
Detectar problemas en los envíos antes de que se conviertan en quejas es clave para mejorar la experiencia del cliente. La inteligencia artificial (IA) permite identificar irregularidades como demoras, rutas alteradas o falta de actualizaciones en tiempo real, algo que sería imposible de gestionar manualmente, especialmente durante eventos de alta demanda como el Hot Sale.
Conectando fuentes de datos, estandarizándolos y configurando sistemas de IA, las marcas pueden reducir reclamos y anticiparse a problemas logísticos. Esto no solo mejora la confianza del cliente, sino que también optimiza la operación logística.
No todas las anomalías tienen el mismo impacto: algunas generan reclamos inmediatos, mientras que otras solo se detectan cuando el cliente ya perdió la paciencia. Identificarlas y clasificarlas según su relevancia es clave para construir un sistema de detección eficiente.
Entre las anomalías más frecuentes se encuentran:
"El sector logístico ha dejado de ser simplemente mover paquetes. Hoy implica tomar decisiones basadas en datos, anticipar la demanda y garantizar una experiencia de compra que cumpla con las expectativas del cliente." - Santiago Rey, CEO, WiGou
Para que los datos se conviertan en alertas útiles, es necesario establecer reglas claras. En Argentina, los tiempos de tránsito cambian según el transportista y la región. Por ejemplo, un envío dentro de la provincia de Buenos Aires tendrá plazos distintos a uno con destino a Neuquén o Misiones. Esto significa que los umbrales deben adaptarse a cada contexto.
| Tipo de anomalía | Umbral sugerido | Impacto operativo |
|---|---|---|
| Sin actualización de estado | Más de 24 hs sin escaneo | Alto |
| Demora respecto al SLA del transportista | Más de 48 hs sobre el plazo acordado | Alto |
| Desviación de ruta | Hub fuera del recorrido habitual | Medio |
| Reclamo por condición del paquete | Reporte de daño al recibir | Medio |
Estos umbrales deben ajustarse según los SLA (acuerdos de nivel de servicio) de cada operador. Lo que un transportista considera inaceptable, otro podría considerarlo dentro de lo normal.
El verdadero reto es decidir qué anomalías atender primero. El enfoque más efectivo combina el valor del pedido con el impacto en la experiencia del cliente. Por ejemplo, un envío de alto valor que lleva más de 48 horas sin actualizaciones requiere atención inmediata. En cambio, una pequeña demora en un pedido de bajo costo puede resolverse con una notificación automática.
La sensibilidad del algoritmo es crucial: una configuración alta detectará cualquier desviación, mientras que una baja solo señalará problemas graves. Se recomienda empezar con alta sensibilidad para identificar patrones y ajustar los umbrales con base en la operación real. Para pedidos VIP o de alto valor, configura escalamientos automáticos que envíen alertas de alto impacto directamente a un agente humano.
Con estas prioridades claras, el próximo paso es centralizar y estandarizar los datos de envío. Esto permitirá gestionar las anomalías de manera más efectiva y mejorar la experiencia del cliente.
Con las prioridades claras, el siguiente paso es reunir y centralizar los datos necesarios para que la IA pueda analizarlos de manera efectiva.
Los datos de envío no provienen de una única fuente. Estos suelen estar dispersos entre tu plataforma de e-commerce (como Shopify, Tiendanube o VTEX), las APIs de seguimiento de los transportistas y los canales de comunicación con los clientes, como WhatsApp e Instagram. Conectar estas tres fuentes es el primer paso.
Por ejemplo, Shopify y VTEX ofrecen webhooks y APIs que actualizan el estado de los envíos en tiempo real. Además, los logs de conversaciones con los clientes pueden ser fundamentales: un mensaje en WhatsApp informando que un paquete llegó dañado podría ser el primer indicio de un problema, incluso antes de que el transportista registre la incidencia en su sistema.
Una vez que estas fuentes están conectadas, es crucial estandarizar los datos para que puedan ser analizados sin inconvenientes.
Cada plataforma, transportista o canal tiene sus propias reglas y formatos. Para que la IA pueda realizar comparaciones y análisis precisos, todos los datos deben estar unificados bajo un mismo estándar.
Al trabajar en Argentina, hay ciertos formatos que conviene adoptar: fechas en el formato DD/MM/YYYY, horarios en sistema de 24 horas, y montos en pesos argentinos (ARS $), utilizando punto para separar miles y coma para decimales (por ejemplo, ARS $1.250,50). Los pesos de los paquetes deben registrarse en kilogramos. Además, para cumplir con la Ley 25.326, se recomienda usar cifrado AES-GCM (128 bits) y firma SHA256 en los endpoints.
Tras estandarizar los datos, se mapean los campos de cada plataforma a variables universales. Por ejemplo, {{order_id}} para identificar el pedido y {{shipment_status}} para el estado del envío. Este proceso asegura que la información de distintas fuentes se integre sin errores, creando una base sólida para seleccionar el dataset mínimo necesario.
Con los datos unificados y estandarizados, se puede construir un dataset básico que permita a la IA comenzar a identificar patrones y generar alertas. Este dataset debe incluir los siguientes campos:
| Campo | Descripción | Por qué importa |
|---|---|---|
| ID de envío/pedido | Código único alfanumérico | Vincula datos entre plataformas |
| Timestamp | Fecha y hora del evento (DD/MM/YYYY HH:mm) | Ayuda a detectar demoras y calcular tiempos de tránsito |
| Estado actual | Ej.: Despachado, En tránsito, Demorado | Identifica desvíos en el flujo esperado |
| Transportista | Nombre del operador logístico | Permite detectar problemas específicos de cada proveedor |
| Destino (ciudad/CP) | Ubicación de entrega del cliente | Señala problemas regionales |
| Monto en ARS | Valor total del envío | Prioriza alertas más relevantes |
Con este conjunto de datos, la IA tiene suficiente información para empezar a detectar irregularidades y generar alertas que realmente aporten valor.
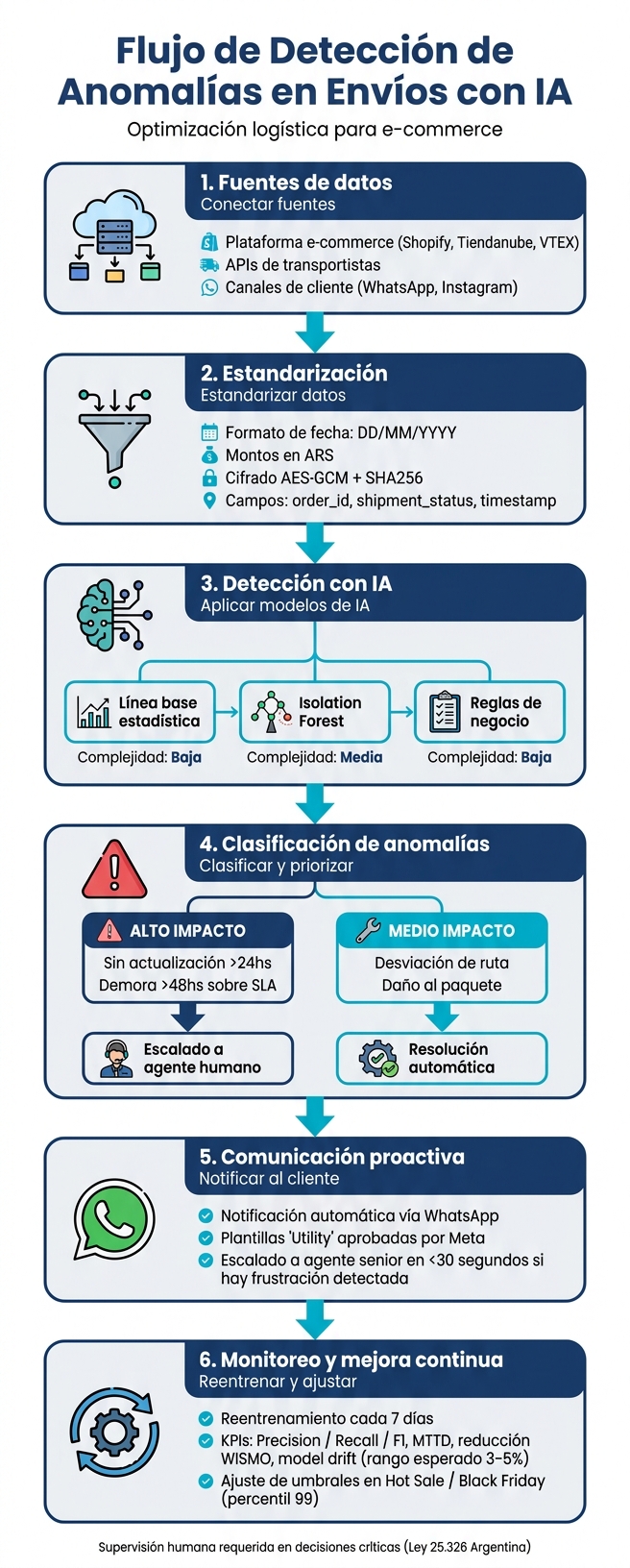
Cómo detectar anomalías en envíos con IA: flujo completo
Con los datos ya unificados, el siguiente paso es configurar el procesamiento con inteligencia artificial. Ningún método por sí solo puede garantizar resultados perfectos, así que lo ideal es combinar enfoques según el tipo de anomalía que se busque identificar.
Los modelos estadísticos de línea base son una herramienta sencilla para determinar el comportamiento "normal" de los envíos. Por ejemplo, pueden calcular el tiempo promedio de tránsito dentro del país y generar alertas cuando un envío se desvía de ese rango esperado. Su facilidad de implementación y claridad los hacen ideales para equipos que recién comienzan con estas tecnologías.
El Isolation Forest, un algoritmo de machine learning, es especialmente eficaz para detectar valores atípicos en grandes volúmenes de datos. Este modelo aprende a identificar lo que es "normal" y aísla automáticamente los casos fuera de lo común, sin necesidad de establecer reglas predefinidas.
Por otro lado, las reglas de negocio son útiles para complementar los modelos estadísticos con criterios deterministas. Un ejemplo sería: "si un envío lleva más de 72 horas sin actualizar su estado, clasificarlo como crítico". Estas reglas son muy prácticas cuando el criterio es claro y no deja margen para interpretaciones.
| Método | Ideal para | Complejidad de implementación |
|---|---|---|
| Línea base estadística | Detectar demoras respecto al promedio histórico | Baja |
| Isolation Forest | Identificar outliers en grandes volúmenes | Media |
| Reglas de negocio | Verificaciones claras y automáticas | Baja |
En conjunto, estos métodos crean un sistema robusto: los modelos detectan lo inesperado, mientras que las reglas abordan situaciones definidas. Esta combinación asegura una cobertura integral de las anomalías más relevantes.
El sistema procesa actualizaciones en tiempo real provenientes de las plataformas, analizando cada cambio en el estado de los envíos. La IA contrasta esos eventos con los modelos configurados y genera alertas si detecta irregularidades.
Es fundamental definir pasos claros para manejar estas alertas. Por ejemplo, las anomalías que afectan a múltiples pedidos o a clientes VIP deben ser escaladas de inmediato a un agente humano, quien contará con el historial completo del caso. Las alertas de menor impacto, en cambio, pueden resolverse automáticamente. Este flujo de escalado supervisado garantiza que las decisiones críticas pasen por una revisión humana, evitando errores graves. Este enfoque integrado conecta la detección con una respuesta rápida y precisa.
Burbuxa cierra el ciclo de respuesta automatizada al integrar la detección de anomalías con canales de comunicación como WhatsApp e Instagram. Esto permite enviar notificaciones automáticas y gestionar alertas escaladas de manera eficiente.
Por ejemplo, si el sistema detecta una demora o un problema en el estado de un envío, Burbuxa envía una actualización proactiva al cliente a través de WhatsApp, utilizando plantillas "Utility" aprobadas por Meta. Esto evita que el cliente tenga que preguntar primero. Además, si el análisis de sentimiento identifica frustración en un mensaje entrante - con frases como "no llegó nada" o "es un desastre" - , el caso se escala en menos de 30 segundos a un agente senior, quien recibe todo el contexto del pedido.
El agente Estratega de Burbuxa también analiza todas las conversaciones de forma transversal, detectando patrones que los dashboards tradicionales no logran captar. Por ejemplo, si en las últimas semanas aumentaron los reclamos por demoras en una provincia específica, el sistema genera una recomendación concreta para ajustar las políticas logísticas.
Un sistema de detección de anomalías no es algo que se configura una vez y se deja correr sin supervisión. Las operaciones de los transportistas cambian, surgen nuevos patrones estacionales y el comportamiento de los envíos evoluciona constantemente. Sin una revisión periódica, el sistema puede empezar a generar falsas alarmas o, peor aún, ignorar problemas reales.
Cada anomalía detectada debe ser tratada como una oportunidad para aprender. Es fundamental registrar cada alerta, su resolución y las acciones tomadas. Con este historial, el modelo debe ser reentrenado regularmente, idealmente cada 7 días, o de inmediato si se producen cambios operativos importantes.
Cuando prepares los datos de entrenamiento, asegurate de excluir períodos que incluyan incidentes conocidos, como paros de transportistas o fallas en los sistemas, para evitar que el modelo los interprete como normales. Durante eventos de alta demanda, como el Hot Sale o el Black Friday, es útil ajustar los umbrales a valores más altos (por ejemplo, el percentil 99) para evitar una sobrecarga de alertas.
Estos ajustes no solo mejoran el desempeño del sistema, sino que también se reflejan en métricas clave que ayudan a medir su efectividad.
Para validar los ajustes y el reentrenamiento, es esencial analizar indicadores clave que reflejen tanto la precisión técnica como el impacto en el negocio:
| Categoría | Indicador clave | Qué mide |
|---|---|---|
| Precisión del modelo | Precision / Recall / F1 | Equilibrio entre falsas alarmas y anomalías no detectadas |
| Velocidad | Tiempo medio de detección (MTTD) | Tiempo que tarda el sistema en identificar un problema |
| Impacto en clientes | Reducción de consultas WISMO | Disminución de consultas como "¿dónde está mi pedido?" en soporte |
| Salud del modelo | Tasa de deriva (model drift) | Si la tasa de anomalías se desvía del rango esperado (3–5%) |
Un ejemplo práctico: optimizar los parámetros de un modelo puede reducir la tasa de falsos positivos casi a la mitad, pasando del 53,6 % al 27,8 %. Esto significa menos interrupciones para los equipos de soporte y mayor confianza en las alertas generadas.
"Elige el sistema con la menor tasa posible de falsos positivos. Si esa tasa es demasiado alta, los usuarios apagarán el sistema ya que distrae más de lo que ayuda." - Julia Bohutska, Data Scientist, Towards Data Science
Además de las métricas, la validación humana sigue siendo clave para garantizar que cada alerta se gestione de manera correcta.
Después de ajustar y evaluar el modelo, la supervisión humana es esencial para garantizar decisiones precisas. La automatización no elimina la necesidad de intervención humana, sino que cambia su enfoque. Para decisiones críticas - como autorizar un reenvío o iniciar un reclamo con el transportista - lo ideal es usar un modo supervisado, donde la IA sugiere una acción, pero un agente humano debe aprobarla antes de ejecutarla.
También es fundamental mantener un registro de auditoría de cada detección y acción automatizada. Esto no solo es una buena práctica, sino que en Argentina es obligatorio bajo la Ley 25.326 de Protección de Datos Personales cuando se procesan datos de clientes mediante flujos automatizados. Este registro facilita la revisión de la lógica detrás de cada alerta y permite ajustar reglas que ya no reflejan el comportamiento actual de los transportistas.
| Componente de gobernanza | Función | Rol humano |
|---|---|---|
| Modo supervisado | La IA sugiere la resolución para anomalías de alto costo | Aprobar o rechazar la acción |
| Registro de auditoría | Documenta cada detección y mensaje automatizado | Revisión periódica para garantizar el cumplimiento |
| Disparadores de escalado | Transfiere anomalías complejas a una cola gestionada por humanos | Resolución directa y manejo de casos complejos |
| Cadenas de razonamiento | Muestra la lógica detrás de cada alerta | Validación y corrección del modelo |
Como bien lo expresa Burbuxa: "La aprobación es el precio de la confianza". Permitir que un sistema actúe sin control humano en situaciones críticas puede generar más problemas de los que resuelve.
Detectar anomalías en envíos con inteligencia artificial no es algo que se hace una sola vez. Es un proceso constante que combina datos consolidados, modelos bien diseñados y supervisión continua. Esta mezcla de automatización y control humano asegura que la IA identifique problemas, mientras el equipo toma decisiones sobre cómo solucionarlos. Así, se evita una avalancha de alertas innecesarias y errores que solo se descubren cuando llegan las quejas.
Además, herramientas como Burbuxa cierran el círculo. Cuando el sistema detecta una anomalía, se activa de inmediato la comunicación con el cliente. Los flujos automatizados en WhatsApp notifican de manera proactiva, responden preguntas frecuentes como "¿dónde está mi pedido?" sin necesidad de intervención humana y, en casos más complejos, transfieren la consulta a un agente con toda la información necesaria.
¿El resultado? Menos consultas al soporte, mayor confianza por parte de los clientes y operaciones más organizadas. No necesitas un equipo especializado en ciencia de datos: con los datos que ya tienes, una revisión semanal y ajustes constantes, puedes lograrlo.
Sin estos datos, la IA no puede operar de manera adecuada ni ofrecer resultados confiables.
Para optimizar la detección de anomalías, es clave configurar límites específicos en tu sistema de monitoreo. Esto implica establecer parámetros personalizados que se ajusten a las variaciones normales de cada transportista y región. Por ejemplo, considera factores como los tiempos de entrega, los volúmenes manejados y otros indicadores clave de desempeño.
Al ajustar estos umbrales, podrás identificar desviaciones importantes con mayor precisión y adaptarte mejor a las condiciones particulares de cada contexto. Esto no solo mejora la detección, sino que también reduce los falsos positivos, ahorrando tiempo y recursos en la gestión de alertas.
Para reducir los falsos positivos sin dejar de identificar anomalías auténticas, es clave afinar los modelos de IA con estrategias específicas. Una de ellas es la ingeniería de características temporales, que permite incorporar datos sobre el comportamiento a lo largo del tiempo. Esto ayuda a los modelos a distinguir entre patrones normales y actividades sospechosas.
Otra técnica útil es el análisis de patrones de comportamiento. Este enfoque permite identificar tendencias o irregularidades que podrían pasar desapercibidas con métodos más simples. Además, los modelos híbridos, que combinan inteligencia artificial con la revisión humana, son una excelente manera de aumentar la precisión en la detección.
También es fundamental ajustar los umbrales de detección. Un umbral demasiado bajo puede generar demasiados falsos positivos, mientras que uno muy alto podría pasar por alto actividades importantes. Por último, realizar pruebas continuas asegura que los modelos se mantengan calibrados, mejorando la relevancia y precisión de las alertas.