
Las pruebas A/B pueden ser muy útiles para mejorar conversiones y el CTR en e-commerce, pero solo si se ejecutan con objetivos bien definidos. Sin una planificación adecuada, es fácil cometer errores que generan datos confusos y decisiones equivocadas. Estos son los errores más comunes y cómo evitarlos:
Herramientas como Burbuxa pueden facilitar el proceso, integrando datos en tiempo real y automatizando pruebas A/B para evitar estos problemas. Lo clave es planificar, medir correctamente y no improvisar durante el proceso.
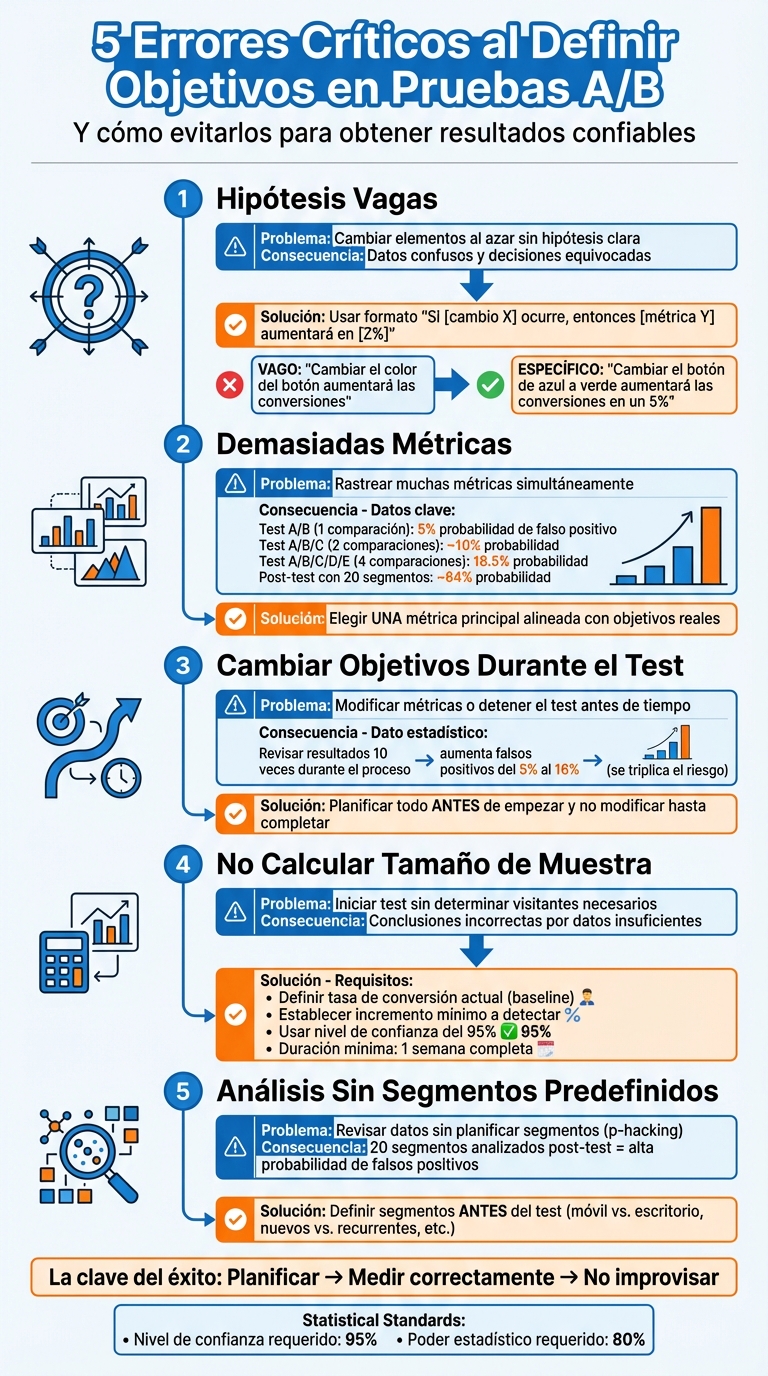
5 errores comunes al definir objetivos en pruebas A/B y cómo evitarlos
Uno de los errores más comunes en las pruebas A/B es realizar cambios sin una hipótesis clara. Muchas tiendas simplemente ajustan elementos al azar - cambian un botón aquí, un título allá - con la esperanza de que "algo funcione". ¿El resultado? Datos confusos y decisiones basadas en suposiciones.
Tener una hipótesis convierte las pruebas A/B en un proceso más estructurado y confiable. Sin una, no podés saber qué estás evaluando realmente ni por qué un cambio tuvo éxito o no. Como señala :
"La prueba de hipótesis de conversión es un método científico para comparar diferentes versiones de su sitio web o aplicación para ver cuál funciona mejor en términos de conversiones".
Además, una hipótesis clara no solo te indica si un cambio funcionó, sino también por qué influyó en el comportamiento del usuario. Este entendimiento es clave para aplicar lo aprendido en futuras estrategias.
Ejemplo de hipótesis vaga vs. específica:
| Hipótesis vaga | Hipótesis específica |
|---|---|
| "Cambiar el color del botón aumentará las conversiones" (subjetiva, sin métrica) | "Cambiar el botón de azul a verde aumentará las conversiones en un 5%" (clara y medible) |
El formato estándar para una buena hipótesis es: "Si [cambio X] ocurre, entonces [métrica Y] aumentará en [Z%]". Además, asegurate de que cumpla con los principios SMART: Específica, Medible, Alcanzable, Relevante y Temporal. Por ejemplo: "Si cambio el texto del botón de 'Comprar' a 'Agregar al carrito', la tasa de clics aumentará en un 10%".
Un punto clave: probá solo un elemento a la vez. Si modificás el título, la imagen y el botón al mismo tiempo, no podrás identificar qué cambio fue el responsable del resultado. Además, buscá alcanzar un nivel de significancia estadística, generalmente un p-valor de 0,05 o menos, para asegurarte de que los resultados no sean producto del azar.
Un error común en las pruebas es intentar medir demasiadas métricas al mismo tiempo. Muchas tiendas analizan conversiones, clics, tiempo en página, tasa de rebote y productos agregados al carrito en un solo test, con la esperanza de encontrar "la métrica ganadora". El problema es que, mientras más métricas rastreás al mismo tiempo, mayor es la posibilidad de obtener resultados engañosos o falsos positivos.
Cuando intentás seguir demasiadas métricas, se vuelve complicado identificar cuál de ellas está realmente influyendo en el cambio de comportamiento de los usuarios. Además, tener múltiples objetivos puede hacer que factores externos, como la competencia o cambios en el entorno, afecten los resultados.
Un dato importante a considerar: si realizás pruebas con un nivel de confianza del 95%, hay un 5% de probabilidad de detectar un cambio "estadísticamente significativo" incluso cuando no existe ninguna diferencia real entre las opciones evaluadas. Esto significa que, al realizar 10 pruebas independientes con ese nivel de confianza, existe un 40% de probabilidad de que al menos una arroje un falso positivo. Si comparás cuatro ofertas diferentes contra un control, esa probabilidad aumenta al 18,5%.
| Tipo de comparación | Número de comparaciones | Probabilidad de al menos un falso positivo (95% confianza) |
|---|---|---|
| Test A/B | 1 | 5% |
| Test A/B/C | 2 | ~10% |
| Test A/B/C/D/E | 4 | 18,5% |
| Post-test (20 segmentos) | 20 | ~64% |
Otro aspecto clave: mejorar métricas secundarias no siempre se traduce en un impacto positivo en tus objetivos principales, como la optimización de ventas en TiendaNube. Por ejemplo, podrías aumentar los clics, pero si ese tráfico no es de calidad, podrías terminar con menos ventas .
Por eso, es fundamental elegir una métrica principal que te permita obtener resultados claros y relevantes. Esto es especialmente crítico al ejecutar campañas automatizadas en WhatsApp, donde el exceso de datos puede oscurecer el ROI real.
Para evitar la confusión que generan las métricas múltiples, el primer paso es definir una métrica principal que esté alineada con tus objetivos reales. Esta métrica debe reflejar lo que realmente importa para tu negocio, no simplemente lo que es más fácil de medir. Por ejemplo, no uses la tasa de clics (CTR) solo porque es más rápida de analizar; una CTR más alta podría atraer tráfico de baja calidad y, en consecuencia, reducir tus ingresos.
Si necesitás hacer seguimiento de métricas secundarias, utilizá la corrección de Bonferroni. Este método consiste en ajustar tu nivel de significancia (alfa) dividiéndolo por el número de comparaciones que hacés. Por ejemplo, si realizás cuatro comparaciones, usá un nivel de significancia del 1,25% (5% / 4) para mantener una confianza general del 95%. Además, es importante no cambiar la métrica principal una vez que el test haya comenzado, ya que esto aumenta el riesgo de obtener falsos positivos.
Modificar los objetivos en medio de un test - como cambiar la métrica principal, alterar la distribución del tráfico o detener el experimento al detectar un supuesto "ganador" - puede afectar gravemente la validez de los resultados. Esto podría llevarte a tomar decisiones basadas en datos poco confiables.
Hacer ajustes durante el test aumenta el riesgo de obtener falsos positivos y sesgos en los resultados. Por ejemplo, en una simulación de 100 tests con un nivel de confianza del 95%, revisar los resultados 10 veces durante el proceso, en lugar de una sola vez al final, aumenta la tasa de falsos positivos del 5% al 16%. Esto significa que el riesgo de identificar incorrectamente un "ganador" se triplica, incluso si no hay diferencias reales entre las variantes.
Cambiar la distribución del tráfico, como pasar de 80/20 a 50/50, también puede distorsionar los datos. Esto sucede porque los visitantes que regresan suelen permanecer en la experiencia original, provocando un "retraso en la conversión". En este caso, las conversiones iniciales se mezclan con los nuevos datos, generando inconsistencias.
Además, los datos iniciales tienden a mostrar fluctuaciones más extremas debido al tamaño reducido de la muestra. Las métricas solo comienzan a estabilizarse cuando se recopila una cantidad suficiente de datos. Si es necesario realizar un cambio importante en los objetivos o en la distribución del tráfico, lo más prudente es detener el test actual y empezar uno nuevo. Esto asegura que los datos sean consistentes y confiables.
Definir objetivos claros desde el principio evita estos problemas y permite obtener resultados más precisos.
Para evitar errores, es fundamental planificar cuidadosamente antes de comenzar. Establecé la métrica principal y una hipótesis específica desde el inicio, comprometiéndote a no modificarlas durante el test. Calculá el tamaño de muestra necesario según tu tráfico y el incremento esperado, y asegurate de mantener el test hasta alcanzarlo.
Elegí una métrica que esté directamente relacionada con lo que estás evaluando. Por ejemplo, si estás probando un nuevo diseño en una página de producto, usá "Agregar al carrito" como métrica principal en lugar de indicadores más generales, como la tasa de clics (CTR), que podrían no reflejar el impacto real en tu negocio.
Finalmente, documentá cada test, incluyendo hipótesis y resultados. Esto no solo ayuda a evitar repetir errores, sino que también te proporciona un registro histórico valioso para futuros experimentos. Este enfoque fomenta un aprendizaje continuo y mejora la calidad de las decisiones basadas en pruebas A/B.
Definir objetivos sin calcular el tamaño de muestra es como intentar navegar sin una brújula: podés avanzar, pero no sabés si estás yendo en la dirección correcta. Si no determinás cuántos datos necesitás recolectar, las conclusiones de tu test pueden ser inexactas y llevarte a decisiones equivocadas.
El tamaño de muestra es clave para saber cuántos visitantes necesitás para identificar diferencias reales entre las variantes que estás probando. Si la muestra es demasiado pequeña, el test no solo desperdicia tiempo y recursos, sino que también puede generar resultados inútiles. Como bien lo explica Aulaformativa:
"Para poder llegar a conclusiones realmente precisas, necesitas un número considerable de personas. De lo contrario, se podría considerar las pruebas A/B como un recurso sin sentido."
Además, es importante asegurarte de que el tráfico durante el test sea representativo del comportamiento habitual de tus usuarios.
Para calcular el tamaño de muestra que necesitás, hay tres datos fundamentales que tenés que tener a mano:
Con estos datos, podés usar calculadoras online gratuitas que te indicarán cuántos visitantes necesitás por variante. Por ejemplo, si tu tasa de conversión actual es del 2% y querés identificar una mejora del 20% (es decir, llegar al 2,4%), el tamaño de muestra será mayor que si buscás detectar un cambio del 50%. Esto se debe a que, cuanto más pequeño sea el efecto que querés medir, mayor será el tamaño de muestra requerido.
Es importante que definas este número antes de iniciar el test y te comprometas a no sacar conclusiones ni detener el experimento antes de alcanzarlo. Uno de los errores más comunes y costosos es interrumpir un test prematuramente porque "parece que hay un ganador".
Una vez calculado el tamaño de muestra, podés estimar cuánto tiempo necesitarás para completar el test en función del tráfico de tu sitio. Como regla general, cualquier test debería ejecutarse durante al menos una semana completa, ya que esto permite capturar las variaciones naturales en el comportamiento de los usuarios a lo largo de la semana.
Si tu sitio tiene poco tráfico, el test deberá extenderse por más tiempo para alcanzar el tamaño de muestra necesario. Por ejemplo, si necesitás 10.000 visitantes por variante y tu sitio recibe solo 1.000 visitantes diarios (distribuidos equitativamente), el test deberá durar al menos 20 días.
Es importante incluir en tu planificación días de menor tráfico, para que los resultados reflejen de manera más completa el comportamiento de tu audiencia. La paciencia es clave: esperar hasta alcanzar el tamaño de muestra correcto es la única forma de asegurarte de que las decisiones que tomes estén basadas en datos sólidos y estadísticamente válidos.
Analizar datos sin haber definido segmentos previamente puede llevarte a encontrar patrones que no reflejan diferencias reales. Este error, conocido como "p-hacking", es especialmente peligroso porque puede hacerte creer que descubriste un ganador cuando, en realidad, solo estás observando ruido estadístico.
El problema radica en las matemáticas: cada segmento que analizás después del test funciona como una prueba estadística independiente. Por ejemplo, si evaluás 20 segmentos diferentes con un nivel de significancia del 5%, es probable que encuentres al menos un falso positivo, incluso si no hay diferencias reales en el rendimiento. Por eso, definir estos segmentos desde el inicio es tan importante como formular hipótesis claras. Esto asegura que cada análisis aporte información útil y confiable a tu estrategia.
Cuando revisás múltiples segmentos después de terminar el test, la probabilidad de identificar un "ganador" por pura casualidad aumenta considerablemente. Como se explicó en el Error 2, cada análisis adicional incrementa de forma exponencial el riesgo de falsos positivos.
El problema empeora si, además, revisás los resultados mientras el test está en curso y empezás a segmentar los datos para buscar un ganador. Esto no solo distorsiona la significancia estadística, sino que también disminuye la confiabilidad de los intervalos de confianza. Por ejemplo, si no definís segmentos preestablecidos como "usuarios nuevos vs. recurrentes", podrías confundir el efecto novedad (usuarios que responden al cambio solo porque es algo diferente) con una mejora real.
Para evitar los sesgos mencionados, es esencial planificar con anticipación. Antes de iniciar el test, definí claramente los segmentos que son relevantes para tu hipótesis. Algunos ejemplos pueden ser:
Comprometete a analizar únicamente esos segmentos predefinidos.
Si, durante el análisis, detectás un patrón en un segmento que no habías considerado, tratá ese hallazgo como una nueva hipótesis. Diseñá un test específico para ese segmento antes de sacar conclusiones. Además, si planeás evaluar varios segmentos u ofertas al mismo tiempo, aplicá la corrección de Bonferroni. Esto implica dividir el nivel de significancia (5%) entre la cantidad de comparaciones que vas a realizar, para mantener un nivel de confianza del 95% en el conjunto.
Definir los segmentos de audiencia antes de realizar un experimento es clave para mantener la rigurosidad del método científico. El proceso debe seguir este orden: primero la hipótesis, luego el experimento y, finalmente, el análisis de resultados. Esto no solo mejora la calidad de tus decisiones, sino que también evita caer en interpretaciones erróneas.
¿Querés simplificar tus pruebas A/B? Burbuxa facilita el proceso desde el inicio, ayudándote a establecer objetivos claros y alcanzables. Si trabajás con e-commerce en plataformas como WhatsApp e Instagram, esta herramienta puede ser clave para evitar problemas comunes y optimizar resultados.
Burbuxa reúne datos de ventas, soporte y marketing de plataformas como Shopify, Tiendanube y VTEX en un único panel de control. Esto te permite monitorear métricas clave en tiempo real, como el Valor Promedio de Pedido (AOV), tasas de conversión y el ROAS (retorno sobre inversión publicitaria), sin necesidad de cambiar de plataforma.
Además, al sincronizar inventarios, precios y pedidos en tiempo real, podés corregir errores técnicos al instante, asegurando que las pruebas A/B se basen siempre en datos actualizados. El módulo de Review Intelligence, por su parte, analiza miles de reseñas de clientes para identificar problemas en productos y priorizarlos según su impacto en las ventas. De esta manera, podés establecer objetivos fundamentados en datos reales y no en conjeturas.
Para minimizar desvíos y ajustes inesperados, Burbuxa automatiza las pruebas A/B con supervisión. Su módulo de Listing Optimization reescribe títulos y descripciones de productos utilizando el lenguaje de tus clientes, identifica las variaciones más efectivas y las aplica automáticamente (con tu aprobación previa si activás el modo supervisado). Esto puede generar un aumento de hasta un 28% en las conversiones.
| Función | Métrica principal | Beneficio comercial |
|---|---|---|
| Listing Optimization | Tasa de conversión / CTR | Incremento de ventas hasta 28% |
| Review Intelligence | Impacto potencial en ventas | Identifica mejoras basadas en feedback |
| Recuperación de carritos | Tasa de recuperación | Aumenta ventas recuperadas en 32% |
| Agentes de IA | Tasa de resolución | Resuelve automáticamente el 95% de consultas comunes |
Antes de activar el modo "Autopilot", revisá las variaciones sugeridas por la IA y aprobá manualmente los cambios. Esto asegura que mantengas el control sobre la identidad de tu marca mientras reducís el sesgo en las pruebas, garantizando que cada ajuste esté alineado con tus objetivos comerciales.
Cuando hablamos de definir objetivos en pruebas A/B, es clave diferenciar entre aquellos que generan datos útiles y los que solo conducen a errores estadísticos. Un objetivo claro te ayuda a calcular el tamaño de muestra necesario, determinar la duración adecuada del test y validar los resultados estadísticamente. En cambio, un objetivo poco definido dificulta saber cuándo finalizar la prueba y aumenta el riesgo de falsos positivos.
Por ejemplo, plantear un objetivo como "Mejorar la experiencia del usuario" no indica qué métrica medir ni qué resultado esperar. Por otro lado, un objetivo como "Reducir el abandono del formulario en un 10% simplificando el diseño del checkout" es específico, medible y cuantificable.
Otro error frecuente es centrarse en métricas proxy como el CTR (Click-Through Rate), que aunque permiten obtener resultados rápidamente, pueden llevar a conclusiones equivocadas si no están vinculadas directamente con los ingresos. Por ejemplo, no sirve de mucho aumentar el número de clics si estos no se convierten en ventas. Incluso podrías atraer más visitantes que no compran, afectando negativamente métricas importantes como el Valor Promedio de Pedido (AOV) o el Revenue per Visitor (RPV).
La siguiente tabla muestra cómo los objetivos bien definidos y específicos pueden marcar la diferencia en la validez y utilidad de un test A/B:
| Tipo de objetivo | Ejemplo | Impacto en tamaño de muestra | Impacto en validez del test |
|---|---|---|---|
| Mal definido (vago) | "Aumentar las ventas" | Imposible de calcular; fomenta "espiar" resultados hasta que parezcan favorables. | Alto riesgo de falsos positivos; no hay un criterio claro para detener la prueba. |
| Bien definido (específico) | "Lograr un 5% de mejora en recuperación de carritos vía automatizaciones de WhatsApp" | Permite calcular con precisión los visitantes necesarios según la línea base actual. | Alto; los resultados son estadísticamente sólidos y replicables. |
| Desalineado (métrica proxy) | "Maximizar el CTR del banner principal" | Requiere menos muestra debido al alto volumen de interacciones. | Bajo; puede generar "ganadores" que en realidad disminuyen los ingresos totales. |
| Accionable (centrado en el negocio) | "Aumentar el AOV en $500 mediante prompts de venta cruzada" | Requiere una muestra mayor debido a la varianza en los datos de compra. | Alto; mide directamente el impacto en la rentabilidad. |
Es importante recordar que los resultados confiables requieren un nivel de confianza del 95% y un poder estadístico del 80%. Estos estándares ayudan a evitar errores comunes, como detener el test prematuramente al primer indicio de significancia. De hecho, simulaciones en 100 tests muestran que esto puede triplicar la tasa de falsos positivos.
Tener objetivos claros y medibles convierte las pruebas A/B en herramientas confiables para tomar decisiones basadas en datos, evitando caer en interpretaciones erróneas.
Cada error que pase desapercibido puede comprometer la confiabilidad de los resultados. Por ejemplo, revisar los datos constantemente durante el test puede aumentar hasta tres veces la probabilidad de obtener falsos positivos. Además, enfocarse en métricas indirectas como el CTR puede llevar a elegir "ganadores" que, en realidad, terminen afectando la rentabilidad del negocio.
Los errores más comunes en las pruebas A/B, como hipótesis poco definidas, cambiar objetivos a mitad del test, no calcular el tamaño de muestra adecuado o analizar segmentos después de finalizado el experimento, tienen algo en común: una falta de planificación inicial. Para obtener resultados sólidos, es fundamental aislar variables, definir una métrica primaria alineada con los objetivos del negocio y mantener la prueba activa durante al menos una semana.
Herramientas como Burbuxa pueden ser de gran ayuda para evitar estos errores. Estas plataformas centralizan datos en tiempo real desde sistemas como Shopify, Tiendanube y VTEX, automatizan pruebas A/B en elementos como títulos y descripciones, y detectan posibles errores técnicos que podrían distorsionar los resultados.
Incluso un test que no cumpla con las expectativas iniciales puede ofrecer lecciones valiosas para ajustar futuras hipótesis. Lo esencial es definir desde el principio cuál será la métrica principal, calcular el tamaño de muestra necesario antes de empezar y no realizar cambios durante la prueba. Con esta metodología, las pruebas A/B se convierten en una herramienta estratégica para tomar decisiones basadas en evidencia.
Seleccionar la métrica principal adecuada para una prueba A/B es clave para obtener resultados claros y útiles. Esta métrica debe estar directamente relacionada con el objetivo principal de tu experimento y reflejar el impacto del cambio que estás evaluando.
Por ejemplo, si el objetivo es aumentar las conversiones en una tienda online, la métrica principal podría ser la tasa de conversión. Sin embargo, también es útil incluir métricas secundarias que te ayuden a entender mejor el contexto o los efectos secundarios del cambio, como el tiempo promedio en el sitio o el valor promedio por compra. Eso sí, estas métricas adicionales no deben desviar el foco de la principal.
Para garantizar resultados confiables:
Este enfoque te permitirá tomar decisiones basadas en datos sólidos y alineadas con tus metas.
Es recomendable detener un test A/B cuando se cumplen ciertos criterios clave: se alcanza una significancia estadística adecuada (generalmente del 95%), se logra recopilar una muestra representativa de datos, o se cumple el plazo establecido previamente. Si los resultados no muestran conclusiones claras o la muestra no es suficiente, lo ideal es continuar el test hasta contar con datos más sólidos antes de pasar a un nuevo experimento.
Antes de lanzar una prueba A/B, es fundamental tener bien definidos los segmentos específicos de tu audiencia y los elementos o productos que vas a evaluar. Esto te permitirá obtener datos más precisos sobre cómo reacciona cada grupo ante cambios en aspectos como precios, diseño o mensajes.
Además, es importante establecer objetivos claros desde el principio. Por ejemplo, si tu meta es aumentar las conversiones o los ingresos, tener esto en mente te ayudará a medir el éxito de la prueba y ajustar tus estrategias en consecuencia. De esta manera, podrás tomar decisiones informadas y maximizar los resultados basándote en datos concretos.