
Cuando un e-commerce crece, las integraciones de análisis enfrentan problemas que complican la consistencia y confiabilidad de los datos. Estos desafíos no solo afectan la calidad de los reportes, sino también la toma de decisiones estratégicas. Los principales obstáculos incluyen:
Estos problemas se intensifican con el crecimiento y la diversificación de plataformas. La clave está en implementar procesos claros, herramientas en tiempo real y un enfoque centralizado para la gestión de datos. Sin esto, la escalabilidad puede convertirse en un caos operativo.
Al principio, conectar un par de herramientas parece algo sencillo. Sin embargo, cuando un e-commerce empieza a sumar más canales - como redes sociales, plataformas de email, sistemas logísticos o pasarelas de pago - , las fuentes de datos se multiplican rápidamente. Esto no solo aumenta la cantidad de información, sino que también exige una coordinación más precisa para mantener la coherencia de los datos.
El verdadero desafío no radica únicamente en la cantidad de datos, sino en su diversidad. Cada plataforma exporta información en formatos distintos como CSV, JSON o XML, y utiliza estructuras de API únicas. A medida que el negocio crece, esta variedad requiere ajustes constantes, que sin una documentación adecuada pueden convertirse en un auténtico caos. Aquí es donde aparece el conocido problema de "Garbage In, Garbage Out" (GIGO): si los datos de entrada son inconsistentes o incorrectos, los resultados del análisis no serán fiables.
"El mayor desafío de la integración de datos es, sin dudas, tener que lidiar con datos provenientes de diversas fuentes... La incompatibilidad de todos estos formatos, fuentes y esquemas puede dificultar la combinación de información de manera coherente." - Keyrus
Un ejemplo claro de esto es cómo las inconsistencias en los esquemas de datos pueden afectar los resultados. Por ejemplo, un número de teléfono almacenado en formato nacional en un sistema y en formato internacional en otro puede generar duplicaciones y errores en los informes.
El problema se agrava porque las fuentes de datos no son estáticas. Las plataformas suelen actualizar sus estructuras, agregar nuevos campos o eliminar otros. Esto obliga a una constante adaptación para mantener la consistencia. Si estos cambios no se detectan a tiempo, pueden comprometer la integridad del flujo de datos, haciendo que la escalabilidad sea aún más compleja y aumentando los retos que se detallan en las siguientes secciones.
En un e-commerce en expansión, es común que cada sistema maneje a los clientes de forma distinta: el ERP utiliza un ID numérico, el CRM los identifica por email y el área de marketing los clasifica por teléfono. Estas diferencias generan duplicados y métricas inconsistentes, lo que distorsiona indicadores clave como el LTV (valor de vida del cliente) y la tasa de recompra. Esto, a su vez, impacta negativamente en las decisiones estratégicas y en la efectividad de las campañas.
"Si tu e-commerce, tu ERP, tu CRM y tus herramientas de marketing no comparten la misma 'verdad', lo vas a sentir en todos lados: reportes que no cierran, clientes duplicados e inventarios desincronizados." - Weavee
Este comentario ilustra perfectamente el caos que surge cuando no existe una única fuente confiable de datos. El problema principal radica en la ausencia de un sistema maestro que sirva como referencia. Sin una base común para cada tipo de dato - como usar el ERP para inventarios y el CRM para clientes - , cada área opera bajo su propia versión de la información. Esto genera barreras entre equipos como Ventas, Marketing y Logística, haciendo que los reportes consolidados sean poco fiables.
Para evitar esta fragmentación, es fundamental mapear los campos de datos en cada integración y establecer procesos de resolución de entidades. Por ejemplo, unificar registros que puedan variar levemente, como "J. Pérez" y "Juan Pérez". Sin esta estructura básica, cualquier intento de escalar las integraciones solo multiplicará el desorden.
La diversidad de métodos de autenticación puede ser un verdadero desafío, especialmente en un ecosistema empresarial donde el uso de múltiples plataformas es la norma. Con el auge del e-commerce, no es raro que una empresa mediana utilice entre 12 y 25 aplicaciones diferentes, como CRM, ERP, herramientas de análisis y plataformas de marketing. Cada una de estas herramientas tiene sus propias credenciales, tokens y protocolos de seguridad, lo que hace que la gestión manual de estas credenciales sea prácticamente imposible.
El problema no se limita a la cantidad de contraseñas, sino que también incluye la variedad de protocolos que se deben manejar, como API keys, OAuth 2.0 y firmas HMAC. Esto obliga a los equipos técnicos a implementar diferentes métodos de autenticación para cada conector, aumentando los puntos vulnerables en el sistema.
"Cada actualización de API puede romper el conector." - Kacinka
La fragilidad de las integraciones punto a punto se vuelve especialmente evidente cuando una actualización de protocolo interrumpe un conector. En estos casos, la sincronización de datos queda paralizada hasta que se implementa una solución manual, lo que puede resultar en horas de inactividad. En un entorno de alta demanda, estas interrupciones no solo afectan la operación, sino que también generan costos significativos.
Además, el cumplimiento de regulaciones como el RGPD o la CCPA añade otro nivel de complejidad. Estas normativas exigen trazabilidad total sobre el flujo de datos y credenciales entre sistemas. Sin una gestión centralizada del acceso, demostrar el cumplimiento de estas leyes puede convertirse en una tarea monumental.
Una solución eficaz es adoptar una arquitectura hub-and-spoke, que permite centralizar la gestión de credenciales. Este modelo reduce las conexiones de N×(N-1)/2 a N, simplificando tanto el mantenimiento como el control del acceso.
Cuando una marca crece, también lo hacen las llamadas a las APIs de análisis. El problema es que muchas plataformas imponen límites en la cantidad de solicitudes permitidas en un período determinado. Si se supera ese límite, el sistema devuelve un error 429 (Too Many Requests), y los datos dejan de procesarse hasta que el sistema se estabiliza.
Un ejemplo claro es la API REST Admin de Shopify, que permite un máximo de 40 solicitudes con una tasa de "vaciado" de 2 solicitudes por segundo. Para una tienda con un alto volumen de pedidos, como en eventos de gran demanda tipo Hot Sale o Black Friday, este límite se alcanza rápidamente.
No todas las APIs funcionan de la misma manera. Las APIs REST cuentan cada solicitud de manera individual, mientras que GraphQL utiliza un sistema basado en puntos - por ejemplo, 50 puntos por segundo - donde las consultas más complejas consumen más recursos, y los puntos no utilizados solo se recuperan al finalizar la ejecución. Esto obliga a los equipos técnicos a comprender ambas metodologías y ajustar sus integraciones en consecuencia.
Para evitar la pérdida de datos o saturar el sistema, se suelen implementar estrategias como el exponential backoff (reintentos con intervalos crecientes), el procesamiento por lotes o el cacheo de resultados frecuentes. Estas estrategias, aplicadas de manera adecuada, se resumen en la siguiente tabla:
| Método de sincronización | Frecuencia recomendada | Caso de uso ideal |
|---|---|---|
| Webhooks | Tiempo real (por evento) | Ventas de alto volumen, actualizaciones de inventario |
| Sincronización periódica | Cada 15–30 minutos | Tráfico medio, atributos personalizados |
| Actualización diaria | Cada 24 horas (fuera de horario pico) | Correcciones base, auditorías, datos de baja prioridad |
| Manual / forzada | Según necesidad | Restauración total del catálogo, resolución de errores |
Esta clasificación ayuda a ajustar la sincronización según las necesidades y la naturaleza de los datos. Un manejo inadecuado de estos límites puede afectar la precisión de los reportes y, en consecuencia, la calidad de las decisiones empresariales basadas en ellos.
Los webhooks son fundamentales para recibir datos en tiempo real desde plataformas como Shopify o Amazon. Sin embargo, su entrega no está garantizada: si el servidor que los recibe está inactivo o saturado, el evento puede perderse o llegar con retraso. Por ejemplo, Shopify reintenta enviar un webhook fallido hasta 19 veces dentro de un período de 48 horas. En el caso de Amazon SP-API, este plazo se extiende hasta 3 días. Durante esos intervalos, los análisis reflejan datos incompletos, lo que complica aún más la gestión al escalar los sistemas de análisis.
Además de los tiempos de reintento, la idempotencia juega un papel clave en la sincronización. Los webhooks suelen operar bajo un esquema de "al menos una vez", lo que implica que un mismo evento puede recibirse más de una vez. Si el sistema no está diseñado para manejar duplicados, pueden surgir problemas como conteos dobles de ventas, errores en el inventario o métricas incorrectas. Por ejemplo, un vendedor que procesa 500 pedidos diarios podría enfrentar pérdidas de hasta USD 70.000 al año si tiene una tasa de fallas de sincronización del 1%.
Estas fallas también generan costos operativos adicionales, ya que el equipo técnico debe revisar manualmente los registros, cotejar datos y corregir errores. Esto se agrava porque la tasa de error en la carga manual de datos varía entre el 1% y el 4% por campo, lo que puede introducir más problemas en lugar de solucionarlos.
"La recomendación para producción es híbrida. Usá webhooks para actualizaciones en tiempo real y polling para reconciliaciones periódicas. Esto te da la velocidad de la arquitectura orientada a eventos con la confiabilidad de la verificación programada." - Equipo de Investigación y Desarrollo de ECOSIRE
Una estrategia sólida combina el uso de webhooks como disparadores principales con un proceso de polling periódico cada 6 a 12 horas para identificar eventos que se hayan perdido. Además, implementar una Dead Letter Queue (DLQ), una cola que almacena eventos fallidos tras múltiples reintentos, permite detectar problemas de mapeo o cambios en la API sin interrumpir el flujo general de datos. Este enfoque, junto con medidas para garantizar la integridad de los datos, es esencial para escalar de manera efectiva las integraciones analíticas.
Uno de los grandes desafíos en la integración de datos es la latencia. Aunque los webhooks funcionen correctamente, hay un problema menos evidente pero crítico: el tiempo que transcurre entre un evento y la disponibilidad de los datos para tomar decisiones. Este desfase, que puede parecer insignificante al principio, se convierte en un obstáculo serio al escalar operaciones.
En el mundo del e-commerce, una demora de apenas 24 a 48 horas puede ser desastrosa. Por ejemplo, una campaña publicitaria podría seguir activa cuando ya no tiene sentido, o un producto podría aparecer como disponible cuando en realidad está agotado. Esto ocurre porque muchas herramientas estándar trabajan con procesamiento por lotes (batch processing), lo que introduce retrasos inevitables al esperar que se complete un ciclo de datos antes de procesarlos.
La situación se complica aún más cuando se manejan múltiples fuentes de datos con diferentes formatos y ritmos de actualización. Sensores IoT, redes sociales, aplicaciones móviles y sistemas antiguos, cada uno con su propio estándar (CSV, JSON, XML), generan una diversidad que aumenta el riesgo de reportar información desactualizada. En resumen, cuanto mayor sea la cantidad de fuentes integradas, mayor será la posibilidad de que los datos no reflejen la realidad en tiempo real.
| Problema frecuente | Causa probable | Solución recomendada |
|---|---|---|
| Datos faltantes en reportes | Límites de API o retrasos en sincronización | Programar reportes con un margen de 1-2 horas tras el cierre del período |
| Quiebres de stock o sobrestock | Falta de sincronización en tiempo real entre ERP y tienda | Implementar integraciones API en tiempo real |
| Analytics inexactos | Procesamiento retrasado (24-48 horas) | Migrar a herramientas avanzadas o usar tracking server-side |
Para las marcas que operan en un entorno omnicanal, como los servicios de Click and Collect, la latencia puede ser especialmente costosa. En estos casos, la sincronización entre el inventario físico y la plataforma online debe ser impecable. Un error en los datos puede resultar en una venta confirmada de un producto que ya no está disponible en el depósito, generando una mala experiencia para el cliente.
La mejor forma de abordar este problema es adoptar herramientas que permitan el procesamiento en tiempo real. Tecnologías como Apache Kafka o Apache Flink son excelentes opciones, ya que permiten integrar y analizar datos a medida que se generan. Aunque estas soluciones no eliminan la complejidad inherente a la integración de múltiples fuentes, sí reducen significativamente el tiempo entre el evento y la acción, mejorando la capacidad de respuesta de las empresas.
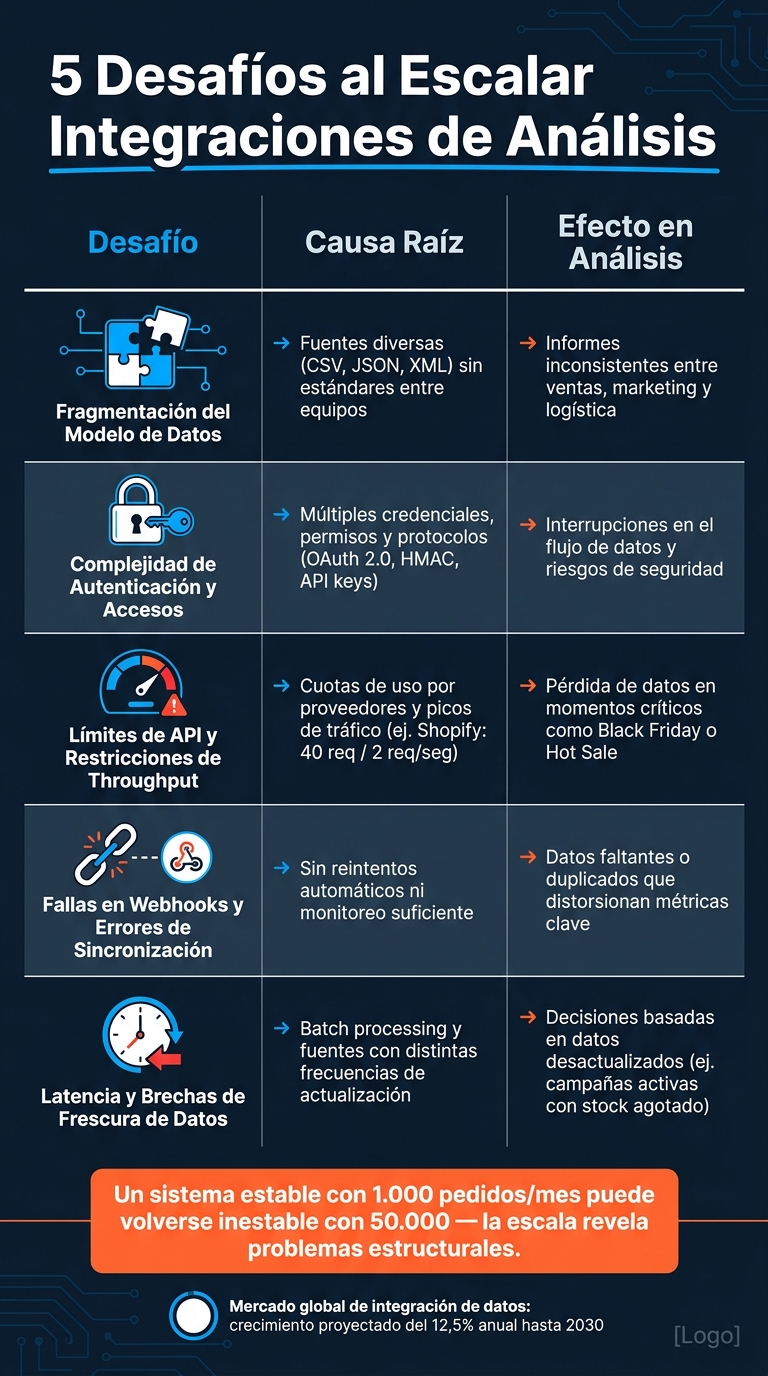
5 Desafíos al Escalar Integraciones de Análisis en E-commerce
Este cuadro sintetiza los puntos clave de los principales obstáculos analizados, ofreciendo una visión clara de sus causas y cómo afectan el análisis de datos en operaciones en expansión.
| Desafío | Causa principal | Efecto en el análisis |
|---|---|---|
| Fragmentación del modelo de datos | Uso de fuentes diversas (bases de datos, CSV, JSON, XML) y falta de estándares entre equipos | Informes inconsistentes y datos incompatibles entre áreas como ventas, marketing y logística |
| Complejidad de autenticación y accesos | Sistemas con diferentes credenciales, permisos y protocolos | interrupciones en el flujo de datos y riesgos de seguridad que requieren depurar problemas de integración API en sistemas clave |
| Límites de API y restricciones de throughput | Cuotas de uso impuestas por proveedores y picos de tráfico inesperados | Pérdida de datos en momentos críticos, como campañas o lanzamientos |
| Fallas en webhooks y errores de sincronización | Ausencia de reintentos automáticos y monitoreo insuficiente | Datos faltantes o duplicados que alteran métricas y decisiones |
| Latencia y brechas de frescura de datos | Procesos por lotes (batch processing) y fuentes con diferentes frecuencias de actualización | Decisiones basadas en información desactualizada, como campañas activas con productos sin stock |
Estos desafíos no surgen de un día para otro; se intensifican con el crecimiento. Un sistema que soporta 1.000 pedidos al mes puede volverse inestable con 50.000, no por fallas tecnológicas, sino porque la escala revela problemas estructurales que antes pasaban desapercibidos.
Los problemas al escalar integraciones de análisis no suelen surgir por fallas tecnológicas, sino por no prever obstáculos estructurales a tiempo. A medida que una empresa crece, cuestiones como la fragmentación de datos, la complejidad en la autenticación, los límites de API, las fallas en webhooks y la latencia tienden a agravarse. Abordarlos antes de que se conviertan en un problema mayor puede marcar una gran diferencia.
Contar con datos en tiempo real es fundamental. Estos permiten, por ejemplo, ajustar una campaña mientras está en curso, detectar un producto agotado antes de seguir vendiéndolo o analizar el comportamiento de los clientes justo cuando más importa. Tomar decisiones basándose en datos desactualizados es como actuar con los ojos vendados.
Una solución práctica es designar un "data owner" dentro del equipo, es decir, una persona o área encargada de garantizar la calidad y estandarización de los datos. Sin esta figura, cada departamento puede terminar trabajando con su propia versión de la realidad, lo que genera inconsistencias y errores. Asumir esta responsabilidad puede convertir desafíos en oportunidades concretas.
El mercado global de integración de datos está creciendo a un ritmo anual del 12,5% proyectado hasta 2030. Esto demuestra que cada vez más organizaciones están invirtiendo en soluciones para estos problemas. Como se observa en los datos comparativos, las marcas que actúen de manera preventiva frente a estos retos tendrán una ventaja clara sobre aquellas que esperan hasta que el desorden las obligue a reaccionar.
Para establecer una fuente de verdad, es clave implementar un sistema centralizado que funcione como el único punto de referencia confiable para toda la organización. Este sistema puede ser un ERP o un CRM, y debe estar configurado para sincronizarse en tiempo real con todas las herramientas y sistemas utilizados. Esto ayuda a eliminar errores, duplicados y discrepancias, lo que mejora los procesos internos, facilita una toma de decisiones más precisa y eleva la calidad de la experiencia del cliente.
Los errores 429 pueden ser un dolor de cabeza, pero hay formas efectivas de evitarlos y proteger tus datos. Una estrategia clave es implementar rate limiting, que básicamente consiste en espaciar las solicitudes en intervalos específicos para no saturar el sistema.
Otra técnica útil es configurar reintentos con una espera exponencial. Esto significa que, si una solicitud falla, el sistema espera un poco antes de intentarlo de nuevo, aumentando gradualmente el tiempo entre intentos. Así se reduce la probabilidad de seguir recibiendo errores.
También es buena idea optimizar las consultas dividiendo los datos en lotes más pequeños. Esto no solo disminuye la carga en el sistema, sino que también hace que el proceso sea más manejable.
Por último, el uso de herramientas con sincronización en tiempo real y procesos automatizados puede marcar una gran diferencia. Estas soluciones permiten mantener los datos actualizados sin exceder los límites establecidos, garantizando así la integridad de la información.
Para disminuir la latencia sin comprometer el funcionamiento de los webhooks, es clave ajustar la frecuencia y el volumen de las llamadas a la API. Concentrate en priorizar las operaciones más importantes y, siempre que sea posible, agrupá las solicitudes para procesarlas de manera más eficiente. También es útil implementar sistemas de caché que eviten consultas innecesarias o repetitivas.
Además, mantené un monitoreo constante de la latencia y los límites de tasa de la API. Esto te permitirá realizar ajustes en las configuraciones según sea necesario. Con estas prácticas, podés garantizar que los webhooks se reciban en tiempo real, optimizando al mismo tiempo la eficiencia de las integraciones.