detección de fraudes
K-Means funciona de manera iterativa y se basa en cálculos de distancia para identificar patrones. El algoritmo comienza asignando posiciones aleatorias a los centros de los clusters, luego clasifica cada transacción al centro más cercano, recalcula las posiciones promediando los puntos asignados y repite este ciclo hasta que los centros se estabilizan. Una vez entrenado, evalúa cada transacción según su distancia al centroide más próximo. Como señala Rajesh Yadav:
"El fraude no es binario por naturaleza. La distancia da un puntaje de riesgo; el umbral convierte el riesgo en acción".
Aquí se explican las etapas técnicas principales de este proceso.
VectorAssembler.StandardScaler para que todas las características tengan el mismo peso en los cálculos.La selección de variables o características es fundamental. Indicadores como la hora de la transacción (txn_hour), si es internacional (is_international), el riesgo del comercio (merchant_risk), la edad del cliente (customer_age) y la velocidad de transacciones en una hora (txn_velocity_1h) ayudan a detectar comportamientos atípicos.
Uno de los mayores retos es definir cuántos clusters (K) usar. Si se eligen pocos, se corre el riesgo de mezclar comportamientos normales y fraudulentos. Si se eligen demasiados, podría haber fragmentación y un aumento de falsos positivos. Una técnica útil es el método del codo, que grafica el costo de entrenamiento (WCSS) para distintos valores de K y encuentra el punto donde agregar más clusters deja de ser efectivo. Complementar con el Silhouette Score ayuda a medir la calidad de los clusters: un valor superior a 0,6 es ideal, entre 0,4 y 0,6 es aceptable, y por debajo de 0,3 indica problemas en la agrupación.
Además, K-Means asume que los clusters son esféricos y puede ser muy sensible a valores extremos. Un outlier puede alterar un centroide y desvirtuar la detección de patrones normales. Por este motivo, muchas empresas combinan K-Means con otros enfoques, usándolo como un sistema de alerta temprana para identificar anomalías y luego complementándolo con modelos supervisados o reglas específicas para tomar decisiones finales.
Estos detalles técnicos son esenciales para ajustar el algoritmo a las necesidades del e-commerce en Argentina, donde estos desafíos se enfrentan en casos prácticos del sector.
A continuación, exploramos casos concretos que muestran cómo el algoritmo K-Means se utiliza en el comercio electrónico, tanto en Argentina como en Latinoamérica, para combatir distintos tipos de fraude.
En enero de 2022, Diego Barragán Garnica, especialista en gestión financiera del Banco Davivienda en Colombia, implementó K-Means para analizar el comportamiento de usuarios con tarjetas de crédito. Este modelo permitió identificar grupos de clientes con diferentes niveles de riesgo, destacando señales que los métodos tradicionales suelen pasar por alto.
El análisis incluyó variables como el monto de las transacciones, la velocidad de compra (txn_velocity_1h) y el puntaje de riesgo del comercio (merchant_risk). A través de la distancia euclidiana, se priorizaron las revisiones manuales en función del nivel de riesgo específico de cada transacción.
K-Means también es eficaz para identificar cuentas comprometidas, detectando cambios abruptos en el comportamiento sin depender de datos históricos etiquetados. Un caso destacado de 2026 mostró cómo un framework técnico, utilizando PySpark y K-Means, procesó millones de transacciones casi en tiempo real en entornos bancarios y de e-commerce. El sistema agrupó características como txn_velocity_1h y merchant_risk, identificando anomalías cuando la distancia al centro del cluster habitual superaba un umbral ajustado, como 2,0. Esto permitió establecer un sistema de detección de fraude auditable y escalable.
El algoritmo también analiza variables como la hora de las transacciones (txn_hour), la ubicación geográfica (is_international) y la frecuencia de compras. Por ejemplo, si un usuario que usualmente compra entre las 14:00 y las 20:00 en Buenos Aires realiza transacciones en horarios inusuales desde otro país, la desviación respecto a su comportamiento habitual aumenta. Según Rajesh Yadav:
"¿Cómo se ve el comportamiento normal? Una vez que aprendemos lo normal, cualquier cosa alejada se vuelve sospechosa".
Esta técnica permite segmentar riesgos en diversos escenarios, como el monitoreo de transacciones de alto riesgo.
Muchas plataformas emplean K-Means para segmentar transacciones según su nivel de riesgo, optimizando los recursos al concentrarse en las operaciones más sospechosas. El algoritmo agrupa las transacciones en clusters según su comportamiento y aplica umbrales basados en percentiles. Por ejemplo, las transacciones que se encuentran en el 1% superior de distancia desde los centros de cluster son marcadas automáticamente para revisión.
Este método mejora la eficiencia de los equipos de prevención de fraude, ya que transacciones realizadas en horarios inusuales o con velocidades de compra atípicas son detectadas rápidamente. Como se destaca en la industria:
"Use K-Means as an early-warning system, then pass signals to XGBoost or rules".
De esta manera, K-Means funciona como un sistema de alerta temprana, complementando otros métodos en lugar de reemplazarlos.
Para aplicar K-Means en la detección de fraudes, necesitás trabajar con datos transaccionales, de comportamiento y demográficos. Algunas variables clave incluyen el monto de la transacción, la hora del día (0–23), indicadores de transacciones internacionales, puntajes de riesgo del comercio, edad del cliente y la frecuencia de transacciones (por ejemplo, cuántas operaciones realiza un usuario en una hora).
El preprocesamiento es un paso esencial. Primero, transformá los datos en vectores matemáticos utilizando herramientas como VectorAssembler, ya que los algoritmos de clustering operan en espacios multidimensionales. Luego, aplicá una estandarización con StandardScaler para evitar que variables con rangos amplios (como el monto de la transacción) dominen sobre otras con rangos más pequeños (como los puntajes de riesgo). Para determinar el número ideal de clusters (K), recurrí al Método del Codo. Este método consiste en graficar la suma de cuadrados dentro de cada cluster (WCSS) y buscar el punto donde agregar más clusters deja de reducir significativamente el error. Una vez que tengas los datos listos, podés integrarlos en tu sistema de detección de fraudes.
Con los datos procesados, el siguiente paso es integrar K-Means en la arquitectura de detección de fraudes que ya estés utilizando. Este algoritmo es especialmente útil como parte de un sistema híbrido. Funciona como una herramienta para identificar patrones de comportamiento "normal" y asignar un puntaje de riesgo basado en la distancia al centro del cluster. Las transacciones que se desvían significativamente de este centro se etiquetan como anomalías, y luego pueden ser evaluadas por modelos supervisados o motores de reglas para tomar decisiones finales.
En lugar de usar un umbral fijo, es mejor implementar umbrales dinámicos basados en percentiles. Por ejemplo, podés marcar el 1% de las transacciones con los puntajes de distancia más altos. Esto permite que el sistema se ajuste automáticamente a cambios en los volúmenes y patrones de datos, sin necesidad de contar con datos previamente etiquetados. Este enfoque flexible es ideal para adaptarse rápidamente a las tácticas cambiantes de los estafadores.
Una vez que el modelo esté integrado, es esencial mantenerlo actualizado para que siga siendo efectivo frente a las nuevas tácticas de fraude. Como señala Rajesh Yadav:
"Fraud is not static. Fraudsters continuously change transaction amounts, locations, timing, and merchant behavior".
Por esta razón, es necesario actualizar regularmente los clusters y reentrenar el modelo.
Podés evaluar el rendimiento del modelo utilizando el Silhouette Score, que mide qué tan bien definidos están los clusters. Además, realizá análisis periódicos con el Método del Codo para asegurarte de que la cantidad de clusters sigue representando adecuadamente los perfiles de los clientes. Este mantenimiento continuo es clave para mantener el sistema eficiente y preparado frente a nuevas amenazas.
K-Means tiene características que lo posicionan como una herramienta valiosa para plataformas de e-commerce. Su capacidad para manejar millones de transacciones casi en tiempo real, especialmente al usar frameworks como PySpark, lo hace práctico y eficiente. Además, su diseño es fácil de interpretar: la distancia al centro del clúster sirve como un puntaje de anomalía que puede auditarse. Como señala Rajesh Yadav:
"K-Means clustering answers a simple but powerful question: 'What does normal behavior look like?' Once we learn normal, anything far away becomes suspicious".
Gracias a este enfoque, el algoritmo detecta anomalías sin necesidad de depender de datos etiquetados previamente.
Otra ventaja es su flexibilidad. Los clústeres pueden reentrenarse regularmente para adaptarse a nuevas tácticas de fraude, como variaciones en montos, ubicaciones o horarios de las transacciones. Esto lo convierte en un sistema de alerta temprana que puede complementar modelos supervisados o motores de reglas. Estas características lo posicionan como una herramienta sólida en la lucha contra el fraude.
A futuro, K-Means se integrará más en sistemas híbridos. En lugar de trabajar de manera independiente, identificará comportamientos inusuales y enviará estas señales a modelos supervisados, como XGBoost, para tomar decisiones más precisas y minimizar los falsos positivos.
También se espera un mayor uso de umbrales dinámicos basados en percentiles, como identificar el 1% de las transacciones con mayor riesgo. Este enfoque permite que el modelo se ajuste automáticamente a cambios estacionales en los hábitos de compra, eliminando la necesidad de ajustes manuales constantes. Mientras las tácticas de fraude sigan evolucionando, K-Means seguirá siendo una herramienta clave para detectar patrones nuevos que no cuenten con etiquetas históricas ni reglas predefinidas.
La integración de estas estrategias en soluciones de e-commerce, como las ofrecidas por Burbuxa, fortalece tanto la seguridad como la eficiencia en la detección de fraudes.
El valor de K debe ajustarse teniendo en cuenta la cantidad de datos disponibles y el nivel de detalle que se busca. Una buena práctica es empezar con valores pequeños para identificar grupos más específicos y luego incrementarlo gradualmente según la escala de los datos y el nivel de precisión que se necesite.
Las variables clave para identificar fraude con K-Means son:
Estas variables ayudan a identificar patrones sospechosos y a detectar anomalías en tiempo real.
Definir un umbral efectivo para identificar transacciones sospechosas requiere un análisis detallado de datos históricos y el uso de modelos predictivos. Es importante tener en cuenta varias variables clave, como:
El objetivo es encontrar un equilibrio entre detectar actividades fraudulentas y minimizar los falsos positivos. Además, el umbral debe ajustarse de manera dinámica para adaptarse a los cambios en los patrones de fraude, garantizando así su eficacia a lo largo del tiempo. Esto asegura que el sistema siga siendo confiable y relevante frente a nuevas amenazas.