En e-commerce, el fraude evoluciona constantemente, y los modelos híbridos antifraude son la solución más eficaz. Combinan reglas estáticas, machine learning supervisado y deep learning, permitiendo detectar fraudes conocidos y patrones complejos en tiempo real. Este enfoque reduce errores y mejora la experiencia del cliente.
¿Cómo funcionan?
Beneficios clave:
Antes de implementar, es esencial auditar tu sistema actual, definir objetivos claros y construir pipelines de datos sólidos. Además, los modelos deben entrenarse con datos balanceados y monitorearse continuamente para adaptarse a nuevos patrones de fraude.
En Argentina y América Latina, los fraudes más comunes incluyen el uso de tarjetas robadas, robo de identidad y contracargos fraudulentos. Los modelos híbridos son ideales para enfrentarlos al combinar análisis de datos históricos y detección de anomalías en tiempo real.
Conclusión:
Un sistema híbrido bien diseñado puede reducir las pérdidas por fraude hasta un 60% y bajar los contracargos a menos del 1%. Además, mejora la conversión al minimizar bloqueos innecesarios de clientes legítimos.
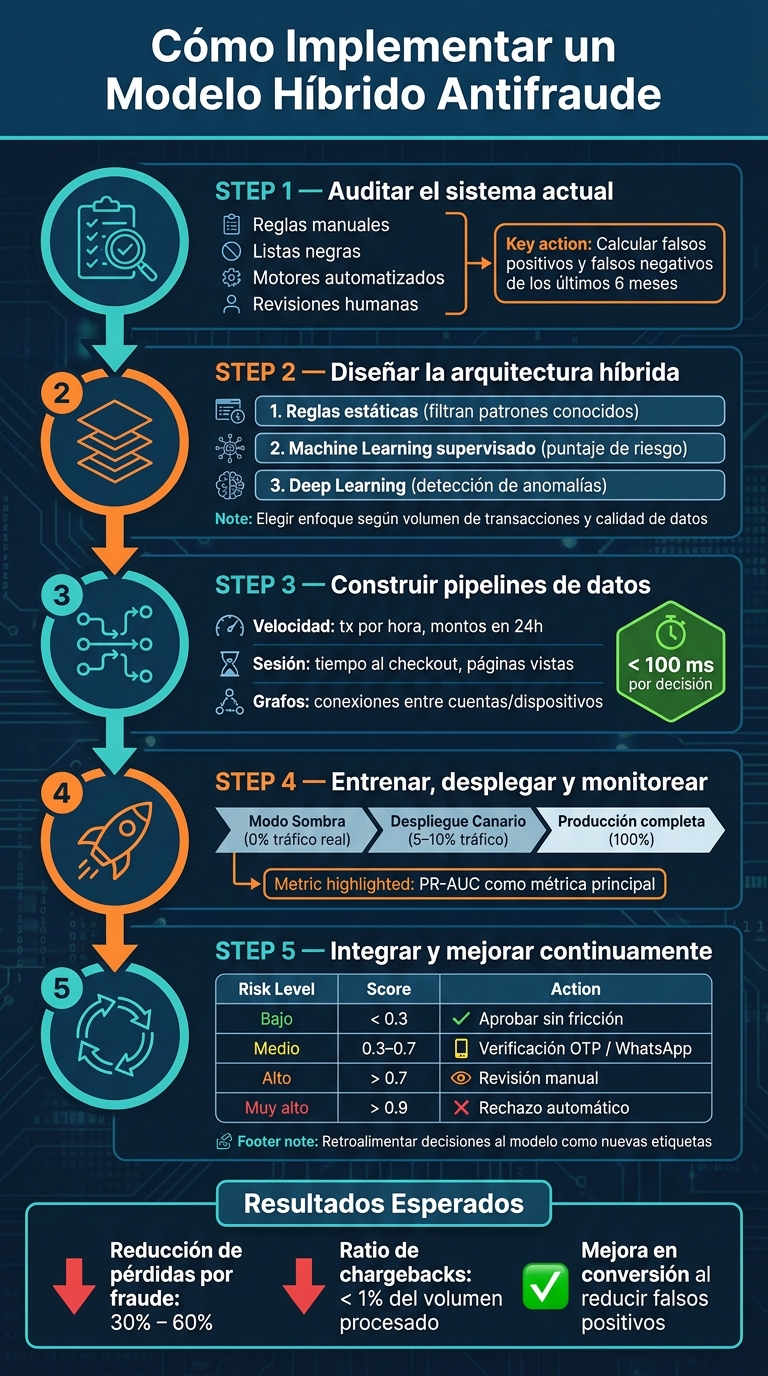
Cómo Implementar un Modelo Híbrido Antifraude en E-commerce
Antes de diseñar una nueva arquitectura antifraude, es clave analizar cómo está funcionando tu sistema actual. Saltar directamente a nuevas tecnologías sin este paso puede generar gastos innecesarios y resultados inciertos.
El primer paso es identificar todos los elementos que componen tu sistema antifraude. Esto incluye:
Para cada componente, es importante definir qué datos utiliza, qué decisiones toma y cuál es su tasa de error. Además, revisá los registros de los últimos seis meses para calcular la cantidad de falsos negativos y falsos positivos. Este último dato puede ser revelador, ya que un sistema demasiado estricto podría estar rechazando clientes legítimos, lo que se traduce en pérdidas de ventas que no siempre se reflejan en los informes de fraude.
Una auditoría no tiene sentido si no está orientada a objetivos claros. Algunas métricas clave que deberías considerar para alinear tu sistema con los objetivos del negocio incluyen:
| Métrica | Objetivo de negocio |
|---|---|
| Tasa de fraude | Reducir pérdidas directas. |
| Tasa de falsos positivos | Garantizar una buena experiencia del cliente. |
| Tasa de contracargos | Disminuir costos operativos y penalidades. |
| Tiempo de revisión manual | Incrementar la eficiencia operativa. |
Establecé valores de referencia para cada métrica antes de realizar cambios. Esto te permitirá medir si las modificaciones realmente generan mejoras.
Un modelo híbrido debe integrarse con los sistemas que ya estás utilizando. Los puntos clave de conexión suelen ser:
Por ejemplo, herramientas como Burbuxa, que centralizan la comunicación con clientes a través de WhatsApp e Instagram, permiten sincronizar en tiempo real pedidos y datos de clientes. Estas plataformas pueden servir para validar identidades o detectar comportamientos sospechosos sin interrumpir la experiencia del usuario legítimo. Integrar el score de fraude en estos flujos de comunicación mejora la toma de decisiones en cada interacción.
Con una evaluación exhaustiva de tu sistema actual y una integración clara con tus herramientas, estarás listo para avanzar hacia una arquitectura híbrida que optimice la detección de fraude en tiempo real.
Con la auditoría completada y los puntos de integración definidos, el siguiente paso es diseñar una arquitectura híbrida que permita detectar fraudes en tiempo real. Esto se logra combinando diversas capas: reglas predefinidas, modelos de machine learning, detección de anomalías y análisis de relaciones. Juntas, estas herramientas construyen un sistema de decisión donde cada componente complementa y refuerza a los demás.
La elección del enfoque depende de tres factores principales: el volumen de transacciones, la calidad de los datos etiquetados disponibles y las capacidades técnicas del equipo. No existe una solución única que funcione para todos los casos.
| Estrategia híbrida | Cuándo usarla | Fortalezas | Limitaciones |
|---|---|---|---|
| Reglas + ML supervisado | Tiendas con historial etiquetado y motor de reglas existente | Fácil de interpretar y rápida implementación | Las reglas pueden volverse obsoletas; el ML necesita datos etiquetados |
| Supervisado + detección de anomalías | Patrones de fraude variados o en constante cambio | Detecta tanto fraudes conocidos como nuevos | Requiere un ajuste más complejo |
| ML + análisis de grafos | Redes de fraude organizado o cuentas vinculadas | Ideal para identificar conexiones entre cuentas | Demanda infraestructura avanzada |
| Reglas + ML + revisión manual | Flujos de alto valor o con regulación estricta | Combina control humano con automatización | Implica mayor carga operativa |
Por ejemplo, una tienda en Shopify o Tiendanube con menos de 10.000 transacciones mensuales puede comenzar con una combinación de reglas básicas y un modelo supervisado sencillo, como gradient boosting. En cambio, si el volumen supera las 100.000 transacciones mensuales y los datos están bien etiquetados, es recomendable incorporar técnicas más complejas como análisis de grafos o modelos no supervisados.
Una vez definido el enfoque, el siguiente paso es construir los pipelines de datos necesarios.
Las variables que alimentan el modelo son fundamentales para su rendimiento. Basándonos en lo identificado durante la auditoría, las siguientes familias de features son especialmente relevantes para el e-commerce en Argentina y la región: velocidad, comportamiento de sesión y consistencia geográfica.
tx_count_user_1h).tx_amount_user_24h).El pipeline en línea debe procesar decisiones en menos de 100 milisegundos para no afectar la experiencia del cliente. El flujo típico es el siguiente:
El uso de caché juega un papel crucial para cumplir con los requisitos de latencia. Por ejemplo:
Es fundamental garantizar la consistencia entre las features usadas durante el entrenamiento del modelo y las empleadas en producción. Esto asegura que el sistema mantenga un rendimiento óptimo.
Uno de los mayores retos al entrenar modelos para detectar fraude es el desbalance de clases: las transacciones fraudulentas suelen representar menos del 1% del total. Esto puede llevar al modelo a clasificar todo como legítimo. Para contrarrestarlo, se emplean técnicas como SMOTE (Synthetic Minority Oversampling Technique) y se asignan pesos más altos a los falsos negativos durante el entrenamiento, asegurando que el modelo sea más sensible a los fraudes.
En este contexto, la curva precisión-recall (PR-AUC) es la métrica clave para evaluar el desempeño. Un modelo eficaz debe detectar la mayoría de los fraudes reales (recall) y, al mismo tiempo, evitar generar un exceso de alertas falsas que sobrecarguen al equipo de revisión. Además, el backtesting con datos históricos segmentados por tiempo es esencial para simular el desempeño del modelo en el pasado y evitar problemas como el sobreajuste. Este enfoque de entrenamiento y validación es un componente continuo dentro del ciclo de mejora de la arquitectura híbrida.
Investigadores de la Universidad de California (Berkeley) y Johns Hopkins lograron expandir 25 variables originales a 118 utilizando Deep Feature Synthesis en un conjunto de datos de 2,45 millones de registros de tarjetas de crédito. Su modelo CNN profundo alcanzó un 91% de accuracy, 92% de precisión y 90% de recall.
Con el modelo validado, el siguiente paso es implementarlo cuidadosamente en un entorno controlado y monitorear su rendimiento.
Para minimizar riesgos, el modelo debe implementarse primero en modo sombra (shadow mode), funcionando en paralelo al sistema actual sin afectar las decisiones reales. Esto permite comparar su rendimiento con el sistema en producción y realizar ajustes necesarios sin interferir en las transacciones.
Una vez que el modelo demuestra estabilidad, se avanza a un despliegue canario, donde recibe solo un pequeño porcentaje del tráfico real, como el 5% o 10%, mientras el resto sigue siendo procesado por el modelo anterior. Si las métricas clave, como la latencia, la tasa de falsos positivos o los chargebacks, permanecen estables o mejoran, se incrementa gradualmente su participación hasta cubrir el 100% del tráfico.
El monitoreo continuo es indispensable, ya que los modelos tienden a degradarse con el tiempo debido a los cambios en los patrones de fraude. Es crucial vigilar indicadores como data drift, concept drift y métricas operativas, incluyendo la tasa de chargebacks y el tiempo de respuesta del sistema. Una estrategia efectiva para mantener la adaptabilidad es usar umbrales dinámicos en lugar de valores fijos. Por ejemplo, en lugar de bloquear transacciones con un puntaje mayor a 0,8, se podría bloquear el 1% más riesgoso del volumen diario, ajustándose automáticamente a picos estacionales como el Hot Sale o el Cyber Monday.
Con el modelo desplegado y monitoreado, su integración en los procesos operativos debe ajustarse al nivel de riesgo detectado:
| Nivel de riesgo | Acción automática | Canal de intervención |
|---|---|---|
| Bajo (< 0,3) | Aprobar sin fricción adicional | Ninguno |
| Medio (0,3 – 0,7) | Solicitar verificación adicional (OTP, documento) | WhatsApp o e-mail automático |
| Alto (> 0,7) | Retener la orden para revisión manual | Notificá al equipo interno |
| Muy alto (> 0,9) | Rechazar automáticamente | Notificación al cliente vía WhatsApp |
Herramientas como Burbuxa permiten automatizar estas acciones conectando los puntajes de riesgo a flujos de comunicación en plataformas como WhatsApp e Instagram. Por ejemplo, si una transacción se clasifica en el rango de riesgo medio, Burbuxa puede enviar automáticamente un mensaje al cliente solicitando confirmación de identidad, sin necesidad de intervención humana. En el caso de usuarios de bajo riesgo, el proceso es completamente fluido y sin interrupciones.
Este tipo de integración no solo reduce la fricción para los compradores legítimos, sino que también permite que el equipo humano enfoque su atención en los casos más críticos. Además, las decisiones tomadas por el equipo - aprobar o rechazar órdenes retenidas - deben retroalimentarse al modelo como nuevas etiquetas, cerrando así un ciclo de aprendizaje continuo que mejora el sistema con el tiempo.
Para que los modelos híbridos mantengan su efectividad, es clave establecer un ciclo de mejora continua y gobernanza que conecte el monitoreo constante del sistema con su evolución.
Es importante medir tanto el rendimiento técnico como el impacto en el negocio utilizando métricas específicas:
| Métrica | Qué mide | Consideraciones |
|---|---|---|
| Tasa de chargebacks | Proporción de transacciones en disputa | Definí umbrales que aseguren un impacto positivo en el negocio. |
| Falsos positivos | Porcentaje de transacciones legítimas bloqueadas | Mantenelos bajos para no afectar la conversión. |
| Recall de fraude | Fracción de fraudes detectados sobre el total real | Buscá maximizarlo para una detección más efectiva. |
| Tiempo de respuesta del modelo | Latencia en la toma de decisiones | Asegurá respuestas en menos de 100 ms. |
| Ahorro estimado por fraude evitado | Impacto económico directo | Realizá un seguimiento mensual del ahorro en pesos argentinos. |
Estas métricas deben acordarse entre los equipos técnicos y de negocio. Por ejemplo, un modelo puede ser muy preciso técnicamente, pero si genera demasiados falsos positivos, podría perjudicar la conversión. Estas métricas, además, son útiles para realizar pruebas controladas que permitan validar mejoras sin afectar la operación diaria.
Una buena práctica es ejecutar el modelo en modo sombra para observar su desempeño sin afectar las operaciones. Si en un plazo de al menos dos semanas se demuestran mejoras, se pueden implementar pruebas A/B iniciales con un 10% del tráfico. Si las métricas muestran resultados positivos, la exposición puede incrementarse de manera progresiva, siempre evitando aplicar cambios en fechas clave como el Hot Sale o el Cyber Monday.
Una vez que las mejoras han sido validadas, es indispensable reforzar la gobernanza y garantizar la explicabilidad del sistema.
En sistemas antifraude, la explicabilidad es fundamental. Permite reconstruir los criterios utilizados para justificar decisiones, como rechazar o retener una transacción. Herramientas como SHAP (SHapley Additive exPlanations) son útiles para identificar las variables que más influyeron en una predicción. Esto no solo facilita auditorías internas, sino que también ayuda a responder reclamos de clientes de manera más transparente.
En el contexto argentino, la Ley 25.326 de Protección de Datos Personales establece restricciones sobre el uso automatizado de datos para decisiones que afecten a las personas. Por eso, es esencial documentar cada decisión, registrar las versiones del modelo y mantener un historial de auditoría detallado. Este historial debe incluir la fecha, la justificación de cada cambio y un análisis de las métricas antes y después de cada actualización del sistema. Esto asegura el cumplimiento normativo y respalda la confiabilidad del sistema.
Implementar un modelo híbrido antifraude es un proceso que requiere avanzar paso a paso. Esta guía propone un camino claro: auditar el sistema actual, diseñar una arquitectura que combine reglas, modelos clásicos y deep learning, construir pipelines de datos sólidos, desplegar scoring en tiempo real e integrar las decisiones en los flujos operativos del negocio. Cada etapa se construye sobre la anterior, y saltarse alguna puede comprometer el rendimiento final.
Los resultados justifican el trabajo. Los sistemas híbridos bien desarrollados pueden reducir las pérdidas por fraude entre un 30 % y un 60 % en comparación con los modelos basados únicamente en reglas. Además, es posible disminuir el ratio de chargebacks a menos del 1 % del volumen procesado con tarjeta. También se logra liberar órdenes legítimas bloqueadas por falsos positivos, lo que mejora la conversión sin aumentar el riesgo.
En Argentina, las particularidades del mercado exigen ajustes frecuentes. El uso extendido de tarjetas de crédito en cuotas, la popularidad de las billeteras virtuales y la volatilidad de precios en pesos hacen que los modelos deban adaptarse constantemente para no perder efectividad.
Un aspecto clave es la conexión con los canales de atención al cliente. Cuando una transacción queda en revisión, la experiencia del cliente depende de la rapidez y claridad en la comunicación. Herramientas como Burbuxa permiten automatizar mensajes en WhatsApp e Instagram, los canales más populares en la región, solicitando verificaciones cuando el score lo indica y manteniendo al cliente informado sin complicaciones. Además, los datos recopilados por estas interacciones enriquecen el análisis antifraude con señales adicionales, como patrones de comportamiento en chat o el historial de clientes recurrentes, que un sistema enfocado solo en transacciones no detecta. Este flujo constante de información refuerza la capacidad de adaptación del sistema.
Este enfoque dinámico e integrado asegura que cada mejora incremente la seguridad. El fraude está en constante cambio, y monitorear, experimentar y ajustar el modelo continuamente - como se detalló en la sección de gobernanza - es lo que transforma un buen modelo inicial en una ventaja competitiva duradera.
Para construir un modelo híbrido que detecte fraudes de manera efectiva, es imprescindible contar con ciertos datos clave que permitan identificar patrones sospechosos. Estos son algunos de los más importantes:
Tener acceso a estos datos no solo mejora la capacidad del modelo para detectar fraudes, sino que también lo hace más rápido y eficiente.
Para ajustar el umbral de riesgo sin que se disparen los falsos positivos, es clave utilizar métricas diseñadas para manejar conjuntos de datos desbalanceados, como las curvas ROC o precisión-recall. Estas herramientas te permiten evaluar el desempeño del modelo de manera más precisa en escenarios donde las clases están desproporcionadas.
Además, es fundamental analizar datos específicos como el comportamiento de los usuarios, las transacciones realizadas y las conexiones dentro de la red. Esto te ayudará a determinar un valor inicial del umbral que tenga sentido en tu contexto.
Por último, asegurate de validar este umbral mediante pruebas en tiempo real. Esto permitirá ajustar el equilibrio entre detectar posibles fraudes y mantener una experiencia fluida para los usuarios, reduciendo al mínimo los rechazos innecesarios.
En el ámbito de la detección de fraude en e-commerce, es fundamental reentrenar el modelo periódicamente. La frecuencia de este proceso depende de qué tan rápido cambian los datos y el comportamiento del fraude, lo que puede variar desde semanas hasta meses. Este enfoque permite adaptarse a nuevas tendencias y patrones, ayudando a prevenir el drift y asegurando que el sistema mantenga su precisión.