
La detección de fraude enfrenta un desafío crítico: el desbalance extremo en los datos, donde las transacciones fraudulentas representan menos del 1%. Este problema puede llevar a modelos que ignoran patrones de fraude, favoreciendo las transacciones legítimas. Por eso, la selección de características es clave para mejorar el rendimiento y la eficiencia de los modelos.
Puntos principales:
Métodos destacados:
Ejemplos reales:
En resumen, priorizar características relevantes no solo mejora la detección de fraude, sino que también hace que los modelos sean más rápidos y fáciles de interpretar.
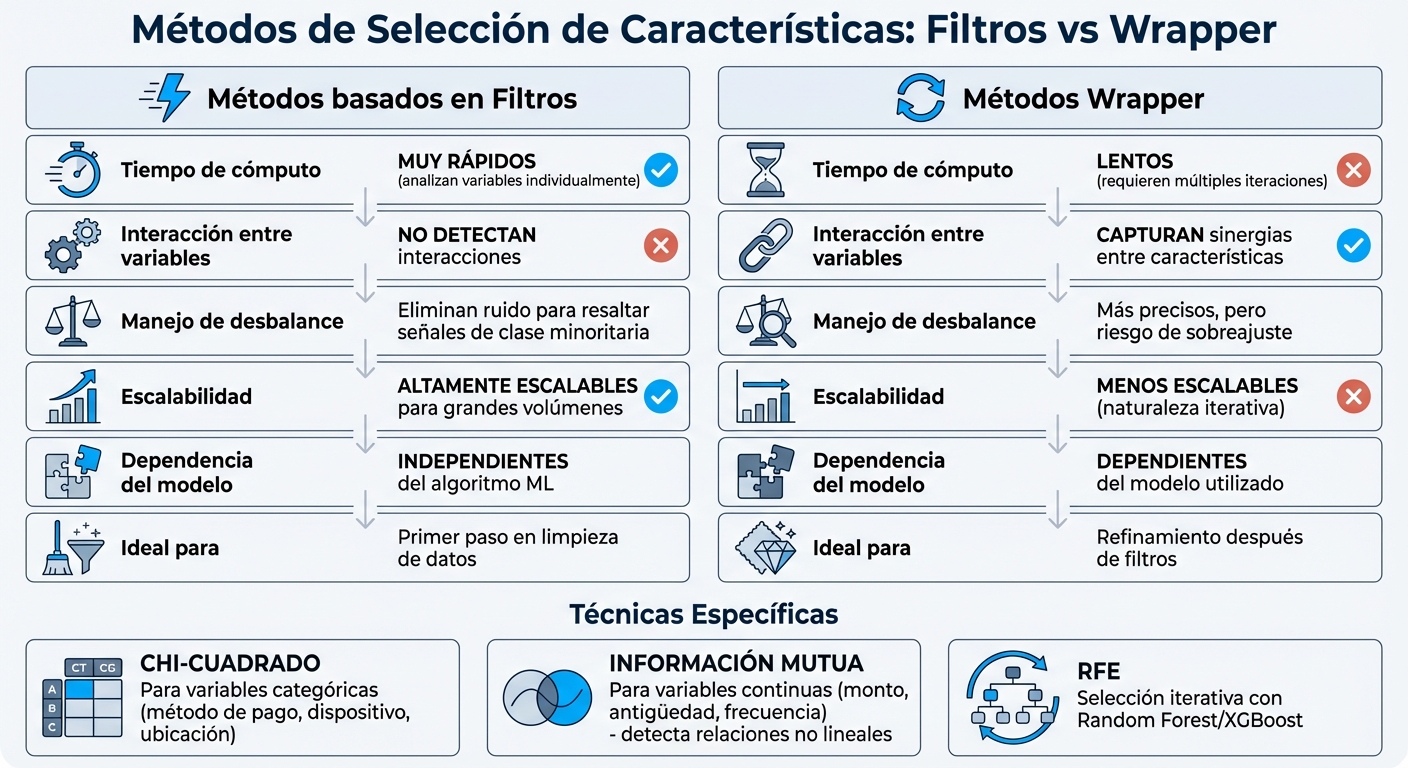
Comparación de métodos de selección de características para detección de fraude
Los métodos basados en filtros analizan cada característica de forma individual, evaluando su relevancia sin tener en cuenta las combinaciones o interacciones entre ellas. En el ámbito de la detección de fraude, resultan útiles para descartar rápidamente variables irrelevantes, enfocándose en aquellas que aportan señales críticas, incluso cuando los datos están marcadamente desbalanceados. , especialmente relevante en conjuntos de datos masivos con miles de variables y millones de registros.
Estos métodos asignan un puntaje de relevancia a cada variable, lo que permite eliminar aquellas con puntuaciones bajas antes de entrenar el modelo. A diferencia de los métodos wrapper, que requieren múltiples iteraciones del modelo, los filtros son independientes del algoritmo de machine learning utilizado, convirtiéndolos en una opción ideal para reducir la dimensionalidad en las primeras etapas. Sin embargo, tienen una limitación importante: no detectan interacciones entre variables, lo que podría llevar a descartar características que, en combinación, serían útiles.
El test de Chi-Cuadrado (chi2) mide la dependencia entre variables categóricas y el objetivo. En la detección de fraude, es especialmente eficaz para analizar predictores como el método de pago, tipo de dispositivo o ubicación geográfica. Este análisis identifica qué categorías tienen una relación estadísticamente significativa con el comportamiento fraudulento.
Es importante que las características sean no negativas antes de aplicar Chi-Cuadrado, ya que esto es un requisito del cálculo. Además, cuando se trabaja con datos desbalanceados, las técnicas de resampling (como SMOTE o undersampling) deben aplicarse únicamente al conjunto de entrenamiento, evitando alterar el conjunto de prueba para garantizar una evaluación precisa.
La Información Mutua (mutual_info_classif) mide cualquier tipo de dependencia - incluyendo relaciones no lineales - entre las variables y el objetivo. Este método es particularmente útil para detectar relaciones complejas entre características continuas, como el monto de la transacción, la antigüedad de la cuenta o la frecuencia de uso, y el fraude.
A diferencia de los F-tests (f_classif), que solo detectan dependencia lineal, la Información Mutua puede identificar relaciones más complejas. Sin embargo, requiere un mayor número de muestras para ofrecer resultados confiables. Si sospechás que existen relaciones no lineales entre las características de las transacciones y el fraude, y tenés un conjunto de datos lo suficientemente amplio, este método es una opción potente.
| Característica | Métodos basados en filtros | Métodos wrapper |
|---|---|---|
| Tiempo de cómputo | Muy rápidos; analizan variables individualmente | Lentos; requieren múltiples iteraciones del modelo |
| Interacción entre variables | No detectan interacciones | Capturan sinergias entre características |
| Manejo de desbalance | Eliminan ruido para resaltar señales de la clase minoritaria | Más precisos, pero con riesgo de sobreajuste en clases pequeñas |
| Escalabilidad | Altamente escalables para grandes volúmenes de datos | Menos escalables por su naturaleza iterativa |
| Dependencia del modelo | Independientes del algoritmo de machine learning | Dependientes del modelo utilizado |
Los métodos basados en filtros son ideales como primer paso en el proceso de limpieza, permitiendo reducir el volumen de datos antes de aplicar técnicas wrapper, que son más costosas en términos de tiempo y recursos computacionales. Esto resulta clave en sistemas que deben procesar miles de transacciones por segundo.
Después de explorar los métodos basados en filtros, es momento de enfocarnos en RFE, una técnica que perfecciona la selección de características en modelos desbalanceados. A diferencia de los métodos de filtro, RFE (Recursive Feature Elimination) es un enfoque que trabaja en conjunto con un modelo de machine learning específico. Su funcionamiento es iterativo: entrena el modelo, elimina las variables menos útiles y repite el proceso hasta quedarse con un subconjunto óptimo.
En el ámbito de la detección de fraude, donde los datos suelen ser complejos y desbalanceados, RFE destaca por identificar las características que mejor diferencian la clase minoritaria. Este proceso no solo elimina redundancias y colinealidades, sino que también reduce el ruido, mejorando la capacidad del modelo para generalizar. Además, existe una variante llamada RFECV que automatiza el proceso, seleccionando las características esenciales y eliminando aquellas que no aportan valor.
Los modelos basados en árboles, como Random Forest y XGBoost, son ideales para RFE porque incluyen el atributo feature_importances_ durante el entrenamiento. Este atributo mide la relevancia de cada variable según criterios como Gini o entropía, lo que permite a RFE priorizar y descartar variables de manera efectiva.
En escenarios de fraude, es clave configurar el modelo con class_weight='balanced' para manejar el desbalance de clases y usar StratifiedKFold para mantener la proporción de clases durante la validación. Además, ajustar el parámetro step para eliminar varias variables por iteración puede acelerar significativamente el proceso.
Por ejemplo, en un caso de clasificación de incumplimiento crediticio - similar a la detección de fraude - , se encontró que el F1-score se estabilizó al seleccionar solo 5 características, aunque inicialmente el algoritmo identificó 19 como relevantes. Esto demuestra cómo RFE puede identificar redundancias en datasets complejos y optimizar el rendimiento eliminando variables innecesarias.
Estos ajustes confirman que RFE no solo mejora el desempeño del modelo, sino que también lo hace más eficiente. A continuación, se analiza cómo se compara este enfoque frente al uso del dataset completo.
Los modelos que usan RFE suelen igualar o superar el rendimiento de aquellos entrenados con todas las características disponibles. En palabras de la documentación de Yellowbrick:
"Recursive feature elimination... attempts to eliminate dependencies and collinearity that may exist in the model".
Este enfoque elimina el ruido y las dependencias, lo que resulta en métricas más confiables, especialmente en datasets desbalanceados.
| Métrica | Dataset completo | Características seleccionadas por RFE | Impacto de RFE |
|---|---|---|---|
| Recall | Menor | Mayor | Mejora la detección de fraudes al reducir el ruido |
| F1-Score | Moderado | Mayor/Estable | Logra un mejor equilibrio entre precisión y recall |
| AUC | Estándar | Mejorado | Incrementa la capacidad de distinguir fraudes de transacciones legítimas |
| Costo de entrenamiento | Alto | Bajo | Menos variables implican entrenamientos más rápidos |
En problemas de fraude, es crucial priorizar métricas como Recall, F1-score o AUC en lugar de accuracy, ya que esta última puede ser engañosa cuando la clase fraudulenta es inferior al 1% del total. Para una evaluación precisa, utiliza RFECV con configuraciones como scoring='f1' o scoring='roc_auc', asegurando que el modelo sea eficaz detectando fraudes.
Al profundizar en la interpretación de los modelos basados en árboles, es esencial entender cómo estos calculan la importancia de las variables. Esto no solo valida la selección realizada, sino que también ayuda a identificar los factores clave que predicen el fraude.
Modelos como Random Forest y XGBoost suelen emplear el método de Mean Decrease in Impurity (MDI) para calcular la importancia. Este método mide cuánto reduce cada variable la impureza en los nodos del árbol. Sin embargo, en datasets desbalanceados, el MDI puede ser engañoso, ya que tiende a favorecer la clase mayoritaria.
Una alternativa más confiable es el método de Minimal Depth, que evalúa la influencia de una variable según qué tan cerca se encuentra del nodo raíz. Como explica Fabio Demaria, del Departamento de Economía "Marco Biagi":
"The underlying rationale is that variables selected closer to the root node are more influential in partitioning the data and thus hold greater predictive power."
| Métrica | Base de cálculo | Desempeño en datos desbalanceados |
|---|---|---|
| MDI (Impurity) | Reducción de impureza en cada división | Sesgada hacia la clase mayoritaria y variables de alta cardinalidad |
| Permutation Importance | Aumento del error OOB al permutar una variable | Puede ser engañosa al depender de tasas de error dominadas por la clase mayoritaria |
| Minimal Depth | Proximidad de la primera división al nodo raíz | Más confiable; no depende de predicciones OOB y es independiente del modelo |
Los valores SHAP (Shapley Additive Explanations) permiten entender la contribución específica de cada variable en una predicción. Basado en la teoría de juegos, SHAP responde preguntas como: ¿por qué el modelo clasificó una transacción como fraudulenta? Esto resulta clave para analizar patrones en casos límite o transacciones inusuales. A diferencia de otros métodos como Permutation Importance, SHAP ofrece una medida unificada que funciona con cualquier tipo de modelo.
Sin embargo, el cálculo de SHAP puede ser computacionalmente costoso, especialmente en datasets financieros grandes. Para reducir este impacto, se recomienda aplicarlo a un subconjunto representativo de datos o combinarlo con técnicas de balanceo.
El desbalance de clases puede distorsionar los cálculos de importancia. Para mitigarlo, se utilizan técnicas de muestreo como:
Una estrategia híbrida combina ambos enfoques. Por ejemplo, se puede aplicar SMOTE para aumentar los casos de fraude y luego usar técnicas como Tomek Links o ENN para eliminar ruido y outliers. Además, ajustar el umbral de clasificación en función de la prevalencia de la clase minoritaria mejora la sensibilidad hacia el fraude.
También es útil implementar restricciones en los árboles, como limitar la profundidad máxima (max_depth) o establecer un umbral mínimo de reducción de impureza (min_impurity_decrease), para evitar que el modelo memorice ruido de la clase mayoritaria. La validación cruzada con StratifiedKFold refuerza la confiabilidad de las estimaciones y mejora la capacidad del modelo para detectar patrones fraudulentos.
Las técnicas de selección de características han demostrado ser efectivas en entornos con datos altamente desbalanceados. A continuación, se presentan dos ejemplos concretos que ilustran cómo estas estrategias se traducen en mejoras significativas en métricas clave, particularmente en la detección de fraude.
En octubre de 2023, la investigadora Carmen Scartezini aplicó el test de Kolmogorov-Smirnov a un dataset europeo de tarjetas de crédito. Este análisis permitió identificar variables con diferencias notables en su distribución entre transacciones legítimas y fraudulentas. Como resultado, se eliminaron características como V13, V15, V25 y V26, que mostraban menos del 11% de diferencia en estas distribuciones.
Posteriormente, al ajustar los pesos de clase utilizando class_weight="balanced", se logró un equilibrio entre la detección de fraudes y la precisión general del modelo. Este enfoque incrementó el recall de 0,66 a 0,93. Este caso evidencia cómo las pruebas estadísticas pueden ser una herramienta poderosa para refinar la selección de variables, especialmente en contextos de desbalance extremo.
Mientras que el primer caso se centra en pruebas estadísticas, este segundo ejemplo destaca el uso de técnicas de muestreo y herramientas avanzadas de machine learning. En marzo de 2026, un tutorial de Microsoft Fabric mostró cómo implementar un flujo completo de detección de fraude utilizando LightGBM y SMOTE para equilibrar las clases en el conjunto de entrenamiento.
El modelo entrenado con datos balanceados ("smote_model") mostró un rendimiento significativamente superior al modelo base en métricas como AUROC y AUPRC. Además, herramientas como MLflow y SynapseML facilitaron la automatización y el análisis del desempeño del modelo. Cabe destacar que se escaló manualmente "Time" y "Amount", ya que las variables PCA (V1-V28) ya estaban estandarizadas.
| Estudio | Dataset | Ratio de desbalance | Técnica principal | Mejora en Recall | Mejora en AUROC/Precisión |
|---|---|---|---|---|---|
| Scartezini (2023) | Tarjetas europeas | 0,17% fraude (492/284.807) | KS test + class_weight | 0,66 → 0,93 | Optimización del trade-off |
| Microsoft Fabric (2026) | 284.807 transacciones | 0,17% fraude | SMOTE + LightGBM | Significativa | AUROC y AUPRC superiores |
La selección de características juega un papel clave en la detección de fraude, especialmente en escenarios con datos altamente desbalanceados. Este proceso permite construir modelos más eficientes al eliminar variables que no aportan valor o que son redundantes, reduciendo así el costo computacional y el tiempo necesario para entrenarlos. Además, mejora la capacidad del modelo para identificar los patrones sutiles que diferencian transacciones fraudulentas de las legítimas.
Las técnicas abordadas, como Chi-cuadrado, Información Mutua, RFE y SHAP, ofrecen herramientas adaptables según las necesidades. Por ejemplo, los métodos de filtrado son rápidos y no dependen del modelo, ideales para un primer análisis en conjuntos de datos con muchas dimensiones. Por otro lado, los métodos wrapper y basados en modelos, como los que emplean XGBoost o Random Forest, permiten capturar interacciones complejas entre variables, optimizando el rendimiento en contextos específicos.
Además, combinar la selección de características con estrategias como SMOTE, class weighting o ajustes en los umbrales de decisión puede maximizar el recall sin comprometer demasiado la precisión. Esto resulta especialmente relevante en el comercio electrónico, donde identificar la mayor cantidad de fraudes posibles puede justificar un margen de falsos positivos, dependiendo de las prioridades del negocio. Un modelo que se base en un conjunto reducido de variables clave - como la antigüedad de la cuenta, el horario de la transacción y el monto - puede mantener un buen desempeño mientras mejora la interpretabilidad. Esta claridad es crucial para que los equipos de seguridad puedan auditar y entender por qué ciertas transacciones son marcadas como sospechosas.
En contextos donde el fraude representa apenas el 0,17% o el 5,17% de las transacciones, confiar en métricas como la exactitud (accuracy) puede ser engañoso. Por eso, es fundamental priorizar indicadores como el F1-score, AUROC y AUPRC, junto con una validación cruzada estratificada, para asegurar evaluaciones más fiables y modelos que realmente protejan las operaciones del comercio electrónico.
Todo depende de lo que busques lograr con tu análisis. Si necesitas una evaluación rápida y directa de las características, especialmente cuando trabajás con muchas variables, los filtros son la opción más práctica. Son ideales para un vistazo inicial y te permiten identificar patrones básicos con rapidez.
En cambio, si querés un enfoque más detallado y preciso, el método RFE (Recursive Feature Elimination) es el indicado. Este método considera cómo interactúan las variables entre sí y mejora el modelo eliminando de manera iterativa las características menos relevantes. Esto lo convierte en una herramienta potente para quienes buscan optimizar al máximo el rendimiento del modelo.
En resumen: usá filtros para análisis preliminares rápidos, y recurrí a RFE cuando el objetivo sea afinar y perfeccionar los resultados.
Cuando el fraude representa menos del 1%, confiar únicamente en métricas tradicionales como la precisión puede llevar a conclusiones erróneas. En estos casos, es más útil recurrir a métricas como el recall, la precisión o el puntaje F1, ya que ofrecen un equilibrio entre la detección correcta y los falsos positivos. También es recomendable analizar indicadores como el ROC AUC o el valor predictivo positivo, especialmente para evaluar el desempeño en clases minoritarias. Estas métricas permiten ajustar los modelos para identificar fraudes de manera efectiva, evitando generar alertas innecesarias.
Los valores SHAP (SHapley Additive exPlanations) permiten entender cómo cada característica impacta en una predicción. Son especialmente útiles porque no solo sirven para análisis en la etapa de desarrollo, sino que también pueden aplicarse en producción. Esto significa que ofrecen interpretaciones claras y detalladas, ya sea en tiempo real o después de que el modelo esté en funcionamiento.
Gracias a esta capacidad, los valores SHAP ayudan a identificar posibles sesgos, comprender mejor las decisiones del modelo y aumentar la confianza en su desempeño. Sin embargo, hay que tener en cuenta que implementarlos en modelos complejos puede ser un proceso costoso y demandante en términos de recursos.