
La detección de anomalías en e-commerce enfrenta desafíos únicos: fraudes que representan menos del 2% de los datos y patrones que cambian constantemente. Un framework híbrido combina modelos no supervisados (para detectar patrones nuevos) y supervisados (para identificar amenazas conocidas). Este enfoque mejora la precisión y reduce los errores, especialmente en mercados como el argentino, donde métodos de pago locales y eventos promocionales generan comportamientos impredecibles.
Puntos clave:
En plataformas como Burbuxa, estos sistemas integran datos en tiempo real para analizar riesgos en pagos y compras, adaptándose a picos de transacciones como Hot Sale. La clave está en combinar tecnología y supervisión humana para proteger las ventas sin afectar la experiencia del cliente.
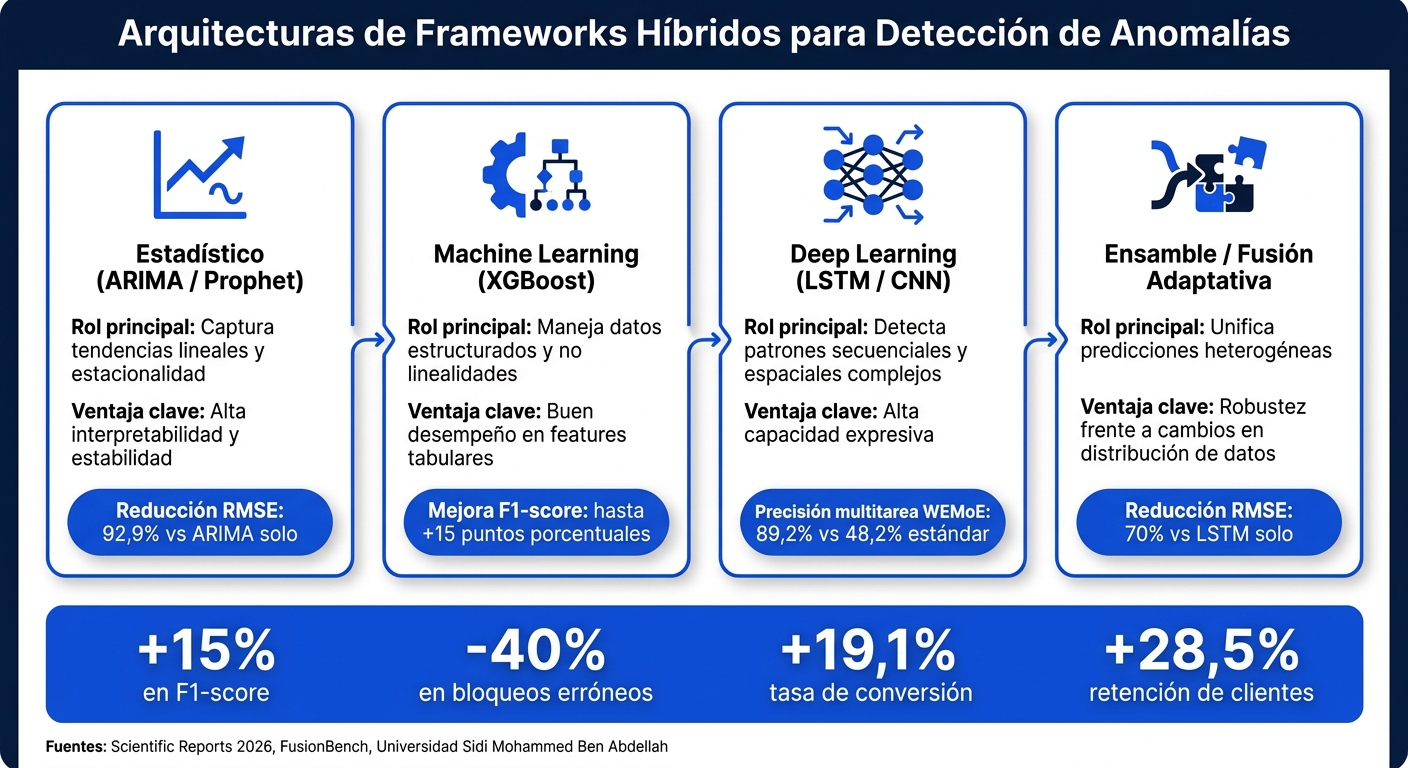
Modelos en Frameworks Híbridos de Detección de Anomalías: Comparativa
A continuación, se presentan las arquitecturas que impulsan estos frameworks en el ámbito de la detección de anomalías.
Los modelos híbridos de deep learning combinan capas diseñadas para identificar patrones tanto temporales como espaciales. Una técnica recurrente es la , que alterna bloques heterogéneos, como Transformers y modelos de espacio de estados (por ejemplo, ), en intervalos predefinidos. Otra técnica, la , permite que ambos enfoques trabajen de manera paralela dentro de una misma capa, procesando la información al mismo tiempo.
"Mezclar bloques de Transformer y Mamba frecuentemente supera a las arquitecturas homogéneas, manteniendo alta eficiencia." - Sangmin Bae, investigador en FAIR, Meta
Estas configuraciones pueden ofrecer una mejora de hasta un 2,9% en precisión en escenarios con datos etiquetados limitados, lo que resulta especialmente útil cuando hay escasez de ejemplos de anomalías.
En situaciones con pocos datos etiquetados, una solución eficaz es usar un autoencoder entrenado únicamente con datos normales. Este modelo aprende a reconstruir patrones "sanos", y cualquier anomalía genera un error de reconstrucción significativo. Este error puede usarse como una feature para un clasificador supervisado, como XGBoost. Mientras el autoencoder identifica patrones atípicos sin necesidad de etiquetas, el clasificador refina las decisiones finales basándose en ejemplos conocidos. Según FusionBench, "el conocimiento colectivo de múltiples modelos suele ser más preciso y confiable que el de cualquier modelo individual".
Esta combinación permite crear sistemas más resistentes, un tema que se amplía en el uso de ensambles y modelos estadísticos.
En el contexto de detección de fraude en e-commerce, donde los datos son altamente variables, los ensambles y modelos estadísticos ofrecen soluciones robustas. Los ensambles combinan predicciones de redes neuronales, algoritmos de aprendizaje y modelos estadísticos para mejorar la estabilidad en entornos con alta variabilidad. Los modelos estadísticos tradicionales, como ARIMA o Prophet, son útiles para captar tendencias lineales y patrones estacionales que las redes neuronales podrían pasar por alto.
En marzo de 2026, un equipo de la Universidad Sidi Mohammed Ben Abdellah desarrolló un framework híbrido que integraba CNN, LSTM y LightGBM junto con ARIMA y Prophet. Este framework utilizaba un mecanismo de ponderación adaptativa, ajustando en tiempo real la contribución de cada modelo. El enfoque logró reducir el RMSE en un 92,9% frente a ARIMA y un 70% frente a LSTM.
"La novedad reside en un mecanismo de ponderación adaptativa que ajusta dinámicamente las contribuciones de los modelos en tiempo real, garantizando robustez en contextos volátiles." - Oussama Zabraoui, Laboratorio de Técnicas Industriales
| Categoría de modelo | Rol principal | Ventaja clave |
|---|---|---|
| Estadístico (ARIMA/Prophet) | Captura tendencias lineales y estacionalidad | Alta interpretabilidad y estabilidad |
| Machine learning (XGBoost) | Maneja datos estructurados y no linealidades | Buen desempeño en features tabulares |
| Deep learning (LSTM/CNN) | Detecta patrones secuenciales y espaciales complejos | Alta capacidad expresiva |
| Ensamble/Fusión | Unifica predicciones heterogéneas | Robustez frente a cambios en la distribución de datos |
En resumen, la eficacia de un framework híbrido no depende únicamente de la complejidad de sus componentes, sino de cómo estos interactúan y se complementan entre sí.
La calidad de los datos es el pilar fundamental de cualquier framework híbrido. En el ámbito del e-commerce, los modelos se alimentan principalmente de dos tipos de información: datos transaccionales (como historial de compras, montos y frecuencia) y datos de comportamiento (clics, tiempo en página, estrategias para carritos abandonados). Para integrar estas fuentes, es necesario realizar tareas como imputar valores faltantes usando medianas o modas, normalizar las marcas temporales y codificar variables categóricas con métodos como one-hot encoding o label encoding.
A partir de estos datos procesados, la ingeniería de features juega un papel crucial en el desempeño del modelo. Entre las técnicas más comunes se encuentran las lag features (por ejemplo, ventas de los últimos 1, 7, 14 y 28 días), estadísticas móviles (media, máximo, mínimo) y normalización numérica mediante z-score o min-max. Este refinamiento de datos permite establecer una base sólida para evaluar con precisión el impacto del framework, especialmente en tareas como la detección de anomalías.
La evaluación de estos frameworks combina métricas estadísticas tradicionales - como RMSE, MAE y MAPE - con indicadores de negocio más orientados al impacto, como la tasa de conversión, la retención de clientes y la rentabilidad bruta. Un ejemplo destacado es un estudio de febrero de 2026 publicado en Scientific Reports, que analizó un framework híbrido aplicado al dataset Retailrocket. Este modelo logró un RMSE de 1,05 y un MAE de 0,27, además de un incremento del 6,3% en la rentabilidad general al incorporar Reinforcement Learning para precios dinámicos. También se registraron aumentos del 19,1% en la tasa de conversión y del 28,5% en la retención de clientes en comparación con modelos estándar.
Otro dato interesante es cómo una mejora del 10% en el MAPE puede traducirse en una reducción de entre 1% y 3% en los costos de inventario. Esto resalta cómo las métricas técnicas y los resultados comerciales están profundamente interconectados.
"El cuello de botella para la mayoría de los vendedores ya no es la novedad algorítmica. Es la integración de datos, modelos y optimización en un único flujo de trabajo." - Bhum Soonjun, DataGlass Research Lab
Además de los resultados cuantitativos, la capacidad de interpretar los modelos es clave para su adopción en escenarios reales.
Una tendencia actual en el desarrollo de frameworks híbridos es incluir a los analistas humanos en el proceso no solo para validar resultados, sino también para corregirlos activamente. En sistemas con arquitecturas multi-agente, un "Agente Supervisor" desempeña un papel importante al monitorear en tiempo real al agente de análisis, identificar errores y proporcionar retroalimentación correctiva. Luego, el modelo utiliza esta retroalimentación para revisar y aprender de sus errores, mejorando en iteraciones futuras.
| Característica | Sistema tradicional | Híbrido con human‑in‑the‑loop |
|---|---|---|
| Corrección de errores | Reactiva (post‑facto) | Proactiva (vía Agente Supervisor) |
| Escalabilidad | Limitada por el equipo | Automática; humanos gestionan excepciones |
| Explicabilidad | Alta (conducida por humanos) | Alta (cadenas de razonamiento auditables) |
| Aprendizaje | Actualizaciones manuales | Continuo a partir de correcciones humanas |
Este enfoque aborda un desafío clave: los agentes de análisis pueden enfrentar problemas al usar herramientas específicas de e-commerce si no han sido entrenados con datos de alta fidelidad y bajo supervisión multi-agente. Este tipo de integración permite aprovechar lo mejor de la automatización y la intervención humana, logrando un equilibrio entre eficiencia y precisión.
Los frameworks híbridos, con su diseño de dos capas (una capa supervisada para patrones conocidos y otra no supervisada para detectar anomalías nuevas), han demostrado superar a los modelos tradicionales en la identificación de fraudes que están en constante cambio. Esto resulta especialmente importante en el ámbito del e-commerce, donde los esquemas fraudulentos evolucionan rápidamente. Por ejemplo, técnicas de fusión como WEMoE alcanzan un 89,2% de precisión en entornos multitarea, comparado con el 48,2% de los modelos preentrenados estándar. Esto significa que pueden identificar casi el doble de anomalías sin aumentar los falsos positivos.
Además, las arquitecturas avanzadas, como los Fraud Copilots que integran LLMs (Modelos de Lenguaje Extenso), analizan en tiempo real las tendencias de las transacciones y sugieren nuevas reglas de negocio dinámicamente, como establecer límites específicos por dispositivo o mercado. Sin embargo, lograr este nivel de precisión presenta desafíos técnicos significativos, especialmente en términos de capacidad computacional.
Trabajar con grandes volúmenes de datos y realizar simulaciones en tiempo real puede generar demoras críticas, un problema serio cuando cada segundo cuenta para detectar fraudes.
"Una de las principales consideraciones es latencia, ya que la utilidad del Copilot depende de que las consultas y simulaciones se ejecuten en tiempos de respuesta aceptables." - GatekeeperX
Para reducir estos tiempos, los equipos técnicos han implementado soluciones como vistas materializadas (usando herramientas como ClickHouse) y cachés con Redis, que permiten mantener tiempos de respuesta ágiles sin comprometer la precisión. Sin embargo, otro obstáculo importante es la infraestructura legacy que muchas empresas aún utilizan, la cual no está diseñada para soportar el procesamiento en tiempo real que estos modelos requieren. Esto convierte la integración en un desafío recurrente.
Más allá de la latencia, hay otros problemas críticos que deben abordarse. Uno de los más destacados es el data drift: con el tiempo, los patrones aprendidos por el sistema dejan de ser representativos de la realidad, lo que puede llevar a detectar amenazas inexistentes o ignorar las que sí están ocurriendo, si no se realiza un monitoreo constante.
Otro reto específico de los frameworks que usan LLMs son las alucinaciones: el modelo puede generar explicaciones que parecen correctas pero que son completamente erróneas, complicando la toma de decisiones en situaciones de alto impacto. Por esta razón, la tendencia actual favorece arquitecturas copilot, donde los analistas humanos siguen siendo una pieza clave del proceso, en lugar de sistemas completamente automatizados.
Estos desafíos subrayan la importancia de un monitoreo constante y la intervención humana, especialmente en plataformas como Burbuxa, donde la detección a tiempo de fraudes resulta esencial.
El comercio a través de WhatsApp e Instagram sigue un flujo bastante claro: consulta → recomendación → carrito → pago. Pero, ¿qué pasa cuando este flujo se interrumpe? Ahí es donde entra en juego un framework híbrido. Este sistema combina dos enfoques: uno no supervisado, que establece lo "normal" basándose en tiempos, montos promedio y horarios típicos; y otro supervisado, que utiliza datos históricos de fraude para identificar patrones sospechosos, como múltiples intentos fallidos de pago, pedidos repetitivos o compras de alto valor en horarios atípicos. Este enfoque conjunto no solo mejora la precisión al detectar anomalías, sino que también reduce los falsos positivos, analizando cada interacción en función de su contexto y antecedentes.
Para que este modelo híbrido funcione, es clave contar con datos consistentes provenientes de distintas fuentes. Burbuxa logra esto al sincronizar en tiempo real información como productos, pedidos, clientes, inventarios, descuentos y políticas desde plataformas como Shopify, Tiendanube y VTEX. Todo esto se integra en una única capa de datos, resolviendo problemas de información inconsistente entre canales. Por ejemplo, permite vincular una conversación en WhatsApp con el historial de compras del cliente y el perfil de riesgo del producto involucrado, generando un scoring detallado. Además, cuando un comerciante marca una alerta como falso positivo o fraude real, esa información alimenta continuamente el modelo supervisado, afinando su precisión. Esta centralización no solo mejora la detección de riesgos, sino que también adapta el sistema a las particularidades del mercado argentino.
En Argentina, donde el comercio móvil y las ventas a través de redes sociales son predominantes, y donde fechas como Hot Sale o CyberMonday generan picos de transacciones, se necesitan sistemas que puedan adaptarse rápidamente. Durante estos eventos, el volumen de operaciones puede dispararse en cuestión de horas. Por eso, el sistema de Burbuxa ajusta automáticamente sus modelos no supervisados y los umbrales de detección para reconocer como normales tickets más altos o volúmenes fuera de lo habitual. Además, tiene en cuenta las particularidades de los medios de pago locales, como las tarjetas nacionales, billeteras digitales y pagos en cuotas. Por ejemplo, puede identificar riesgos específicos, como intentos repetidos con diferentes tarjetas en un mismo dispositivo o pagos en cuotas para compras de bajo valor, sin bloquear transacciones legítimas. Esto asegura un equilibrio entre seguridad y experiencia del usuario.
Los frameworks híbridos han marcado un avance concreto en la capacidad de los e-commerce para detectar fraudes y anomalías operativas. Al combinar modelos supervisados y no supervisados, estos sistemas logran adaptarse a patrones nuevos sin perder precisión en los ya conocidos. Las mejoras de entre 5 y 15 puntos porcentuales en el F1-score, junto con una reducción de hasta un 40% en transacciones legítimas bloqueadas por error, muestran el impacto directo de este enfoque.
En el caso del mercado argentino, estos beneficios son aún más evidentes. Factores como los pagos en cuotas, el uso de billeteras digitales, la alta estacionalidad y la volatilidad económica generan un entorno donde las reglas estáticas resultan insuficientes. Un sistema híbrido que ajusta sus umbrales automáticamente durante eventos como el Hot Sale o que identifica riesgos en intentos repetidos con distintas tarjetas nacionales protege al negocio sin perjudicar las transacciones legítimas.
El impacto no se limita al ámbito técnico: evitar un falso positivo significa una compra sin fricciones, mientras que detectar una anomalía a tiempo evita contracargos y los costos asociados. En América Latina, donde cada dólar de fraude puede costarle al comercio aproximadamente USD 3,40 en multas, operaciones y pérdida de clientes, la diferencia entre un sistema reactivo y uno híbrido adaptativo se traduce directamente en pesos recuperados.
Esta integración técnica se refleja en herramientas prácticas como Burbuxa, que centraliza en tiempo real datos de conversaciones, pedidos y clientes, alimentando al sistema con información precisa. La clave está en iterar constantemente: reentrenar con datos reales, monitorear el desvío del modelo - un desafío ya tratado en secciones anteriores - y ajustar los umbrales según las condiciones del mercado. Los frameworks híbridos no son soluciones estáticas; son sistemas dinámicos que mejoran con cada transacción procesada.
Combinar algoritmos supervisados y no supervisados es una estrategia clave para abordar desafíos en entornos complejos como el comercio electrónico. Este enfoque permite identificar patrones emergentes y ajustarse a tácticas de fraude en constante evolución. ¿El resultado? Una experiencia de compra más segura para los usuarios.
Además, en áreas donde las decisiones tienen un alto impacto, como las finanzas, integrar la automatización con la revisión humana no solo mejora la precisión, sino que también aumenta la confianza en el sistema. Este equilibrio entre tecnología y supervisión humana es esencial para minimizar errores y garantizar procesos confiables.
El umbral de riesgo se establece asignando una puntuación basada en diferentes indicadores, como el monto de las transacciones, la frecuencia, la ubicación y el comportamiento observado. Al implementar este sistema, es recomendable comenzar con umbrales más conservadores. Esto permite ajustar los parámetros con el tiempo, utilizando análisis manual y datos históricos recopilados durante un período de 1 a 3 meses.
Una estrategia efectiva es dividir los casos en niveles de riesgo: bajo, medio y alto. Esta clasificación no solo facilita la gestión, sino que también permite realizar ajustes periódicos para mantener un equilibrio entre la detección de fraudes y la reducción de falsos positivos.
El data drift se controla en tiempo real gracias a la inteligencia artificial, que analiza datos en vivo para identificar cambios en métricas clave como la satisfacción del cliente o las tasas de conversión. Cuando se detectan variaciones importantes, se activan alertas automáticas que permiten realizar ajustes inmediatos, como modificar campañas publicitarias o atender casos críticos, sin afectar la operación diaria.
Además, los modelos de aprendizaje automático se recalibran de manera dinámica para ajustar sus predicciones. Esto asegura que las correcciones se implementen de forma segura, manteniendo el flujo normal de las actividades y reduciendo los riesgos asociados con decisiones basadas en datos desactualizados o incorrectos.