
La detección de fraude en transacciones digitales es un desafío crítico en el comercio electrónico. Los modelos híbridos CNN-RNN combinan dos técnicas avanzadas de aprendizaje profundo para abordar problemas como el desbalance de clases, la evolución constante de tácticas fraudulentas y la necesidad de respuestas en tiempo real. Mientras las CNN identifican patrones locales en las transacciones, las RNN analizan cómo estos patrones cambian a lo largo del tiempo, logrando una precisión del 99,4% y un recall del 99,9% en pruebas recientes.
El uso de estas arquitecturas mejora la detección de fraude, reduce falsos positivos y permite una implementación efectiva en sistemas de comercio electrónico. Además de la seguridad, es posible optimizar ventas con IA en Shopify para mejorar la experiencia del cliente. Sin embargo, su entrenamiento requiere recursos computacionales significativos y conjuntos de datos bien etiquetados.
Las CNN son herramientas clave para analizar patrones espaciales y relaciones entre variables en los datos transaccionales. En lugar de examinar cada dato de forma aislada, estas redes identifican conexiones entre factores como el monto, la ubicación, el dispositivo utilizado y la hora de la transacción, lo que les permite detectar combinaciones inusuales que otros métodos podrían pasar por alto.
Dependiendo de los recursos disponibles y las necesidades de precisión, se pueden usar diferentes tipos de arquitecturas CNN. Por ejemplo, las redes más superficiales son ideales para tareas en tiempo real debido a su menor consumo de memoria, mientras que las más profundas ofrecen mayor precisión, aunque requieren más capacidad computacional. Este análisis detallado prepara el terreno para entender cómo las RNN complementan este enfoque al trabajar con datos secuenciales.
Las Redes Neuronales Recurrentes (RNN) están diseñadas para analizar cómo evolucionan las transacciones a lo largo del tiempo. Mientras las CNN se enfocan en cada transacción individual, las RNN observan cómo estas interacciones cambian en secuencia, detectando patrones de comportamiento que podrían indicar fraude.
"Las RNN, como LSTM o GRU, analizan estas representaciones secuenciales, permitiendo que el modelo comprenda la evolución temporal de las características extraídas." - Alan Sastre, CEO, CertiDevs
Las variantes LSTM (Long Short-Term Memory) y GRU (Gated Recurrent Units) son especialmente útiles porque solucionan problemas como el desvanecimiento del gradiente, lo que les permite "recordar" información clave de transacciones anteriores. Esto hace que las RNN sean herramientas indispensables para capturar dinámicas temporales en los datos.
Una arquitectura híbrida combina las fortalezas de ambas tecnologías: las CNN extraen características detalladas de cada transacción, mientras que las RNN analizan cómo estas características evolucionan con el tiempo. Este enfoque permite procesar simultáneamente información espacial y temporal, lo que resulta en modelos más efectivos para detectar fraudes.
"La combinación de CNN y RNN permite el procesamiento simultáneo de información espacial y secuencial... resultando en un modelo robusto para tareas complejas." - CertiDevs
Gracias a esta integración, los modelos pueden alcanzar niveles de precisión impresionantes, con hasta un 99,4% de precisión y 99,9% de recall en conjuntos de datos estándar. Además, esta metodología no solo mejora la exactitud, sino que también permite tomar decisiones en tiempo real para prevenir fraudes de manera más eficiente.
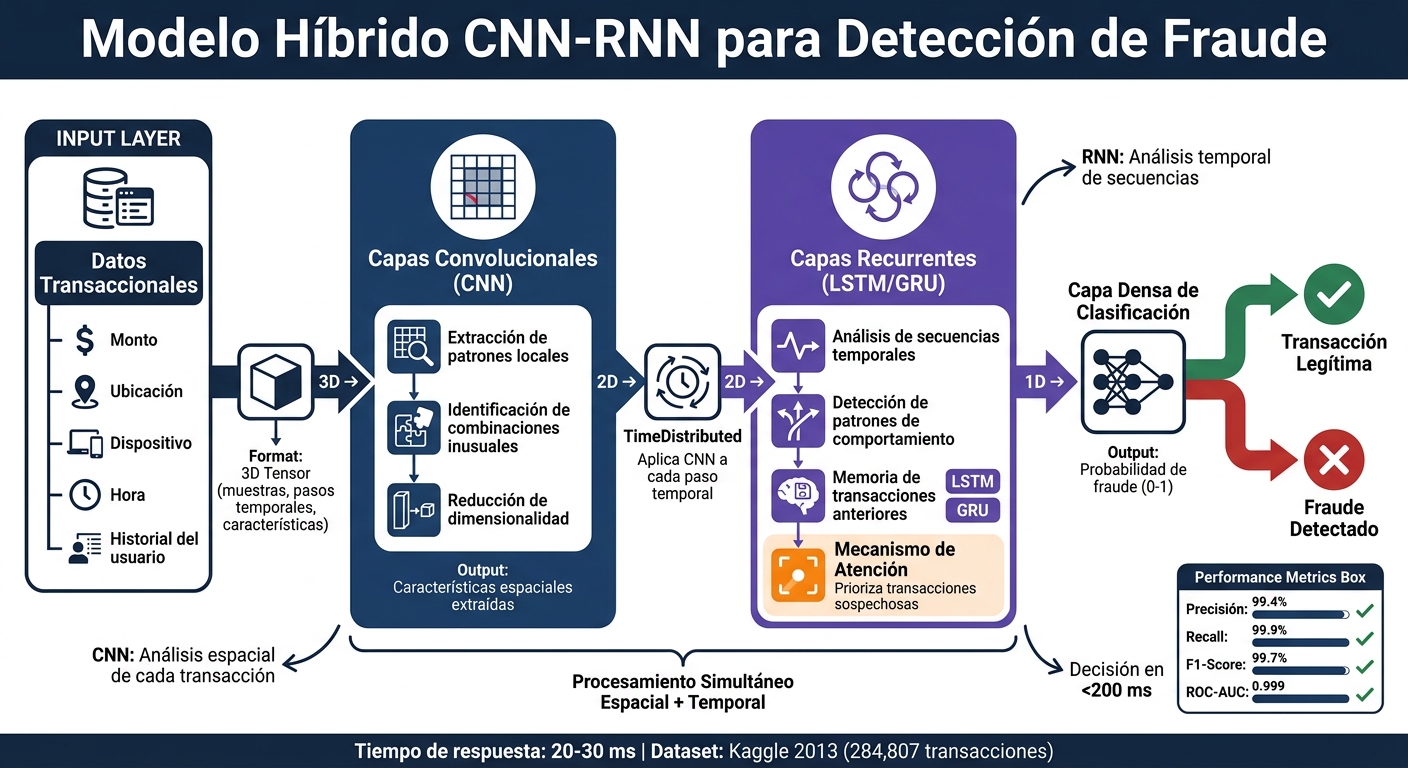
Arquitectura y flujo de datos del modelo híbrido CNN-RNN para detección de fraude
El proceso comienza cuando los datos transaccionales ingresan a las capas convolucionales (CNN), que se encargan de filtrar y extraer patrones espaciales y características locales de cada transacción. Estas capas también ayudan a reducir la dimensionalidad de los datos, facilitando su preparación para las RNN.
Luego, las RNN (como LSTM o GRU) analizan cómo evolucionan las características a lo largo del tiempo. En herramientas como Keras, se utilizan capas TimeDistributed para aplicar las operaciones de las CNN a cada paso temporal dentro de una secuencia de transacciones. Esto permite detectar tanto patrones individuales como tendencias temporales, integrando ambos aspectos en un flujo continuo que define la base del modelo híbrido.
La arquitectura híbrida incluye varios componentes clave. Las unidades LSTM o BiLSTM son esenciales para captar dependencias a largo plazo en las secuencias de comportamiento de los usuarios. Estas unidades ayudan a retener información importante, lo que permite identificar cambios sutiles en los patrones de compra.
Además, los mecanismos de atención se colocan entre las capas RNN y la capa final de clasificación. Su función es destacar las transacciones más sospechosas dentro de una secuencia larga, priorizando aquellas con mayor probabilidad de fraude. Finalmente, la capa densa toma toda esta información procesada y genera un valor que representa la probabilidad de fraude.
Antes de alimentar los datos al modelo, es fundamental realizar un preprocesamiento adecuado para optimizar la detección de patrones. Una de las primeras tareas es reformatear los datos en tensores 3D con la estructura (muestras, pasos temporales, características). Este formato es indispensable para que las RNN procesen la información secuencialmente de forma correcta, alineándose con el flujo de datos descrito anteriormente.
Otro paso crucial es la normalización de las variables. Esto asegura que todas las características tengan escalas comparables, evitando que variables con rangos más amplios, como los montos en pesos argentinos, influyan desproporcionadamente en el aprendizaje del modelo. Este enfoque garantiza que el modelo pueda analizar todos los datos de manera equilibrada.
En septiembre de 2025, un grupo de investigadores de la Universidad de Diyala - Zainab Hassan Mohammed, Nebras Jalel Ibrahim y Ahmed K. Abbas - implementó un modelo híbrido CNN-LSTM utilizando el dataset de transacciones con tarjetas de crédito europeas de Kaggle (2013). Los resultados fueron impresionantes: una precisión del 99,4%, un recall del 99,9%, un F1-score del 99,7% y un ROC-AUC de 0,999. La clave de este éxito fue el uso de SMOTE combinado con la arquitectura híbrida CNN-LSTM, que superó ampliamente a los modelos tradicionales. Ahora, veamos cómo estos números se reflejan en escenarios prácticos.
El dataset de Kaggle incluye transacciones reales de tarjetahabientes europeos y representa un desafío clásico: un fuerte desbalance de clases, ya que las transacciones fraudulentas constituyen menos del 0,2% del total. Al aplicar el modelo híbrido CNN-LSTM junto con SMOTE, se logró identificar casi todos los casos de fraude, al mismo tiempo que se minimizaron los falsos positivos. Esto evidencia que esta arquitectura híbrida puede ser utilizada eficazmente en contextos reales.
"The hybrid model's CNN front-end is effective in extracting local transaction patterns, while RNN layers model sequential dependencies within transaction sequences."
– Zainab Hassan Mohammed, University of Diyala
La comparación con otras metodologías resalta la superioridad del modelo híbrido. Esta arquitectura combina la capacidad de las CNN para extraer patrones espaciales con la habilidad de las LSTM para modelar dependencias temporales. Además, las CNN permiten una mejor paralelización que las LSTM puras, lo que reduce el uso de memoria y mejora la eficiencia en sistemas con alto volumen de transacciones.
| Tipo de modelo | Precisión | Recall | F1-Score | ROC-AUC |
|---|---|---|---|---|
| Híbrido CNN-RNN (LSTM) | 99,4% | 99,9% | 99,7% | 0,999 |
| ML tradicional (Random Forest/XGBoost) | Inferior | Inferior | Inferior | Inferior |
(Fuente:)
Para aprovechar la capacidad de identificar patrones espaciales y temporales, sigue estos pasos prácticos para implementar el modelo híbrido CNN-RNN.
Comienza descargando un dataset de transacciones reales. El conjunto de datos de tarjetahabientes europeos de 2013, disponible en Kaggle, es una opción popular. Contiene 284.807 transacciones, de las cuales solo el 0,2% son fraudulentas, reflejando el desafío del desbalance de clases.
Prepara y limpia los datos siguiendo estos pasos:
Una vez que tengas un dataset balanceado y preprocesado, estarás listo para construir y entrenar tu modelo híbrido.
Usa herramientas como TensorFlow o Keras para construir la arquitectura híbrida en Python. Comienza con capas CNN para identificar patrones locales en los datos, seguidas de capas LSTM que capturen relaciones temporales. Configura el modelo con una función de pérdida adecuada para clasificación binaria, como binary crossentropy, y utiliza optimizadores como Adam.
Durante el entrenamiento, ajusta los siguientes hiperparámetros:
Monitorea métricas clave como precisión, recall y F1-score. Con el dataset de Kaggle y técnicas de balanceo, se han logrado resultados impresionantes: una precisión del 99,4% y un recall del 99,9%. Una vez que el modelo alcance estas métricas, estarás listo para desplegarlo.
Después de entrenar el modelo, el siguiente paso es integrarlo en sistemas de comercio electrónico para operar en tiempo real. Configura APIs que envíen datos de cada transacción al modelo, asegurando respuestas en 20 a 30 ms, dentro de una ventana total de autorización de aproximadamente 200 ms.
Antes de pasar a producción, utiliza un enfoque de "modo sombra". Esto significa que el modelo procesa las transacciones en paralelo al sistema actual, pero sin influir en las decisiones reales. Así podrás evaluar su rendimiento y detectar posibles problemas.
Implementa feature flags para desactivar variables específicas o revertir a versiones anteriores en caso de ataques o fallos, sin necesidad de redesplegar código. Además, prioriza el uso de datos internos, como el historial de transacciones y el comportamiento del usuario, sobre APIs externas que podrían causar retrasos.
Finalmente, configura un sistema human-in-the-loop que derive casos ambiguos a analistas humanos. Sus decisiones no solo resolverán esos casos, sino que también servirán como datos para mejorar continuamente el modelo mediante reentrenamiento.
Los modelos híbridos CNN-RNN han demostrado ser herramientas muy eficaces en la detección de fraudes, ofreciendo resultados que superan ampliamente los métodos tradicionales. Uno de sus puntos fuertes es su precisión, que no solo mejora la detección, sino que también reduce la generación de falsos positivos, algo crucial en entornos reales. Además, destacan por su capacidad de trabajar con conjuntos de datos muy desequilibrados, logrando identificar fraudes incluso cuando representan una mínima porción del total. Este enfoque no solo protege contra actividades fraudulentas, sino que también asegura que la experiencia del usuario no se vea afectada negativamente.
Sin embargo, estos modelos no están exentos de desafíos. Uno de los principales es el alto costo computacional que implica su entrenamiento. Configurar y entrenar un modelo híbrido CNN-RNN puede requerir GPUs de alto rendimiento y un tiempo considerable, que puede variar entre varias horas y días, dependiendo del volumen de datos. Esto implica una inversión inicial significativa tanto en infraestructura como en consumo energético. Por otro lado, la implementación de estos sistemas es compleja, desde el diseño de la arquitectura hasta el ajuste de los hiperparámetros, lo que demanda conocimientos avanzados en deep learning. Además, el éxito de estos modelos depende en gran medida de la disponibilidad de grandes volúmenes de datos etiquetados, lo que puede ser un obstáculo en algunos casos.
A medida que las técnicas fraudulentas evolucionan, también lo hacen las estrategias para combatirlas. Aunque los modelos híbridos CNN-RNN ya han logrado resultados muy sólidos, la investigación se centra ahora en hacerlos más rápidos y adaptables. La optimización de estos sistemas busca no solo mantener su eficacia frente a nuevos patrones de fraude, sino también reducir los recursos necesarios para su implementación y operación. Este enfoque promete mantener a la tecnología a la vanguardia en un entorno donde las amenazas son cada vez más sofisticadas y dinámicas.
Al analizar el rendimiento y la funcionalidad de los modelos híbridos CNN-RNN, queda claro que representan un gran paso adelante en la detección de fraude en el comercio electrónico. Al combinar la capacidad de las CNN para identificar patrones locales con la habilidad de las RNN (específicamente LSTM) para entender dependencias secuenciales, estos modelos logran métricas impresionantes: precisión del 99,4%, recall del 99,9% y F1-score del 99,7%. Esto los posiciona por encima de los métodos tradicionales en términos de efectividad.
Estos sistemas híbridos enfrentan con éxito los principales desafíos del fraude, como la detección en tiempo real, el desbalance de datos y la reducción de falsos positivos. Para las empresas de comercio electrónico, se recomienda implementar una arquitectura que utilice una CNN para la extracción de características en el front-end, complementada con capas RNN o LSTM para analizar las secuencias de acciones de los usuarios.
Además, es crucial abordar el desbalance de datos mediante técnicas como SMOTE (Synthetic Minority Over-sampling Technique). Esto asegura que el modelo pueda entrenarse adecuadamente, incluso cuando las transacciones fraudulentas representan solo una pequeña fracción del total.
En un escenario donde las pérdidas financieras por fraude siguen en aumento, estos modelos ofrecen una solución sólida y escalable para proteger las operaciones en plataformas de comercio electrónico.
Para que una Red Neuronal Recurrente (RNN) sea efectiva en la detección de fraude, es fundamental contar con datos que reflejen comportamientos secuenciales del usuario, organizados de manera cronológica. Esto incluye información como transacciones, sesiones, patrones de compra o incluso cambios en el comportamiento habitual.
Además, otros datos como ubicación geográfica, tipo de dispositivo utilizado o hábitos específicos del usuario también son valiosos. Estos ayudan a identificar patrones que se desvían de lo esperado. Para aprovechar al máximo esta información, es esencial estructurarla en secuencias temporales relevantes, lo que permite que el modelo detecte anomalías con mayor precisión.
Para lograr un balance entre precisión y sensibilidad en tu modelo, es clave ajustar varios factores. Una estrategia eficaz es trabajar en el balanceo de clases. Técnicas como SMOTE (Synthetic Minority Over-sampling Technique) pueden ayudarte a equilibrar los datos y mejorar la detección de fraudes reales, especialmente en conjuntos de datos desbalanceados.
Otra táctica importante es optimizar los umbrales de decisión. Ajustar estos umbrales te permitirá encontrar un punto de equilibrio adecuado entre falsos positivos y verdaderos positivos. Para identificar ese punto óptimo, analizá la curva Precision-Recall, que es especialmente útil en problemas donde las clases están desbalanceadas.
Por último, considerar modelos híbridos como los CNN-RNN puede marcar la diferencia. Estos modelos combinan la capacidad de las redes neuronales convolucionales para identificar patrones locales con la habilidad de las redes recurrentes para procesar información secuencial. Esto permite captar patrones más complejos y, a su vez, lograr un mejor equilibrio entre precisión y recall.
Si buscas tiempos de respuesta ultrarrápidos, hay dos pilares clave: optimizar el uso de características relevantes y usar modelos de aprendizaje profundo eficientes. Herramientas como las redes neuronales convolucionales (CNN) y las redes neuronales recurrentes (RNN) destacan por su capacidad para procesar datos de forma veloz y precisa.
Pero no todo depende del software. También es fundamental contar con una infraestructura de hardware adecuada. Esto ayuda a reducir la latencia y asegura que los tiempos de procesamiento se mantengan dentro de los límites necesarios. En resumen, es un trabajo en equipo entre tecnología y recursos.